

Különbség a MapReduce és a Spark között
A Map Reduce egy nyílt forráskódú keret az adatok HDFS-be történő írására, valamint a HDFS-ben lévő strukturált és strukturálatlan adatok feldolgozására. A Map Reduce csak a kötegelt feldolgozásra korlátozódik, és a többi Spark bármilyen típusú feldolgozást képes elvégezni. A SPARK egy független feldolgozó motor valós idejű feldolgozáshoz, amely telepíthető bármilyen elosztott fájlrendszerre, például a Hadoop-ra. A SPARK olyan teljesítményt nyújt, amely tízszer gyorsabb, mint a Map Reduce a lemezen, és 100-szor gyorsabb, mint a Map Reduce a memóriában lévő hálózaton.
Need for SPARK
- Iteratív elemzés: A térképcsökkentés nem olyan hatékony, mint a SPARK, hogy megoldja az iteratív elemzést igénylő problémákat, mivel minden iterációhoz lemezre kell mennie.
- Interaktív elemzés: A Map-redukciót gyakran használják olyan ad-hoc lekérdezések futtatásához, amelyekre a lemezes memóriába kell jutni, ami szintén nem olyan hatékony, mint az SPARK, mivel ez utóbbi a memóriában hivatkozik, amely gyorsabb.
- Nem megfelelő OLTP-hez: Mivel a kötegeltorientált kereten működik, nem alkalmas nagyszámú rövid tranzakcióhoz.
- Nem alkalmas grafikonra: Az Apache Graph könyvtár feldolgozza azt a grafikont, amely összetettebbé teszi a Map Reduce funkciót.
- Nem alkalmas triviális műveletekhez: Olyan műveletekhez, mint a szűrő és a csatlakozás, szükség lehet a feladatok átírására, ami a kulcsérték-minta miatt összetettebbé válik.
A MapReduce és a Spark összehasonlítása fejről fejre (Infographics)
Az alábbiakban látható a top 15 különbség a MapReduce és a Spark között

Főbb különbségek a MapReduce és a Spark között
Az alábbiakban felsoroljuk a pontok listáját, írjuk le a MapReduce és a Spark közötti főbb különbségeket:
- A Spark valós időben használható, mivel a memóriában használja fel a feldolgozást, míg a MapReduce csak kötegelt feldolgozásra korlátozódik.
- A Sparknak RDD (Resilient Distributed Dataset) van, amely magas szintű operátorokat biztosít számunkra, de a Map redukcióban minden egyes műveletet kódolni kell, ami viszonylag nehézkes.
- A Spark grafikonokat dolgozhat fel, és támogatja a gépi tanulási eszközt.
- Az alábbiakban bemutatjuk a különbséget a MapReduce és a Spark ökoszisztéma között.
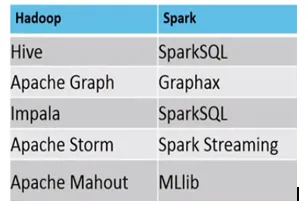
A következő példák, amelyekben a MapReduce vs Spark alkalmazhatók
Spark: Hitelkártya-csalások észlelése
MapReduce: Rendszeres jelentések készítése, amelyek döntést igényelnek.
MapReduce vs Spark összehasonlító táblázat
| Az összehasonlítás alapja | MapReduce | Szikra |
| Keretrendszer | Nyílt forráskódú keret az adatok HDFS-be történő írására és a HDFS-ben található strukturált és strukturálatlan adatok feldolgozására. | Nyílt forráskódú keret a gyorsabb és általános célú adatfeldolgozáshoz |
| Sebesség | Térkép-Csökkentse az adatok feldolgozását (olvasását és írását) a lemezről, így a szivárgás lassú a Sparkhoz képest. | A Spark legalább 10X gyorsabb a lemezen és 100X gyorsabb a memóriában, mint a Map Reduce. |
| Nehézség | Minden folyamatot kódolni / kezelni kell. | Az RDD (Resilient Distributed Dataset) elérhetőségével könnyen programozható. |
| Valós idő | Nem alkalmazható OLTP tranzakciókhoz csak kötegelt módban | Meg tudja kezdeni a valós idejű feldolgozást. A SPARK streaming használata. |
| Késleltetés | Magas szintű késleltetési számítási keret | Alacsony szintű késleltetéses számítási keretrendszer. |
| Hibatűrés | A démonok ellenőrzik a szolga démonok pulzusát, és ha a szolga démonok nem működnek, a démonok átalakítják az összes függőben lévő és folyamatban lévő műveletet egy másik rabszolgára. | Az RDD-k hibatűrést biztosítanak a SPARK ellen. A külső tárolóban (például HDFS, HBase) található adatkészletre vonatkoznak, és párhuzamosan működnek. |
| Scheduler | A Map Reduce alkalmazásban olyan külső ütemezőt használunk, mint az Oozie. | Mivel a SPARK a memórián belüli számítástechnikával működik, saját ütemezőjeként működik. |
| Költség | A Map Reduce viszonylag olcsóbb a SPARK-hoz képest. | Mivel a memóriában működik, ezért sok RAM-ot igényel, ami viszonylag költségesebbé teszi. |
| Platform kifejlesztve | A Map Reduce Java használatával került kifejlesztésre. | A SPARK-ot a Scala segítségével fejlesztették ki. |
| Támogatott nyelv | A Map Reduce alapvetően támogatja a C, C ++, Ruby, Groovy, Perl, Python fájlokat. | A Spark támogatja a Scala, Java, Python, R, SQL fájlokat. |
| SQL támogatás | A Map Reduce lekérdezéseket futtat a Hive Query Language használatával. | A Sparknak saját lekérdezési nyelve, a Spark SQL néven ismert. |
| skálázhatóság | A Map Reduce alkalmazásban akár n csomópontot is felvehetünk. A legnagyobb Hadoop klaszter 14000 csomóponttal rendelkezik. | A Spark-ban n számú csomópontot is hozzáadhatunk. A legnagyobb Spark-klaszternek 8000 csomópontja van. |
| Gépi tanulás | A Map Reduce támogatja az Apache Mahout eszközt a gépi tanuláshoz. | A Spark támogatja az MLlib eszközt a gépi tanuláshoz. |
| gyorsítótárral | A Map csökkentés nem képes gyorsítótárazni a memória adatait, így a Sparkhoz képest nem olyan gyors. | A Spark a memóriában tárolt adatokat a további iterációkhoz gyorsítótárazza, így nagyon gyors, mint a Map Reduce. |
| Biztonság | A Map Reduce a Sparkhoz képest több biztonsági projektet és szolgáltatást támogat | A szikrabiztonság még nem érett, mint a Map Reduce |
Következtetés - MapReduce vs Spark
A MapReduce és a Spark közötti fenti különbségtételt illetően elég egyértelmű, hogy a SPARK a Map Reduce-hez képest sokkal fejlettebb számítástechnikai motor. A Spark bármilyen típusú fájlformátummal kompatibilis, és szintén meglehetősen gyorsabb, mint a Map Reduce. A szikra ezen felül gráffeldolgozó és gépi tanulási képességekkel is rendelkezik.
Egyrészt a Map Reduce csak a kötegelt feldolgozásra korlátozódik, másrészt a Spark bármilyen típusú feldolgozást képes végrehajtani (kötegelt, interaktív, iteratív, streaming, grafikon). A nagy kompatibilitás miatt a Spark az Data Scientist kedvence, ezért helyettesíti a Map Reduce alkalmazást, és gyorsan növekszik. De mégis az adatokat HDFS-ben kell tárolnunk, és néha szükség lehet a HBase-re is. Tehát mind a Spark, mind a Hadoop futtatásához a legjobbat kell elérnünk.
Ajánlott cikkek:
Ez egy útmutató a MapReduce vs Spark, azok jelentésének, a fej-fej összehasonlításnak, a legfontosabb különbségeknek, az összehasonlító táblázatnak és a következtetésnek. A következő cikkeket is megnézheti további információkért -
- 7 fontos dolog az Apache Spark-ról (útmutató)
- Hadoop vs Apache Spark - Érdekes dolgok, amelyeket tudnod kell
- Apache Hadoop vs Apache Spark | A tíz legjobb összehasonlítás, amit tudnod kell!
- Hogyan működik a MapReduce?
- Technológiai és üzleti elemzések összefolyása