

Bevezetés a kaptár telepítésébe
A Kaptár telepítése során a telepítés előtt meg kell tenni néhány előfeltételt.
Az olyan Hadoop komponensek, mint a Hive, Hbase, Pig stb. Támogatják a Linux környezetet. Ezért javasolt, hogy a készüléken legyen Linux operációs rendszer. Ha nem erről van szó, és a kaptárban szeretne gyakorolni, miközben a Windows rendelkezik a rendszerrel. Amit tehet, telepítse a CDH-gépet a rendszerére, és platformként használja fel a Hadoop felfedezéséhez. Ehhez legalább 4 GB RAM szükséges a rendszeren, vagy van egy CDH-gépe a tollmeghajtóban, és használhatja.
Mindenesetre bármikor megoldást találhat kérdésére, talán hamarabb, mint később.
A kaptár telepítésének előfeltételei
Van néhány előfeltétel a kaptár telepítéséhez bármely gépen:
- Java telepítés
- Hadoop telepítés
1. lépés
- Ellenőrizze, hogy a Java telepítve van-e.
- Nyissa meg a terminált és írja be a parancsot.
Java-verzió
- Ha a Java telepítve van a rendszerre, akkor a verzió jelenik meg, különben hiba lép fel. Esettemben a Java már telepítve van, és az alábbiakban látható a parancs kimenete.

- Ha a Java nincs telepítve a rendszerében. Látogasson el az alábbi linkre, és töltse le a Java-t, és telepítse.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Java telepítés
- Bontsa ki a letöltött fájlt.
- Vigye a „/ usr / local /” mappába.
- Állítsa be a PATH és a JAVA_HOME változókat.
2. lépés
- Ellenőrizze, hogy a Hadoop telepítve van-e.
- Nyissa meg a terminált, és írja be a parancsot.
Hadoop-Version
- Ha a Hadoop már telepítve van, akkor ez a parancs adja meg a verziót, vagy pedig hibát jelez.
- Az én esetemben a Hadoop már telepítette az alábbi kimenetet.
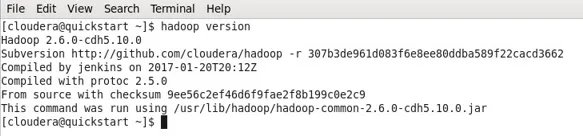
- Most megfigyelheted, hogy CDH5 gépen dolgozom.
- Ha a Hadoop nincs telepítve, töltse le a Hadoop fájlt az Apache szoftverből.
Hadoop telepítés
1. A Hadoop telepítése
2. Konfigurálja a Hadoop alkalmazást
A Hadoop konfigurálásához szerkeszteni kívánt fájlok a következők:
- mag-site.xml
- hdfs-site.xml
- fonal site.xml
- mapred-site.xml
3. A Namenode beállítása a következő paranccsal:
Hdfs namenode -format
4. Indítsa el a dfs-t a következő paranccsal:
start -dfs.sh
5. Indítsa el a fonalat a következő paranccsal:
Start -yarn.sh
Hogyan lehet telepíteni a kaptárt?
A pontok alatt segít a kaptár telepítésében:
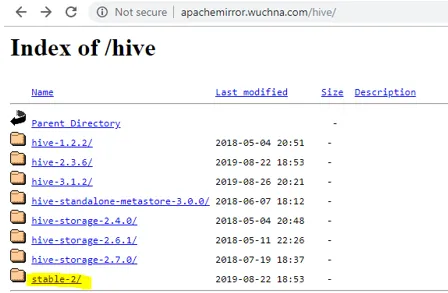
- Az első lépés, hogy le kell töltenünk a kaptár kiadását, amely az alábbi linkre kattintva hajtható végre: http://apachemirror.wuchna.com/hive/
- A fenti link megadja azt a linket, amelyből a Stabil-2-et kell választani, az alább sárga színben kiemelve:
- A stabil-2 megnyitása után válassza ki a bin fájlt (a képernyőképen sárga kiemeléssel), majd kattintson a jobb gombbal és a „link link address copy” elemre.
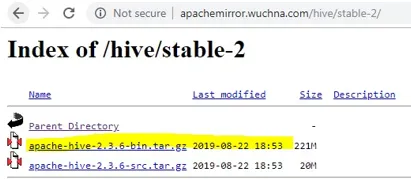
A kaptár telepítésének lépései
Az alábbiakban bemutatjuk a kaptár telepítésének lépéseit:
1. lépés: Töltse le a tar fájlt.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
2. lépés: Bontsa ki a fájlt.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
3. lépés: Helyezze át az apache fájlokat az / usr / local / kaptár könyvtárba.
sudo mv /usr/local/apache-hive-* /usr/local/hive
4. lépés: Állítsa be a Hive környezetet a következő sorok hozzáfűzésével a ~ / .bashrc fájlhoz
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
5. lépés: Végezze el a bashrc fájlt.
$ source ~/.bashrc
6. lépés: Kaptárkonfiguráció - Szerkessze a hive-env.sh fájlt ehhez:
export HADOOP_HOME=/usr/local/Hadoop
7. lépés: Szerkesztés az alábbi parancsok segítségével:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Most ellenőrizze, hogy a kaptár telepítve van-e vagy sem, használja a kaptár-verzió parancsot.
- Itt a kaptár verzió belép a kaptárhéjba, ami azt jelenti, hogy a kaptár telepítve van. Az én esetemben azonban ez a régebbi verzió, ezért figyelmeztetést ad.

Következtetés - Kaptár telepítése
A Hive sok ember számára nyitja meg a nagy adatot, könnyebbége és hasonló jellege miatt, mint az SQL, például a lekérdezési nyelv és az interfészek. A Hive a Hadoop magjára épül, mivel a Mapreduce-t használja a végrehajtáshoz. Nagyon egyszerű az adatok beolvasása és a Big Data feldolgozása.
Ajánlott cikkek
Ez egy útmutató a kaptár telepítéséhez. Itt tárgyalunk néhány előfeltételt a kaptár telepítéséhez bármilyen gépen, valamint a kaptár telepítésének lépéseit a jobb megértés érdekében. Megnézheti más kapcsolódó cikkeinket, hogy többet megtudjon-
- Mi a kaptár?
- Kaptárparancsok
- Hogyan lehet telepíteni a kaptárt
- Mi az a sertés?