

Különbség a Big Data és az Apache Hadoop között
Minden az interneten található. Az Internetnek nagyon sok adata van. Ezért minden Big Data. Tudja, hogy minden nap 2, 5 kvintill bájtnyi adat jön létre és nagy adatként halmozódik fel? Napi tevékenységeink, például a kommentálás, kedvelések, hozzászólások stb. Olyan közösségi médiában, mint a Facebook, a LinkedIn, a Twitter és az Instagram, nagy adatként jelennek meg. Feltételezzük, hogy 2020-ra majdnem 1, 7 megabájt adat jön létre másodpercenként, minden földi ember számára. Elképzelheti és megfontolhatja, mennyi adatot generál, feltételezve, hogy minden ember a földön van. Ma összekapcsolódunk és megosztjuk életünket online. Legtöbbünk online kapcsolódik. Okos otthonban élünk, intelligens járműveket használunk, és mindegyik csatlakozik okostelefonjainkhoz. El tudod képzelni, hogy ezek az eszközök hogyan válnak intelligensvé? Szeretnék nagyon egyszerű választ adni, mert a nagyon nagy mennyiségű adat, azaz a Big Data elemzése miatt. Öt éven belül több mint 50 milliárd intelligens csatlakoztatott eszköz lesz a világon, mindegyiket az adatok gyűjtésére, elemzésére és megosztására fejlesztették ki, hogy életünket kényelmesebbé tegyük.
Az alábbiakban bemutatjuk a Big Data vs Apache Hadoop ismertetését
Bemutatjuk a Term Big Data szolgáltatást
Mi az a Big Data? Milyen méretű adatot tekintünk nagynak, és nagy adatnak nevezzük? Sok relatív feltevésünk van a Big Data kifejezésre. Lehetséges, hogy az 50 terabyte adatmennyiség nagy adatnak tekinthető az induló vállalkozások számára, de lehet, hogy nem olyan nagy adat, mint például a Google és a Facebook. Ennek oka az, hogy rendelkeznek infrastruktúrával az ilyen mennyiségű adat tárolására és feldolgozására. A Big Data kifejezést szeretném meghatározni:
- A Big Data az az adatmennyiség, amely túlmutat a technológia azon képességén, hogy hatékonyan tárolja, kezelje és feldolgozza.
- A Big Data olyan adat, amelynek mérete, sokfélesége és összetettsége új architektúrát, technikákat, algoritmusokat és elemzéseket igényel a kezeléshez, valamint az érték és a rejtett tudás kinyeréséhez.
- A nagy adat nagy mennyiségű, nagy sebességű és nagyon sokféle információs eszköz, amely költséghatékony, innovatív információfeldolgozási formákat igényel, amelyek lehetővé teszik a jobb betekintést, a döntéshozatalt és a folyamatok automatizálását.
- A Big Data olyan technológiákra és kezdeményezésekre utal, amelyek olyan adatokat tartalmaznak, amelyek túl sokrétűek, gyorsan változóak vagy tömegesek ahhoz, hogy a hagyományos technológiák, készségek és infrastruktúra hatékonyan kezeljék azokat. Másként mondva, az adatok mennyisége, sebessége vagy sokfélesége túl nagy.
3 V nagy adatok
- Mennyiség: A mennyiség arra az mennyiségre / mennyiségre utal, amelyen az adatok készülnek, mint például minden órában, a Wal-Mart ügyfelek tranzakciói körülbelül 2, 5 petate adatot szolgáltatnak a társaságnak.
- Sebesség: A sebesség azt az adatmennyiséget jelzi, amellyel a Facebook felhasználók átlagosan 31, 25 millió üzenetet küldenek, és percenként 2, 77 millió videót néznek meg minden nap az interneten.
- Változat: A változatosság az adatok különböző formátumaira utal, amelyeket létrehoznak, mint például strukturált, félig strukturált és nem strukturált adatok. Mint például az e-mailek küldése a melléklettel a Gmailben nem strukturált adatok, miközben bármilyen megjegyzés hozzáfűzése néhány külső linkkel, strukturálatlan adatnak is nevezik. A képek, audioklippek, videoklipek megosztása az adatok nem strukturált formája.
Az óriási mennyiségű, sebességű és sokféle adat tárolása és feldolgozása nagy probléma. A Big Data számára az RDBMS-en kívül más technológiákra is gondolkodnunk kell. Ennek oka az, hogy az RDBMS csak strukturált adatokat képes tárolni és feldolgozni. Tehát itt az Apache Hadoop van megmentés.
Bemutatjuk a Term Apache Hadoop alkalmazást
Az Apache Hadoop egy nyílt forrású szoftverkeret az adatok tárolására és az alkalmazások futtatására az árucikk-hardverek klaszterén. Az Apache Hadoop egy olyan szoftverkeret, amely lehetővé teszi a nagy adatkészletek elosztott feldolgozását a számítógépek csoportjai között egyszerű programozási modellek segítségével. Úgy tervezték, hogy egységes kiszolgálóktól több ezer gépig bővítsék, mindegyik helyi kiszámítást és tárolást kínál. Az Apache Hadoop a nagy adatok tárolására és feldolgozására szolgáló keret. Az Apache Hadoop képes az adatok minden formátumának tárolására és feldolgozására, például strukturált, félig strukturált és nem strukturált adatokra. Az Apache Hadoop nyílt forráskódú és az alapanyagú hardver forradalmat hozott az informatikai iparban. Könnyen elérhető minden szintű vállalkozás számára. Nem kell többet befektetniük a Hadoop-fürt felállításához és a különböző infrastruktúrákba. Tehát ennél részletesen láthatjuk a Big Data és az Apache Hadoop közötti hasznos különbséget ebben a bejegyzésben.
Apache Hadoop keretrendszer
Az Apache Hadoop keretrendszer két részre oszlik:
- Hadoop elosztott fájlrendszer (HDFS): Ez a réteg felelős az adatok tárolásáért.
- MapReduce: Ez a réteg felelős az adatok Hadoop-fürtön történő feldolgozásáért.
A Hadoop Framework mester és slave architektúrára oszlik. A Hadoop elosztott fájlrendszer (HDFS) réteg névcsomópontja a fő összetevő, míg az adatcsomópont a szolga összetevő, míg a MapReduce rétegben a Job Tracker a fő összetevő, míg a feladatkövető a szolga összetevő. Az alábbiakban látható az Apache Hadoop keretrendszerének diagramja.
Miért fontos az Apache Hadoop?
- Képesség bármilyen típusú adat gyors tárolására és feldolgozására
- Számítási teljesítmény: A Hadoop elosztott számítási modellje gyorsan feldolgozza a nagy adatokat. Minél több számítási csomópontot használ, annál nagyobb a feldolgozási teljesítmény.
- Hibatolerancia: Az adatok és az alkalmazások feldolgozása védett a hardverhibák ellen. Ha egy csomópont csökken, a feladatokat automatikusan átirányítja más csomópontokra, hogy megbizonyosodjon arról, hogy az elosztott számítástechnika nem hibás-e. Az összes adat több példányát automatikusan tárolja.
- Rugalmasság: annyi adatot tárolhat, amennyit csak akar, és eldöntheti, hogyan használja később. Ez magában foglalja a nem strukturált adatokat, például szöveget, képeket és videókat.
- Olcsó: A nyílt forráskódú keret ingyenes, és nagy mennyiségű adat tárolására árucikk hardvert használ.
- Méretezhetőség: Könnyedén bővítheti rendszerét, hogy több adatot kezeljen, egyszerűen csomópontok hozzáadásával. Kis adminisztrációra van szükség
Összehasonlítás a nagy adatok és az Apache Hadoop között (Infographics)
Az alábbiakban a négy legjobb összehasonlítás található a Big Data és az Apache Hadoop között
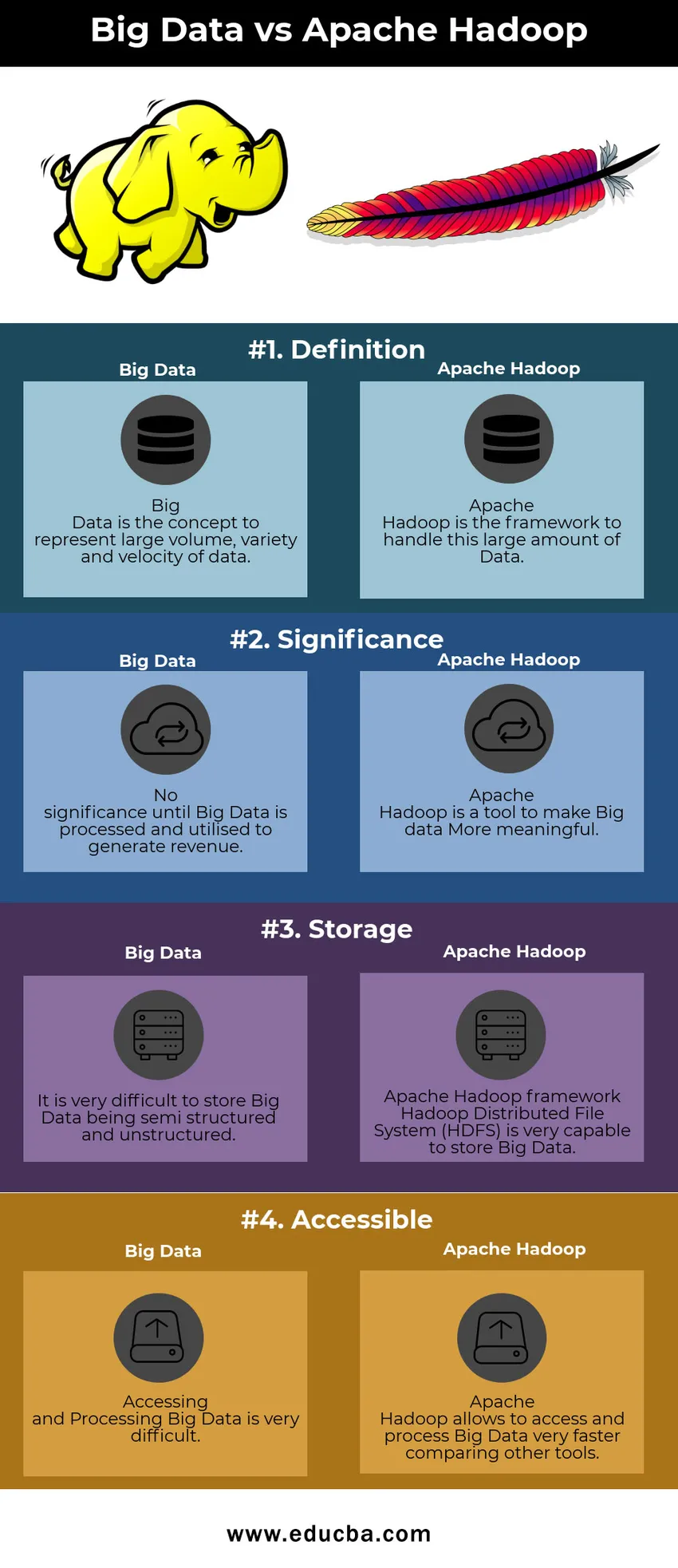
Big Data vs Apache Hadoop összehasonlító táblázat
Fontos tárgyakat tárgyalok, és különbséget teszek a Big Data és az Apache Hadoop között
| Nagy adat | Apache Hadoop | |
| Meghatározás | A Big Data a nagy mennyiségű, változatosságot és sebességet ábrázoló koncepció | Az Apache Hadoop képezi a nagy mennyiségű adat kezelésének keretét |
| Jelentőség | Nincs jelentősége, amíg a Big Data feldolgozásra nem kerül és bevételszerzésre nem kerül sor | Az Apache Hadoop olyan eszköz, amellyel a nagy adatok értelmesebbé válnak |
| Tárolás | Nagyon nehéz a Big Data félig strukturált és strukturálatlan módon tárolni | Az Apache Hadoop Framework Hadoop Distributed File System (HDFS) nagyon képes nagy adat tárolására |
| Hozzáférhető | A nagy adatok elérése és feldolgozása nagyon nehéz | Az Apache Hadoop lehetővé teszi a nagy adatok elérését és feldolgozását a többi eszköz összehasonlításával |
Következtetés - Big Data vs Apache Hadoop
Nem hasonlíthatja össze a Big Data és az Apache Hadoop szoftvereket. Ennek oka az, hogy a nagy adat probléma, míg az Apache Hadoop a megoldás. Mivel az adatmennyiség exponenciálisan növekszik az összes ágazatban, ezért nagyon nehéz az adatokat egyetlen rendszerből tárolni és feldolgozni. Tehát a nagy mennyiségű adat feldolgozásához elosztott feldolgozásra és adatok tárolására van szükségünk. Ezért az Apache Hadoop megoldást kínál egy nagyon nagy mennyiségű adat tárolására és feldolgozására. Végül azt a következtetést vonom le, hogy a Big Data nagy mennyiségű összetett adat, míg az Apache Hadoop a Big Data nagyon hatékony és zökkenőmentes tárolására és feldolgozására szolgáló mechanizmus.
Ajánlott cikk
Ez egy útmutató a Big Data vs Apache Hadoop-hoz, azok jelentéséhez, a fej-fej összehasonlításhoz, a legfontosabb különbségekhez, az összehasonlító táblázathoz és a következtetésekhez. ez a cikk az összes hasznos különbséget tartalmazza a Big Data és az Apache Hadoop között. A következő cikkeket is megnézheti további információkért -
- Big Data vs Data Science - miben különböznek egymástól?
- Az öt legnagyobb adat-trend, amelyet a vállalatoknak elsajátítaniuk kell
- Hadoop vs Apache Spark - Érdekes dolgok, amelyeket tudnod kell
- Apache Hadoop vs Apache Spark | A tíz legjobb összehasonlítás, amit tudnod kell!