
A lakosság varianciaképlete (Tartalomjegyzék)
- Népességvariancia-képlet
- Példák a populációs variancia képletre (Excel sablonnal)
Népességvariancia-képlet
A statisztikákban a variancia alapvetően egy olyan intézkedés, amelynek segítségével meghatározzuk az adatkészlet értékeinek szóródását az adatkészlet átlagértéke alapján. Megméri az adatpont távolságát és az átlagot. Minél nagyobb a szórás, annál nagyobb lesz a szórás és az adatpontok általában távol esnek az átlagtól. Hasonlóképpen, az alacsonyabb szórás azt jelzi, hogy az adatpontok közelebb állnak az átlaghoz. Nagyon hasznos az olyan adatkészletek összehasonlításában, amelyeknek ugyanaz az átlagértéke, de eltérő tartományba eshetnek. A népesség szórása ugyanilyen értelemben azt jelzi, hogy a népesség adatpontjai hogyan oszlanak meg. Ez a népesség minden adatpontjától az átlagtól számított távolságok átlaga, négyzet. Általában kiszámítja a népesség-adatok szórását, de néha a népesség-adatok olyan hatalmasak, hogy gazdasági szempontból nincs értelme ennek varianciáját megtalálni. Ebben az esetben kiszámolják a minta varianciáját, és ez lesz a populációs variancia reprezentatív változata.
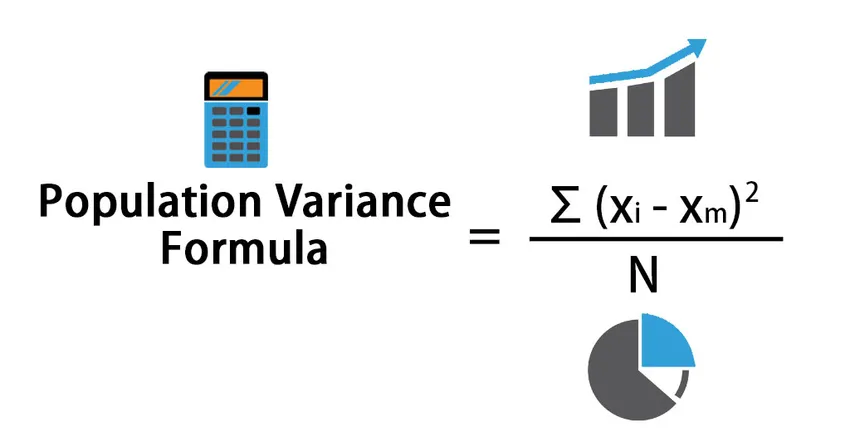
Tegyük fel, hogy van egy X népesség adatkészlete (X1, X2 …… ..Xn) adatpontokkal. A lakosság varianciaképletét a következő adja:
Population Variance = Σ (X i – X m ) 2 / N
Hol:
- X i - az adatkészlet i . Értéke
- X m - az adatkészlet átlagértéke
- N - az összes adatpont száma
A képlet először zavarónak tűnhet, de igazán dolgozni kell. A következő lépések követhetők a populáció variancia kiszámításához:
- Keresse meg, hogy a dolgozó adatkészlet minta vagy populáció-e.
- Keresse meg az pontok számát az adatkészletben, azaz n a populáció számára.
- A következő lépés az átlagérték meghatározása. Alapvetően az összes érték átlaga.
- Ezután minden adatpontnál keresse meg a különbséget az átlagtól, majd négyzetölje le.
- Vegyük össze az összes értéket a fenti lépésben, és osztjuk azt a 2. pontban kiszámított pontok számával.
Van egy másik módszer a variancia kiszámítására a VAR.P () függvény felhasználásával a populáció varianciájához és a VAR.S () függvény használatával az Excel mintában szereplő varianciához.
Példák a populációs variancia képletre (Excel sablonnal)
Vegyünk egy példát a népességvariancia-képlet kiszámításának jobb megértésére.
Itt töltheti le a populációs varianciaképlet Excel sablonját - Népességvariancia képlet Excel sablonA populáció varianciaképlete - 1. példa
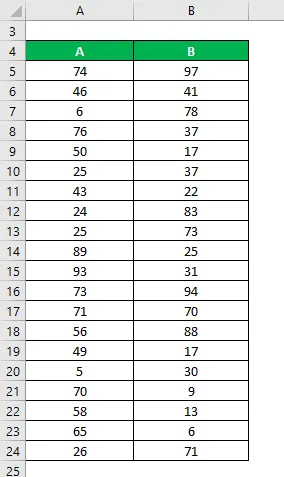
Tegyük fel, hogy két A és B minta adatkészletünk van, és mindegyik 20 véletlenszerű adatpontot tartalmaz. Számítsa ki a populációs varianciát mindkét adatkészletre.
Adatkészlet:
Az átlag kiszámítása:
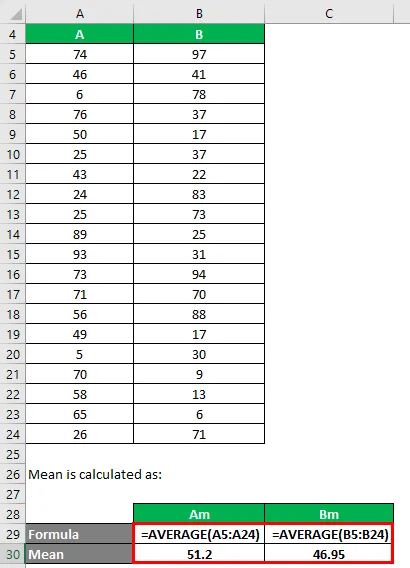
- Az A adatkészlet átlaga = 51, 2
- A B adatkészlet átlaga = 46, 95
Most ki kell számolnunk az adatpontok és az átlagérték közötti különbséget.
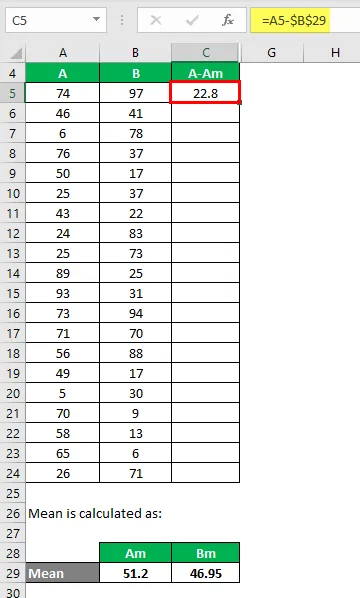
Hasonlóképpen számítsa ki az összes A adatkészletet.
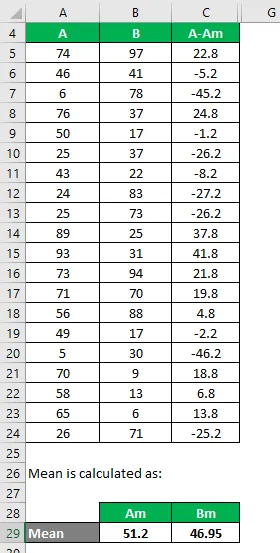
Hasonlóképpen számítsa ki a B adatkészletre is.
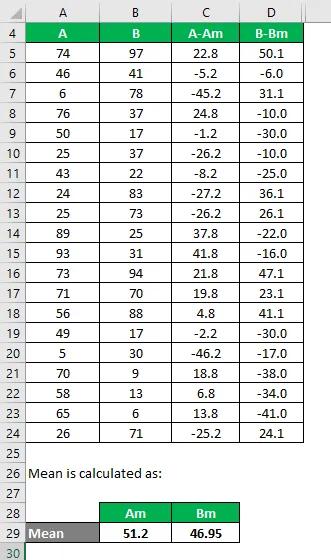
Számítsa ki a különbség négyzetét mind az A, mind a B adatkészletre.
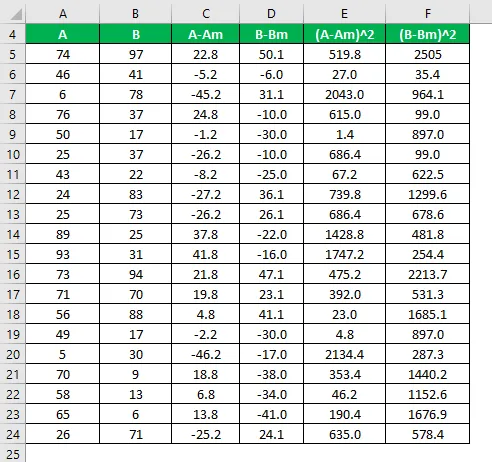
A populáció varianciáját az alábbiakban megadott képlettel számoljuk
Népességvariancia = Σ (X i - X m ) 2 / N
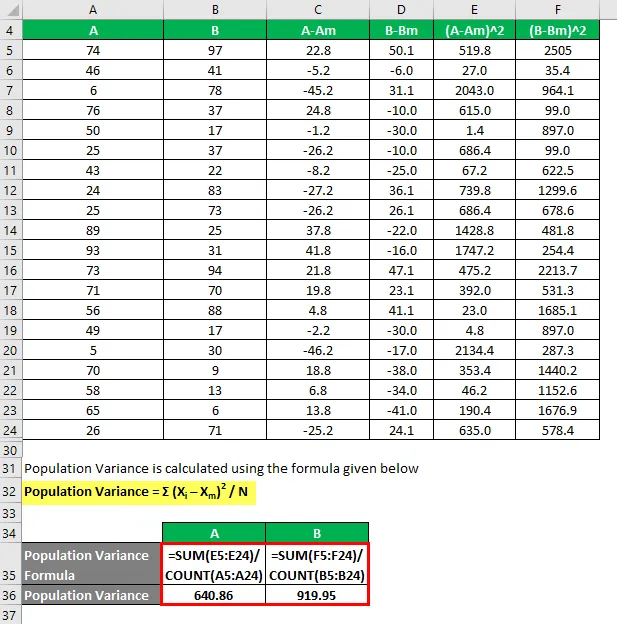
Tehát ha itt látod, B-nek nagyobb az varianciája, mint az A-nak, ami azt jelenti, hogy B adatpontjai szétszórtabbak, mint A.
Népességvariancia-képlet - 2. példa
Tegyük fel, hogy nagyon kockázatkerülő befektető, és pénzt szeretne befektetni a tőzsdére. Mivel alacsony a kockázatvállalási hajlandósága, biztonságos részvényekbe szeretne befektetni, amelyek alacsonyabb szórásúak.
A készleteket a múltbeli eredmények alapján szeretné elemezni, ezért úgy döntöttünk, hogy 15 éves mintát veszünk, és dolgozunk ezen adatokkal. Pénzügyi tanácsadója 4 részvényt javasolt neked, amelyek közül választhat. A két készlet közül választhat a 4 közül, és ezt alacsonyabb variancia alapján dönt.
Van információ a történelmi hozamukról az elmúlt 15 évben.
A populáció varianciáját az Excel képlettel számolják
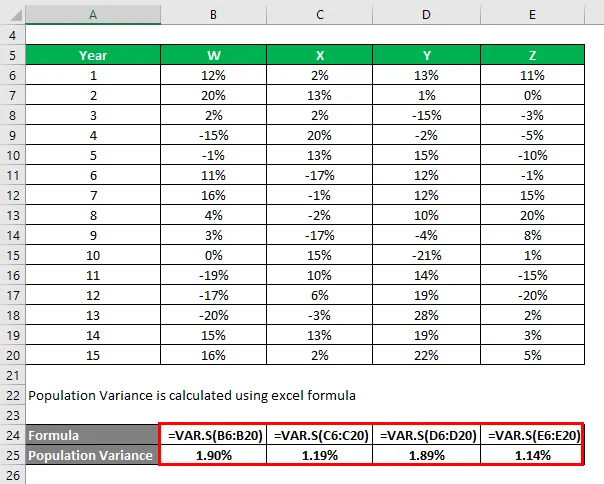
Az információk alapján az X és Z részvényt választja a befektetésre, mivel ezek a legkisebb szórásúak.
Magyarázat
Statisztikai szempontból tárgyaljuk a variancia jelentését, de ez segít a különféle pénzügyi mutatók megértésében is. A szórás a szórás alapköve, amelyet a variancia négyzetgyökének kiszámításával kell kiszámítani. A szórás a befektetés kockázatát méri, és hogy mennyire kockázatos a befektetés. A befektetők kockázata alapján a befektetők kiszámíthatják a kockázat kompenzálásához szükséges minimális hozamot. A varianciaérték, mivel egy szám négyzete, mindig pozitív lesz. Ez nulla lehet olyan adatkészletnél, amely azonos az elemekkel.
A lakosság varianciaképletének relevanciája és felhasználása
A variancia segíti a befektetőket és az elemzőket a szórás meghatározásában, ami tovább segíti a befektetés kockázat-haszon arányának vagy Sharpe-mutatójának megtalálását. Alapvetően bárki kockázatmentes megtérülési rátát szerezhet, ha kincstárba és kockázatmentes értékpapírokba fektet be. De ezen felül a visszatérés a túlzott hozam és ennek elérése.
Annak érdekében, hogy magasabb legyen a Sharpe arány, annál jobb a beruházás.
Mint már említettük, a szórás segít megtalálni a kockázatot mérő szórást, de az alacsonyabb szórás értéke nem mindig előnyös. Ha a befektető magasabb kockázatvállalási hajlandóságú és agresszívebb befektetni akarja, akkor hajlandó nagyobb kockázatot vállalni, és inkább egy viszonylag magasabb szórást részesít előnyben, mint a kockázatkerülő befektető. Tehát minden attól függ, hogy milyen szintű kockázatot vállal egy befektető.
Ajánlott cikkek
Ez egy útmutató a populációs varianciaképlethez. Itt tárgyaljuk, hogyan lehet kiszámítani a lakosság varianciáját, a gyakorlati példákkal és a letölthető excel sablonnal együtt. A következő cikkeket is megnézheti további információkért -
- Útmutató a T terjesztési képlethez
- Példák a relatív szórásképletre
- Hogyan lehet kiszámítani a vásárlóerő-paritást?
- A portfólió variancia képlete