
Mi az SVM algoritmus?
Az SVM a Support Vector Machine kifejezést jelenti. Az SVM egy felügyelt gépi tanulási algoritmus, amelyet általában osztályozási és regressziós kihívásokhoz használnak. Az SVM algoritmus általános alkalmazásai a behatolásérzékelő rendszer, a kézírás-felismerés, a fehérjeszerkezet-előrejelzés, a szteganográfia észlelése digitális képekben stb.
Az SVM algoritmusban minden pont adatelemként jelenik meg az n-dimenziós térben, ahol az egyes jellemzők értéke egy adott koordináta értéke.
A rajzolás után a besorolást két osztályt megkülönböztető hype-sík megtalálásával hajtottuk végre. Lásd az alábbi képet, hogy megértse ezt a koncepciót.
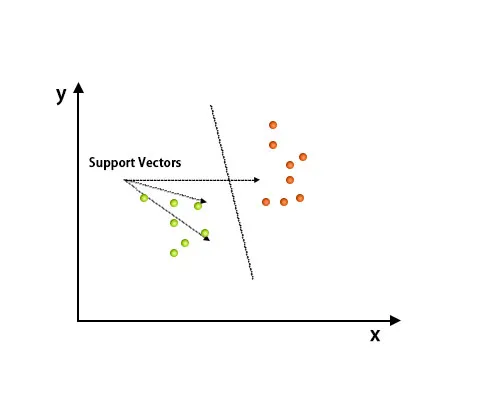
A Support Vector Machine algoritmust elsősorban az osztályozási problémák megoldására használják. A támogatási vektorok nem más, mint az egyes adatelemek koordinátái. A Support Vector Machine egy olyan határ, amely hiper-sík segítségével két osztályt különböztet meg.
Hogyan működik az SVM algoritmus?
A fenti szakaszban két osztály megkülönböztetését tárgyaltuk hiper-sík segítségével. Most megnézjük, hogyan működik ez az SVM algoritmus valójában.
1. forgatókönyv: Azonosítsa a jobb hipersíkot
Itt vettünk három hipersíkot, azaz A, B és C. Most meg kell határoznunk a megfelelő hipersíkot a csillag és a kör osztályozásához.
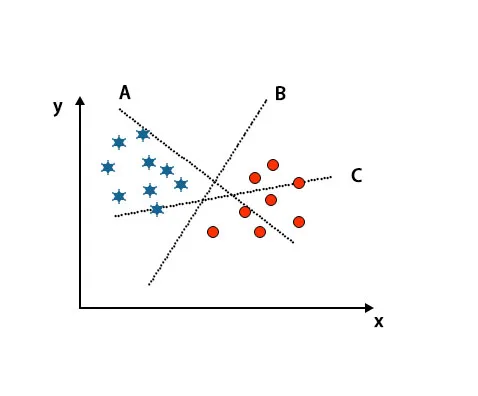
A megfelelő hipersík azonosításához meg kell ismernünk a hüvelykujjszabályt. Válasszon hipersíkot, amely megkülönbözteti a két osztályt. A fenti képen a B hipersík két osztályt különböztet meg nagyon jól.
2. forgatókönyv: Azonosítsa a jobb hipersíkot
Itt három hiper-síkot vettünk, azaz az A, a B és a C. Ez a három hiper sík már nagyon jól megkülönbözteti az osztályokat.
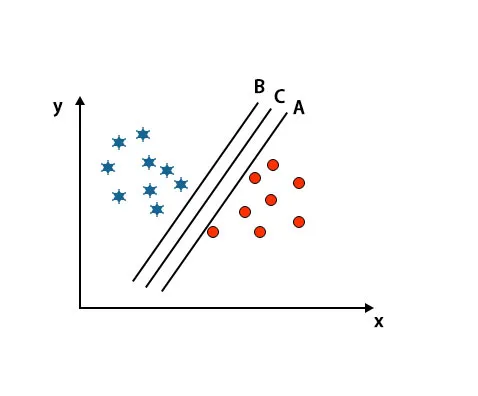
Ebben a forgatókönyvben a megfelelő hipersík azonosításához megnöveljük a legközelebbi adatpontok közötti távolságot. Ez a távolság nem más, mint egy margó. Lásd a képet.
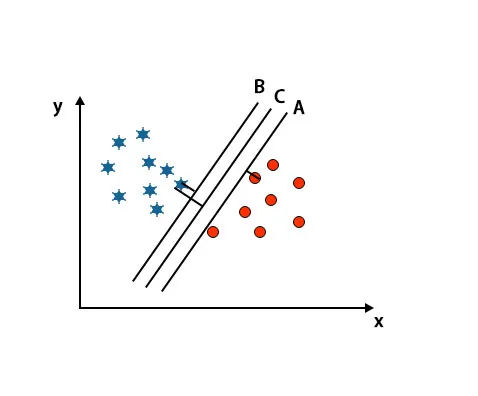
A fent említett képen a C hipersík széle magasabb, mint az A hiper és a B hiper sík. Tehát ebben a forgatókönyvben C a jobb hiper sík. Ha a hiper síkot választjuk minimális mozgástérrel, akkor ez téves besorolást eredményezhet. Ezért a C hiper síkot választottuk a maximális mozgástérrel a robusztusság miatt.
3. forgatókönyv: Azonosítsa a jobb hipersíkot
Megjegyzés: A hipersík azonosításához kövesse ugyanazokat a szabályokat, mint amelyeket az előző szakaszokban említettek.
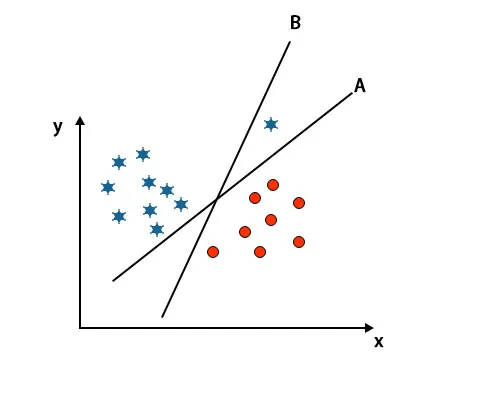
Amint az a fent említett képen látható, a B hipersík széle magasabb, mint az A hipersík széle, ezért egyesek jobbra a B hipersíkot választják. De az SVM algoritmusban kiválasztja azt a hiper-síkot, amely pontosan osztályozza az osztályokat a margó maximalizálása előtt. Ebben a forgatókönyvben az A hipersík pontosan osztályozta az összes hibát, és van néhány hiba a B hipersík osztályozásával. Ezért A az a jobb hipersík.
4. forgatókönyv: Osztályozzon két osztályt
Amint az az alább említett képen látható, nem tudunk különbséget tenni két osztályt egyenes vonal használatával, mivel az egyik csillag a másik kör osztályán kívül helyezkedik el.
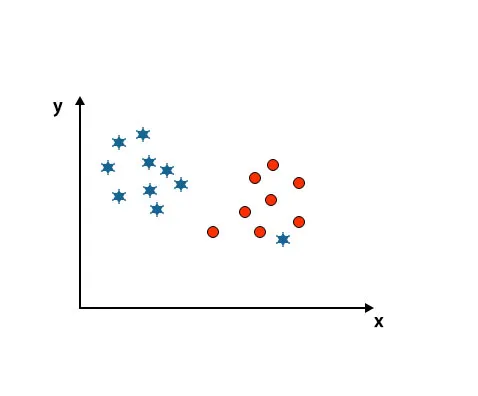
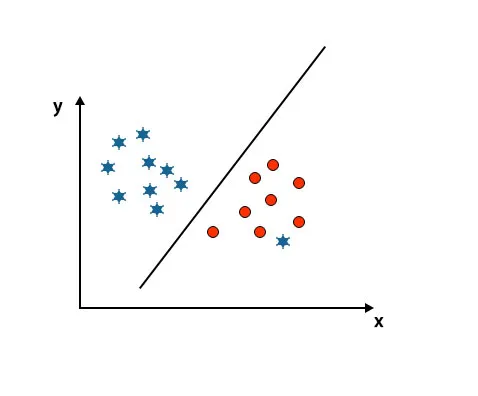
Itt az egyik csillag egy másik osztályban van. A csillagok számára ez a csillag a legkülső. Az SVM algoritmus robusztussági tulajdonsága miatt meg fogja találni a megfelelő hiper síkot, magasabb margóval, figyelmen kívül hagyva a külső értékeket.
5. forgatókönyv: Finom hipersík az osztályok megkülönböztetésére
Mostanáig a lineáris hiper síkra néztünk. Az alább említett képen nincs osztályok közötti lineáris hipersík.
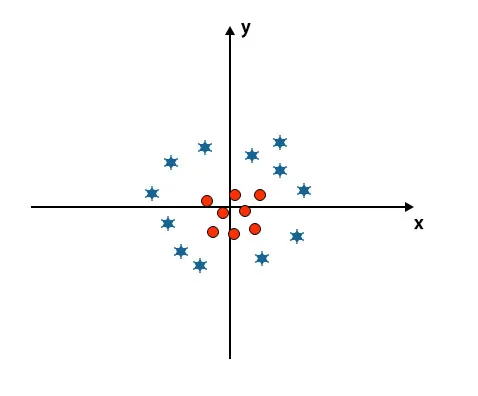
Ezen osztályok osztályozásához az SVM bemutat néhány további funkciót. Ebben a forgatókönyvben ezt az új funkciót fogjuk használni: z = x 2 + y 2.
Az összes adatpontot ábrázolja az x és a z tengelyen.

jegyzet
- Az összes z-tengelyen lévő értéknek pozitívnak kell lennie, mivel z egyenlő az x négyzet és az y négyzet összegével.
- A fent említett ábrán a piros körök zárva vannak az x tengely és az y tengely eredetéig, és z értékét alsó irányba vezetjük, és a csillag pontosan ellentétes a körrel, távol van az x tengely kezdetétől és y tengely, ami z értéket magasra vezet.
Az SVM algoritmusban könnyű osztályozni a két osztály között egyenes hiper síkkal. De itt felmerül a kérdés, hogy hozzáadjuk-e az SVM ezt a tulajdonságát a hipersík azonosításához. Tehát a válasz nem, a probléma megoldásához az SVM technikával rendelkezik, amelyet általában kernelcsokának hívnak.
A kernel-trükk az a funkció, amely az adatokat megfelelő formává alakítja. Különböző típusú kernelfunkciókat használunk az SVM algoritmusban, azaz polinomiális, lineáris, nemlineáris, radiális alapfüggvényeket stb. Itt. Kernel trükkökkel az alacsony dimenziós bemeneti helyet átalakítják egy magasabb dimenziós térré.
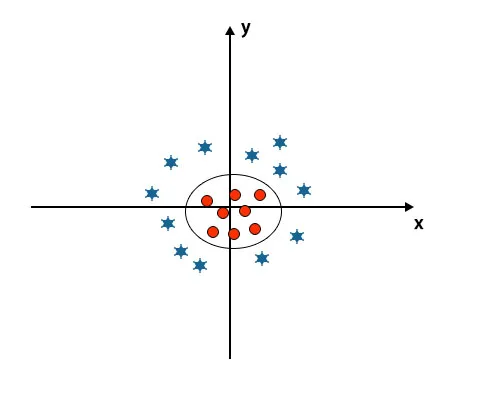
Ha megvizsgáljuk a hipersíkot, a tengely és az y tengely eredetét, úgy néz ki, mint egy kör. Lásd a képet.
Az SVM algoritmus előnyei
- Még ha a bemeneti adatok nem is lineárisak és nem választhatók szét, az SVM-ek robusztussága miatt pontos osztályozási eredményeket generálnak.
- A döntési funkcióban támogató vektoroknak nevezett edzési pontok egy részét használja, tehát memóriahatékony.
- Hasznos minden összetett problémát egy megfelelő kernelfunkcióval megoldani.
- A gyakorlatban az SVM modellek általánosítottak, és kevesebb az SVM túlzott felszerelésének kockázata.
- Az SVM kiválóan működik a szöveges osztályozásban és a legjobb lineáris elválasztó megtalálásában.
Hátrányai az SVM algoritmus
- Nagy adatkészletekkel való munka során hosszú edzési idő szükséges.
- Nehéz megérteni a végső modellt és az egyéni hatásokat.
Következtetés
Útmutatást kapott a Vector Machine Algorithm támogatására, amely egy gépi tanulási algoritmus. Ebben a cikkben megvitattuk, mi az SVM algoritmus, hogyan működik, és milyen előnyökkel jár.
Ajánlott cikkek
Ez egy útmutató az SVM algoritmushoz. Itt tárgyaljuk annak működését az SVM algoritmus forgatókönyvével, előnyeivel és hátrányaival együtt. A következő cikkeket is megnézheti további információkért -
- Adatbányászati algoritmusok
- Adatbányászati technikák
- Mi a gépi tanulás?
- Gépi tanulási eszközök
- Példák a C ++ algoritmusra