

Különbségek a Sqoop és a Flume között
A Sqoop az Apache szoftver terméke. Az Sqoop hasznos információkat von ki a Hadoopból, majd továbbítja azokat a külső adattárolókhoz. Az Sqoop segítségével az RDBMS-ből vagy a nagygépről adatokat importálhatunk a HDFS-be. A Flume szintén Apache szoftverből származik. Összegyűjti és mozgatja a generált rekurzív adatokat. Az Apache Flume nemcsak a naplóadatok összesítésére korlátozódik, hanem az adatforrások testreszabhatók, így a Flume felhasználható hatalmas mennyiségű adat továbbítására. A nagy mennyiségű adat gyűjtésének, összesítésének és áthelyezésének a legjobb módja a Hadoop elosztott fájlrendszere és az RDBMS között az olyan eszközök használata, mint például a Sqoop vagy a Flume.
Beszéljük meg ezt a két, a fent említett célra általánosan használt eszközt.
Mi a Sqoop?
Az Sqoop használatához a felhasználónak meg kell adnia a használni kívánt eszköz felhasználót és az argumentumokat, amelyek az adott eszközt vezérlik. Ezután az adatokat is exportálhatja egy RDBMS-be az Sqoop használatával. Az Sqoop exportfunkciói hasznos információk kinyerésére szolgálnak a Hadoopból, és exportálják azokat a külső strukturált adattárakba. Különböző adatbázisokkal működik, mint például a Teradata, a MySQL, az Oracle, a HSQLDB.
- Sqoop építészet: -
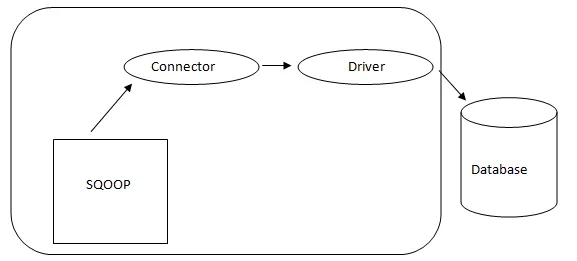
A Sqoop építészete
Az Sqoop csatlakozója egy adott adatbázis-forrás beépülője, ezért alapvető fontosságú, hogy ez egy Sqoop létesítmény része legyen. Annak ellenére, hogy az illesztőprogramok adatbázis-specifikus darabok és különböző adatbázis-gyártók terjesztik őket, maga az Sqoop különféle típusú csatlakozókkal van ellátva, amelyeket az elterjedt adatbázis- és információraktári rendszerekhez használnak. Így a Sqoop vegyes csatlakozási lehetőségekkel is szállít a dobozból. A Sqoop csatlakoztatható komponenst biztosít egy ideális hálózathoz és külső rendszerhez. A Sqoop API hasznos struktúrát nyújt az új csatlakozók összeszereléséhez, és ezért az adatbázis-összekötők leejthetők az Sqoop telepítésébe, hogy különféle adatrendszerekhez kapcsolódhassanak.
Mi az a Flume?
Az Apache Flume nemcsak a naplóadatok aggregációjára korlátozódik, hanem az adatforrások testreszabhatók, így a Flume felhasználható hatalmas mennyiségű adat továbbítására, ideértve, de nem korlátozva az e-maileket, a közösségi média által generált adatokat, a hálózati forgalmi adatokat és nagyjából minden adatforrás lehetséges.
Füstölő építészet: - A füstölő építészet sok alapvető koncepción alapul:
- Flume Event - az adatáramlás egységeként jelenik meg, amelynek bájt hasznos teherbírása és karakterlánckészlete opcionális karakterlánc fejlécekkel rendelkezik. Flume az eseményt csak általános byte-blobnak tekinti.
- Flume Agent - JVM folyamat, amely az összetevőket, például csatornákat, mosogatókat és forrásokat tárolja. Lehetősége van az események fogadására, tárolására és továbbítására egy külső forrásról a következő szintre.
- Flume Flow - az az időpont, amikor az esemény létrejön.
- Flume kliens - arra a felületre utal, ahol az ügyfél az esemény kiindulási pontján működik, és továbbítja azt a Flume ügynöknek.
- Forrás - egy forrás, amely egy meghatározott formátumú eseményeket fogyaszt, és egy meghatározott mechanizmuson keresztül továbbítja azokat.
- Csatorna: Passzív üzlet, ahol rendezvényeket tartanak, amíg a mosogató eltávolítja azt további szállítás céljából.
- Sink - Eltávolítja az eseményt egy csatornáról, és egy külső tárolóba helyezi, mint például a HDFS. Jelenleg támogatja a szöveges és a szekvencia fájlok létrehozását, és mindkét fájltípusban támogatja a tömörítést.
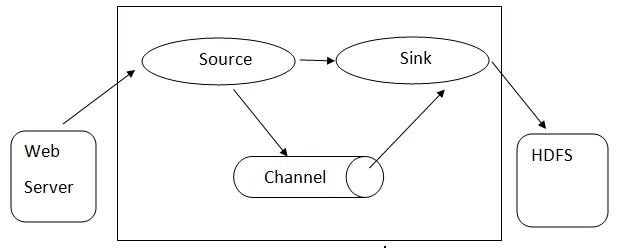
Flume építészete
Összehasonlítás a fej között a Sqoop és a Flume között (Infographics)
Az alábbiakban a 7 legjobb összehasonlítás található a Sqoop és a Flume között

Főbb különbségek a Sqoop és a Flume között
Most már tudjuk, hogy sok különbség van a Sqoop és a Flume között, az alábbiakban bemutatjuk a legfontosabb különbségeket köztük -
1. Az Sqoop célja a tömeges információcsere a Hadoop és a Relációs adatbázis között.
Míg a Flume-t különféle forrásokból származó adatok gyűjtésére használják, amelyek egy adott felhasználási esetre vonatkozóan generálnak adatokat, majd ezt a nagy mennyiségű adatot elosztják az elosztott erőforrásokból egyetlen központi adattárba.
2. Az Sqoop parancskészletet is tartalmaz, amely lehetővé teszi az Ön által használt adatbázis ellenőrzését. Ezért tekinthetjük az Sqoop-ot kapcsolódó eszközök gyűjteményének.
A dátum gyűjtésekor a Flume skálázza az adatokat vízszintesen, és több Flume ügynök is beindítható a dátum összegyűjtéséhez és összesítéséhez. Ezt követően az adatnaplókat áthelyezik egy központi adattárba, azaz a Hadoop Distributed File System (HDFS) fájlba.
3. A Flume használatának kulcstényezője az, hogy az adatokat folyamatosan és streaming módon kell előállítani. Hasonlóképpen, az Sqoop a legmegfelelőbb olyan helyzetekben, amikor az adatok olyan adatbázisrendszerekben élnek, mint például a MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (összehasonlító táblázat)
| Az összehasonlítás alapja | Apache Sqoop | FLUME |
|
Alapvető természet | Az Sqoop jól működik minden olyan JDBC-vel (Java Database Connectivity) rendelkező RDBMS-sel, mint például az Oracle, MySQL, Teradata stb. | A Flume jól működik a folyamatosan generáló adatforrások, például naplók, JMS, könyvtárak, összeomlási jelentések stb. Esetén. |
| Adatáramlás | A Sqoop kifejezetten a párhuzamos adatátvitelhez használható. Ezért a kimenet több fájlban lehet | A Flume eloszlott jellege miatt adatgyűjtésre és aggregálásra szolgál. |
| Vezetett események | A Sqoopot nem események vezérlik. | A Flume teljesen eseményvezérelt. |
| Építészet | A Sqoop a csatlakozókra épülő architektúrát követi, ami azt jelenti, hogy a csatlakozók tudják, hogyan kell csatlakozni más adatforráshoz. | A Flume ügynök-alapú architektúrát követ, ahol a benne írt kód ügynökként ismert, aki felelős az adatok letöltéséért. |
| Hol használható | Elsősorban az adatok gyorsabb lemásolására, majd elemzési eredmények előállítására használják. | Általában adatgyűjtésre használják, amikor a vállalatok naplók és közösségi média segítségével mintákat, kiváltó okokat vagy érzelmi elemzést akarnak elemezni. |
| Teljesítmény | Csökkenti a túlzott tárolási és feldolgozási terheléseket azáltal, hogy azokat más rendszerekbe továbbítja, és gyors teljesítményt nyújt. | A Flume hibatűrő, robusztus, és megbízható megbízhatósági mechanizmussal rendelkezik a feladatátvétel és a helyreállítás érdekében. |
| Kiadási előzmények | Az Apache Sqoop első verzióját 2012 márciusában indították. A jelenlegi stabil kiadás az 1.4.7 | Az Apache Flume első stabil 1.2.0 verziója 2012 júniusában indult. A jelenlegi stabil kiadás az Apache Flume 1.8.0 verzió. |
Következtetés - Sqoop vs Flume
Amint az Sqoop és a Flume fentebb megtudta, elsősorban a Data Adagolás eszköze a Big Data világ. Ha szöveges naplóadatokat kell beolvasnia a Hadoop / HDFS fájlba, akkor a Flume a megfelelő választás erre. Ha adatait nem generálják rendszeresen, akkor a Flume továbbra is működni fog, de ez a helyzet túlzott lesz. Hasonlóképpen, a Sqoop nem a legmegfelelőbb eseményvezérelt adatkezeléshez.
Ajánlott cikkek
Ez útmutatóként szolgál a Sqoop és a Flume közötti különbségek, azok jelentése, a fej-fej összehasonlítás, a legfontosabb különbségek, az összehasonlító táblázat és a következtetés között. ez a cikk az Sqoop és a Flume közötti összes hasznos különbséget tartalmazza. A következő cikkeket is megnézheti további információkért
- Hadoop vs Teradata - Hasznos különbségek a tanuláshoz
- 5 A legfontosabb különbség az Apache Kafka és a Flume között
- Big Data vs Apache Hadoop - A 4. legjobb összehasonlítás, amelyet meg kell tanulnia
- 5 A legfontosabb különbség az Apache Kafka és a Flume között
- Fontos szövegbányászat és természetes nyelvfeldolgozás - Öt összehasonlító elem