

Mi a MapReduce algoritmus?
A MapReduce algoritmust elsősorban a funkcionális programozási modell ihlette. Nagy adatok feldolgozására és előállítására szolgál. Ezek az adatkészletek egyszerre futtathatók és fürtönként eloszthatók. A MapReduce program elsősorban térképezési eljárásból és redukciós módszerből áll, hogy elvégezzék az összefoglaló műveletet, például megszámolják vagy eredményeket nyújtsanak. A MapReduce rendszer elosztott szerverekön működik, amelyek párhuzamosan futnak és kezelik az összes kommunikációt a különböző rendszerek között. A modell a split-use-kombinálási stratégia speciális stratégiája, amely segíti az adatok elemzését. A leképezést a Mapper osztály végzi, és a feladat csökkentését a Reducer osztály végzi.
A MapReduce algoritmus megértése
A MapReduce algoritmus elsősorban három lépésben működik:
- Térkép funkció
- Véletlenszerű funkció
- Csökkentse a funkciót
Beszéljünk meg az egyes funkciókról és azok felelősségéről.
1. Térkép funkció
Ez a MapReduce algoritmus első lépése. Az adatkészleteket elfoglalja és kisebb alfeladatokra osztja. Ezt két lépésben hajtják végre: felosztás és leképezés. A felosztás elveszi a bemeneti adatkészletet és elosztja az adatkészletet, miközben a leképezés elvégzi az adatok ezen részhalmazát, és elvégzi a szükséges műveletet. Ennek a funkciónak a kimenete kulcs-érték pár.
2. Véletlenszerű keverés
Ezt kombinációs funkciónak is nevezik, és magában foglalja az összevonást és a válogatást. Az egyesítés egyesíti a kulcs-érték párokat. Mindezen kulcsok azonosak lesznek. A rendezés a bemenetet veszi az egyesítési lépésből, és a kulcsok felhasználásával rendezi az összes kulcs-érték párt. Ez a lépés visszatér a kulcs-érték párokhoz is. A kimenet rendezve lesz.
3. Csökkentse a funkciót
Ez az algoritmus utolsó lépése. Eltávolítja a kulcs-érték párokat a véletlenszerű keverésből és csökkenti a műveletet.
Hogyan könnyíti meg a MapReduce algoritmusok a munkát?
A relációs adatbázis rendszerek központi szerverrel rendelkeznek, amely segít az adatok tárolásában és feldolgozásában. Ezek általában központosított rendszerek voltak. Ha több fájl kerül a képre, a feldolgozás unalmas és szűk keresztmetszetet teremt több fájl feldolgozása közben. A MapReduce leképezi az adatkészletet és konvertálja azt az adatkészletet, ahol minden adat fel van osztva tuplokra, és a kicsinyítési feladat ebből a lépésből veszi a kimenetet, és ezeket az adattípusokat kisebb csoportokba egyesíti. Különböző fázisokban működik, és kulcs-érték párokat hoz létre, amelyeket különböző rendszerekre lehet elosztani.
Mit tehet a MapReduce algoritmusokkal?
A MapReduce különféle alkalmazásokhoz használható. Használható elosztott mintaalapú kereséshez, elosztott rendezéshez, weblink gráf visszafordításához, webes hozzáférési napló statisztikákhoz. Segíthet több klaszter, asztali rács, önkéntes számítási környezet létrehozásában és az azokon végzett munkában is. Emellett dinamikus felhőkörnyezeteket, mobil környezeteket és nagy teljesítményű számítási környezeteket is létrehozhat. A Google a MapReduce-t használta, amely újból létrehozza a világhálón található Google Indexet. Ennek használatával a régi ad hoc programok frissülnek, és különféle elemzéseket végeznek. Az élő keresési eredményeket a teljes index újratelepítése nélkül integrálta. Az összes bemenetet és kimenetet az elosztott fájlrendszer tárolja. Az átmeneti adatokat egy helyi lemezen tárolják.
Együttműködés a MapReduce algoritmussal
A MapReduce algoritmus használatához tudnia kell a működésének teljes folyamatát. A bevitt adatok a következő lépéseken mennek keresztül:
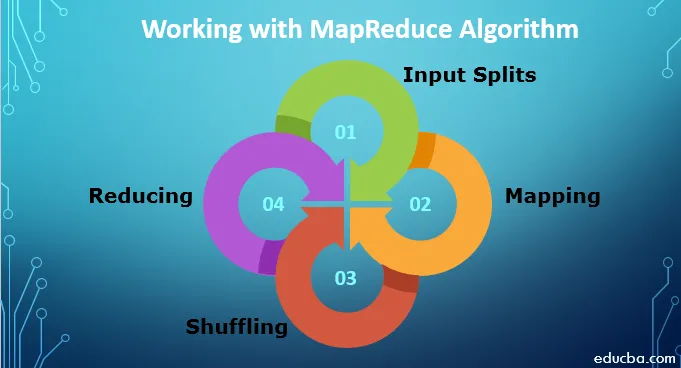
1. Bemeneti felosztások: A MapReduce jobhoz tartozó bemeneti adatok egyenlő részekre oszlanak, amelyeket bemeneti felosztásoknak hívnak. Ez egy olyan adatmennyiség, amelyet bármelyik térképező felhasználhatja.
2. Leképezés: Miután az adatokat darabra osztottuk, áthalad a térkép-csökkentési fázisban. Ezt a megosztott adatot továbbítják a leképezési funkcióhoz, amely különböző kimeneti értékeket állít elő.
3. Véletlen sorrend: Ha a leképezés megtörtént, az adatokat elküldi erre a fázisra. Feladata az előző szakaszból származó szükséges rekordok egyesítése.
4. Csökkentés: Ebben a fázisban az eloszlatási fázis kimenete összesítve van. Ebben a fázisban az összes értéket elkeverjük és aggregáljuk, hogy egyetlen kimeneti értéket kapjon. Összefoglalót készít a teljes adathalmazról.
A MapReduce algoritmus előnyei
A MapReduce-t használó alkalmazások az alábbi előnyökkel rendelkeznek:
- Konvergenciával és jó általánosítási teljesítménygel bírtak.
- Az adatok adatintenzív alkalmazások felhasználásával kezelhetők.
- Nagy skálázhatóságot biztosít.
- Könnyű megszámolni minden szó esetét és hatalmas dokumentumgyűjteménye van.
- Egy általános eszköz felhasználható az eszköz keresésére számos adatelemzés során.
- Nagy fürtökben kínál terheléselosztási időt.
- Segít a felhasználói hely, helyzet, stb. Kontextusának kinyerésében is.
- Gyorsan hozzáférhet a válaszadók nagy mintáihoz.
Miért kellene a MapReduce algoritmust használni?
A MapReduce egy olyan alkalmazás, amelyet hatalmas adatkészletek feldolgozására használnak. Ezeket az adatkészleteket párhuzamosan lehet feldolgozni. A MapReduce potenciálisan nagy adatkészleteket és nagy számú csomópontot hozhat létre. Ezeket a nagy adatkészleteket a HDFS tárolja, ami megkönnyíti az adatok elemzését. Bármilyen adatot képes feldolgozni, például strukturált, strukturálatlan vagy félig strukturált.
Miért van szükség a MapReduce algoritmusra?
A MapReduce gyorsan növekszik, és elősegíti a párhuzamos számítást. Segít a termékek árának meghatározásában, és elősegíti a legnagyobb nyereséget. Segít az elemzés előrejelzésében és ajánlásában. Ez lehetővé teszi a programozók számára, hogy modelleket futtassanak különböző adatkészleteken, és fejlett statisztikai technikákat és gépi tanulási technikákat használnak, amelyek segítenek az adatok előrejelzésében. Szűrje és elküldi az adatokat a klaszter különböző csomópontjaira, és a térképező és reduktor funkció szerint működik.
Hogyan segít ez a technológia a karriernövekedésben?
A Hadoop manapság a legkeresettebb munkahelyek közé tartozik. Ez felgyorsítja az arányt és a lehetőséget, amely ezen a területen nagyon gyorsan növekszik. Ennél a téren még fellendülni fog a fellendülés. A Java-ban dolgozó IT szakembereknek van egy pluszpontjuk, mivel ők a legkeresettebb emberek. Továbbá, a fejlesztők, az adatok építészei, az adattárházak és a BI szakemberek e technológia megtanulásával óriási összeget fizethetnek el.
Következtetés
A MapReduce a Hadoop keret alapja. Ennek megtanulásával biztosan belép az adatelemzési piacra. Megtanulhatja alaposan, és megismerheti, hogy mekkora adatkészletet dolgoznak fel, és hogy ez a technológia hogyan változtatja meg az adatok feldolgozását és tárolását.
Ajánlott cikkek
Ez egy útmutató a MapReduce algoritmusokhoz. Itt tárgyaljuk a koncepciót, a megértést, a működést, a szükségletet, az előnyöket és a karriernövekedést. A további javasolt cikkeken keresztül további információkat is megtudhat -
- A MapReduce interjúval kapcsolatos kérdései
- Mi a MapReduce a Hadoopban?
- Hogyan működik a MapReduce?
- Mi a MapReduce?
- Különbségek a Hadoop és a MapReduce között
- Különböző műveletek a Tuples-szel kapcsolatban