

Bevezetés az adattudományi technikákba
A mai világban, ahol az adatok új aranyak, különféle elemzések érhetők el egy vállalkozás számára. Az adattudományi projekt eredménye nagyban különbözik a rendelkezésre álló adatok típusától, ezért a hatás szintén változó. Mivel sokféle elemzés érhető el, feltétlenül szükséges megérteni, hogy néhány alapvonal-technikát ki kell választani. Az adattudományi technikák alapvető célja nemcsak a releváns információk keresése, hanem a gyenge kapcsolatok felismerése is, amelyek a modell rossz teljesítményéhez vezetnek.
Mi az adattudomány?
Az adattudomány olyan terület, amely több tudományterületen terjed. Magában foglalja a tudományos módszereket, folyamatokat, algoritmusokat és rendszereket az ismeretek összegyűjtésére és az azonos munkára. Ez a mező számos műfajt foglal magában, és a statisztika, az adatelemzés és a gépi tanulás fogalmainak egységesítésének közös platformja. Ebben a statisztikai elméleti ismeretek, valamint a gépi tanulás valós idejű adatai és technikái együtt járnak a vállalkozás gyümölcsöző eredményeinek elérése érdekében. Az adattudományban alkalmazott különböző technikák alkalmazásával a mai világban jobb döntést hozhatunk, amely egyébként hiányozhat az emberi szemről és elméről. Ne feledje, hogy a gép soha nem felejti el! Az adatközpontú világban a profit maximalizálása érdekében az adattudomány varázsa szükséges eszköz.
Különböző típusú tudományos technika
A következő néhány bekezdésben megismerjük az összes többi projektben alkalmazott általános tudományos technikákat. Noha az adattudomány technika néha üzleti probléma-specifikus lehet, és nem feltétlenül tartozik az alábbi kategóriákba, teljesen rendben van, ha különféle típusnak nevezzük. Magas szinten megosztjuk a technikákat Felügyelt (tudjuk a célhatást) és Felügyelet nélküli (Nem tudunk arról a célváltozóról, amelyet meg akarunk elérni). A következő szinten a technikákat fel lehet osztani
- Az az eredmény, amelyet megkapunk, vagy mi az üzleti probléma szándéka
- A felhasznált adatok típusa.
Először nézzük meg a szándékon alapuló szegregációt.
1. Nem felügyelt tanulás
- Anomália észlelése
Az ilyen típusú technikákban azonosítunk minden váratlan eseményt a teljes adatkészletben. Mivel a viselkedés eltér az adatok valós eseményétől, az alapul szolgáló feltételezések a következők:
- Ezen esetek száma nagyon ritka.
- A viselkedésbeli különbség szignifikáns.
Anomáliás algoritmusokat magyaráznak, mint például az Isolation Forest, amely pontszámot ad az adatkészlet minden egyes rekordjának. Ez az algoritmus faalapú modell. Az ilyen típusú felismerési technika és népszerűsége alapján ezeket különféle üzleti esetekben használják, például weblap-nézeteknél, áthaladási aránynál, kattintásonkénti bevételnél stb. Az alábbi grafikonon elmagyarázhatjuk, hogy néz ki az anomália.
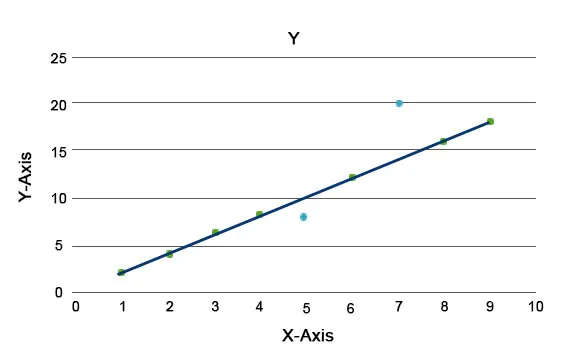
Itt a kék színű rendellenességet jelentenek az adatkészletben. Ezek különböznek a szokásos trendvonalaktól, és ritkábban fordulnak elő.
- Klaszterelemzés
Ezen elemzésen keresztül a fő feladat az, hogy a teljes adatkészletet szétválasztjuk csoportokra úgy, hogy az egyik csoport adatpontjában a tendencia vagy a tulajdonságok meglehetősen hasonlóak legyenek egymáshoz. Az adattudományi terminológiában ezeket klaszternek nevezzük. Például a kiskereskedelemben tervek vannak az üzlet méretarányára, és elengedhetetlen tudni, hogy az új ügyfelek hogyan viselkednének egy új régióban, a múltbeli adatok alapján. Lehetetlenné válik egy stratégia kidolgozása a populáció minden egyes egyénére, de hasznos lesz a populációt csoportokra osztani, hogy a stratégia egy csoportban eredményes legyen és méretezhető.
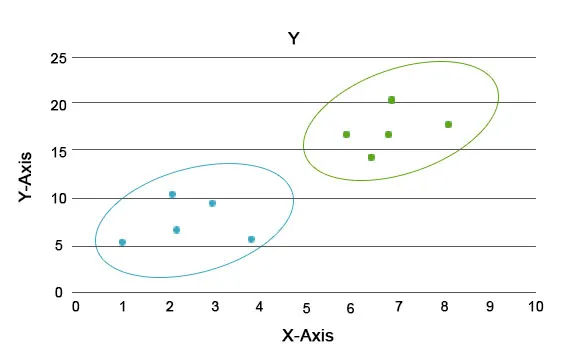
A kék és a narancssárga szín itt különféle klaszterek, amelyek egyedi vonásokkal rendelkeznek magukban.
- Asszociációs elemzés
Ez az elemzés segít nekünk az érdekes kapcsolatok kiépítésében egy adatkészlet tételei között. Ez az elemzés feltárja a rejtett kapcsolatokat, és segítséget nyújt az adatkészlet elemek ábrázolásában társítási szabályok vagy gyakori elemek halmaza formájában. Az asszociációs szabály két lépésre oszlik:
- Gyakori elemkészlet: Ebben a sorozatban generálódik a gyakran előforduló elemek együttes beállítása.
- Szabály generálás: A fent felépített halmazt a szabályok kialakításának különböző rétegein haladnak át, hogy rejtett kapcsolatot építsenek ki egymás között. Például, a készlet beleférhet akár fogalmi, akár végrehajtási kérdésekbe vagy alkalmazásproblémákba. Ezeket azután elágazik a megfelelő fákban az társulási szabályok kidolgozása érdekében.
Például, az APRIORI egy asszociációs szabály-felépítő algoritmus.
2. Felügyelt tanulás
- Regresszió analízis
A regressziós elemzés során a függõ / célváltozót és a fennmaradó változókat független változóként definiáljuk, és végül feltételezzük, hogy egy / több független változó hogyan befolyásolja a célváltozót. Az egy független változóval történő regressziót egyváltozósnak és többnél többváltozósnak nevezzük. Megértjük az egyváltozós felhasználást, majd a többváltozós skálát.
Például, y a célváltozó, és x 1 a független változó. Tehát az egyenes ismerete alapján az egyenletet y = mx 1 + c formában írhatjuk. Itt az „m” határozza meg, hogy az y milyen erősen befolyásolja x 1-t . Ha az „m” nagyon közel áll nullához, ez azt jelenti, hogy az x 1 változásával az y erősen nem befolyásolja. Az 1-nél nagyobb számnál a hatás erősebbé válik, és az x 1 kis változása nagy változásokhoz vezet y-ben. Az egyváltozóshoz hasonlóan a többváltozós formában y = m 1 x 1 + m 2 x 2 + m 3 x 3 ……… formában írhatjuk, itt minden egyes független változó hatását a megfelelő „m” határozza meg.
- Osztályozási elemzés
A klaszterelemzéshez hasonlóan az osztályozási algoritmusok is felépülnek, amelyeknek a célváltozója osztályok formájában van. A csoportosítás és az osztályozás közötti különbség abban rejlik, hogy a csoportosulás során nem tudjuk, melyik csoportba tartoznak az adatpontok, míg a besorolás során tudjuk, melyik csoporthoz tartozik. És a regressziótól abban a tekintetben különbözik, hogy a csoportok számának rögzített számnak kell lennie, ellentétben a regresszióval, ez folyamatos. Van egy csomó algoritmus az osztályozás elemzésében, például támogató vektorgépek, logisztikus regresszió, döntési fák stb.
Következtetés
Összegzésként megértjük, hogy az elemzés minden típusa önmagában hatalmas, ám itt kis különféle ízekkel szolgálhatunk a különféle technikákhoz. A következő néhány megjegyzésben külön-külön vesszük őket, és részletesebben megvizsgáljuk az egyes szülői technikákban alkalmazott különféle altechnikákat.
Ajánlott cikk
Ez egy útmutató az adattudományi technikákhoz. Itt tárgyaljuk az adattudomány bevezetését és a technikák különféle típusait. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Adattudományi eszközök A 12 legfontosabb eszköz
- Adattudományi algoritmusok típusokkal
- Bevezetés az adattudomány karrierjébe
- Data Science vs Data Visualization
- Példák a többváltozós regresszióra
- Hozzon létre döntési fát az előnyökkel
- Az adattudomány életciklusának rövid áttekintése