
Különbség a kaptár és a HBase között
Az Apache Hive és a HBase Hadoop alapú nagy adattechnológiák. Mindketten adatgyűjtésre használtak. A Hive és a HBase a Hadoop tetején futnak, és funkcionálisan különböznek egymástól. A Hive térkép-alapú SQL nyelvjárás, míg a HBase csak a MapReduce-t támogatja. A HBase az adatokat kulcs / érték vagy oszlopcsalád-pár formájában tárolja, míg a Hive nem tárolja az adatokat.
Fej-fej különbségek a kaptár és a HBase között (Infographics)
Az alábbiakban a Hive és a HBase közötti legjobbak közötti 8 különbség látható
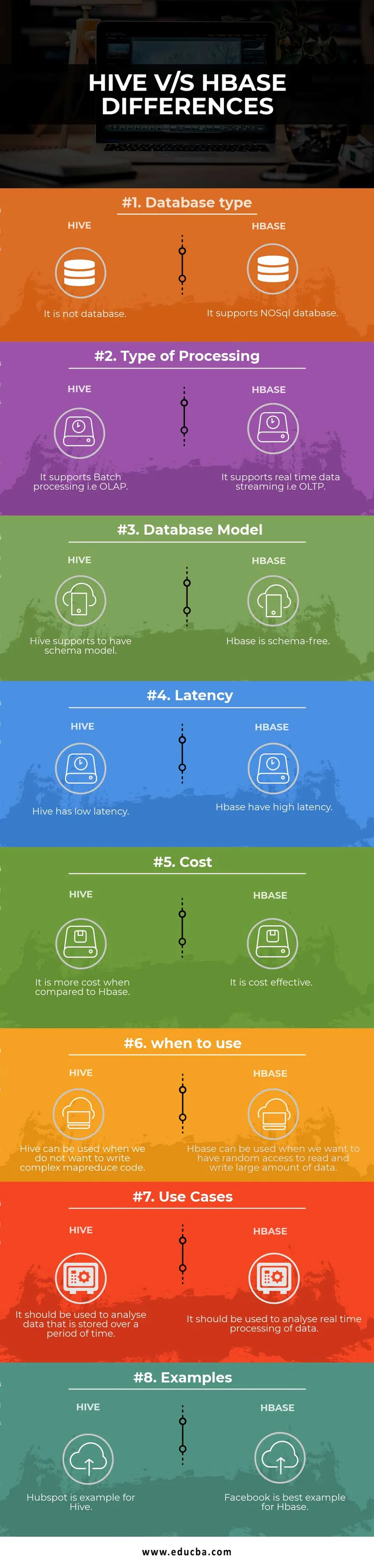
A Hive és a HBase közötti különbségek
- A Hbase egy ACID-kompatibilis, míg a Hive nem.
- A Hive támogatja a particionálást és a szűrési kritériumokat a dátumformátum alapján, míg a HBase támogatja az automatikus particionálást.
- A Hive nem támogatja a frissítési utasításokat, míg a HBase támogatja azokat.
- A Hbase gyorsabb, mint a Hive az adatok letöltése.
- A Hive a strukturált adatok feldolgozására szolgál, míg a HBase, mivel séma-mentes, bármilyen típusú adatot képes feldolgozni.
- A Hbase erősen (vízszintesen) skálázható, mint a Hive.
- A Hive elemezte a HDFS adatait az SQL lekérdezések segítségével, majd átalakítja azokat térképpé és csökkenti a feladatokat, míg a Hbase-ben, mivel a valós idejű adatfolyam streaming, közvetlenül az adatbázisban végzi műveleteit táblákba és oszlopcsaládokba osztással.
- amikor az adatrészek lekérdezésekor a kaptár egy Hive shell néven ismert héjat használ a parancsok kiadására, míg a HBase, mivel ez adatbázis, parancsot fogunk használni az adatok feldolgozásához a HBase-ben.
- A kaptárhéj eléréséhez a kaptár parancsot használjuk. Miután megadta, úgy fog megjelenni, mint a kaptár> .A HBase-ben egyszerűen a HBase használatának adjuk meg.
Hive vs HBase összehasonlító táblázat
| Az összehasonlítás alapja | Kaptár | Hbase |
| Adatbázis típusa | Ez nem adatbázis | Támogatja a NoSQL adatbázist |
| A feldolgozás típusa | Támogatja a kötegelt feldolgozást, azaz az OLAP-t | Támogatja a valós idejű adatfolyamot, azaz az OLTP-t |
| Adatbázis-modell | A kaptár támogatja a sémamodellt | Az Hbase séma-mentes |
| Késleltetés | A kaptár alacsony késleltetési idővel rendelkezik | A Hbase nagy késleltetésű |
| Költség | Ez költségesebb, mint a HBase | Költséghatékony |
| mikor kell használni | A kaptár akkor használható, ha nem akarunk összetett MapReduce kódot írni | A HBase akkor használható, ha véletlen hozzáférést akarunk elérni nagy mennyiségű adat olvasásához és írásához |
| Használjon eseteket | Ezt egy ideig tárolt adatok elemzésére kell használni | Az adatok valós idejű feldolgozásának elemzésére kell használni. |
| Példák | A Hubspot példa a Hive számára | A Facebook a legjobb példa a Hbase számára |
A Hive és a HBase közötti kódolás különbségei
Most tárgyaljuk meg a Hive és a HBase közötti alapvető különbségeket a kódolásban.
| Az összehasonlítás alapja | Kaptár | Hbase |
| Adatbázis létrehozása | AZ ADATBÁZIS LÉTREHOZÁSA (HA NEM MEGLÉVIK) ADATBÁZIS-NEV; | Mivel a Hbase adatbázis, nem kell külön adatbázist létrehoznunk |
| Adatbázis eldobása | CÍMÁNOS ADATBÁZIS (HA LENKEZIK) ADATBÁZIS-NEV (KORLÁTOZOTT VAGY CSAKAD); | NA |
| Táblázat létrehozása | Létrehozása (ideiglenes vagy külső) tábla (ha nem létezik) Táblázatnév ((oszlopnév-adattípus (Megjegyzés oszlop-megjegyzés), ….)) (Megjegyzéstábla-megjegyzés) (ROW FORMAT sor-formátum) (Fájl formátumban tárolva) | CREATE '', '' |
| A táblázat megváltoztatása | ALTER TABLE név RENAME to new-name
ALTER TABLE név DROP (COLUMN) oszlopnév VÁLTOZÓ TÁBLÁZAT név hozzáadása oszlopok (col-spec (, col-spec ..)) ALTER TABLE név VÁLTOZTATÁS oszlopnév új név új név új típus VÁLTOZÓ TÁBLÁZAT neve CSERÉLJEN OSZLOPOK (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VÁLTOZÁS => |
| Táblázat letiltása | NA | a 'TABLE-NAME' -> letiltása a megadott táblanév letiltásához
Disable_all 'r *' -> az összes tábla letiltásához, amely megegyezik a normál kifejezéssel |
| Táblázat engedélyezése | NA | engedélyezze a „TABLE-NAME” |
| Egy asztal eldobása | HASZNÁLATTÁBLÁZAT, Ha létezik táblanév | Ha szeretnénk egy táblát ejteni, akkor először le kell tiltanunk
letiltja a 'table-name' drop 'table-name' Hasonlóképpen, a Disable_all és a drop_all használatával törölhetjük a megadott reguláris kifejezésnek megfelelő táblákat. |
| Az adatbázisok felsorolása | adatbázisok megjelenítése; | NA |
| A táblák felsorolása az adatbázisban | bemutató táblák; | lista |
| A táblázat sémájának leírása | írja le a tábla nevét; | írja le a „tábla-nevet” |
A kaptár és a HBase integrálása
- Telepítse és konfigurálja a Hive alkalmazást.
- Telepítse és konfigurálja a HBase-t.
- A kaptár és a HBase integrálásához a TÁROLÓ KEZELŐket használjuk a kaptárban.
- A Tárolókezelők a SERDE, az InputFormat, az OutputFormat kombinációja, amely bármilyen külső entitást elfogad a táblázatban a Kaptárban.
- Ez a szolgáltatás tehát segíti a felhasználót az SQL lekérdezések kiadásában, akár a Hadoopban, akár a NOSQL alapú adatbázisban, például HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Most megvizsgálunk egy példát a Hive és a HBase összekapcsolására a HiveStorageHandler használatával:
- Először létre kell hoznunk a Hbase táblát a parancs segítségével.
hozzon létre „hallgató”, „személyes információ”, „részleg információ”
-> A személyes adatok és a részvételi információk két különböző oszlopcsaládot hoznak létre a Diák táblázatban.
- Néhány adatot be kell illesztenünk a Diáktáblába. Például, az alábbiakban említettek szerint.
tedd a 'hallgató', 'sid01', 'személyes információ: név', 'Ram'
tedd a 'diák', 'sid01', 'személyes információ: mailid', ' '
tedd a 'diák', 'sid01', 'deptinfo: deptname', 'Java' feliratot
tedd a 'Student', 'sid01', 'deptinfo: joinyear', '1994' címet
-> Hasonlóképpen tudunk adatokat készíteni a sid02, sid03 adatokról …
- Most létre kell hoznunk Hive táblázatot, amely a HBase táblára mutat.
- A Hbase minden oszlopához létrehozzunk egy adott táblát ehhez az oszlophoz a Hive-ben. Ebben az esetben 2 táblát hozunk létre a Hive-ben.
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Hasonlóképpen el kell készítenünk a kaptárban egy részletes információs táblát.
- Most SQL lekérdezést írhatunk a kaptárba, az alábbiak szerint.
select * from student_hbase;
Ily módon integrálhatjuk a Hive-t a HBase-vel.
Következtetés - Hive vs HBase
Amint azt tárgyaltuk, mindkettő különböző technológiák, amelyek eltérő funkciókat biztosítanak, ha a Hive SQL nyelv használatával működik, és HQL és HBase néven is kulcs-érték párokat használhat az adatok elemzésére. A Hive és a HBase jobban működik, ha kombinálódnak, mert a Hive alacsony késleltetéssel rendelkezik, és hatalmas mennyiségű adatot képes feldolgozni, de nem tudják naprakész adatokat tartani, és a HBase nem támogatja az adatok elemzését, de nagy mennyiségben támogatja a sor szintű frissítéseket az adatok.
Ajánlott cikk
Ez egy útmutató a Hive vs HBase, azok jelentésének, a fej-fej összehasonlításának, a legfontosabb különbségeknek, az összehasonlító táblázatnak és a következtetéseknek. A következő cikkeket is megnézheti további információkért -
- Apache Pig vs Apache Hive - A 12 legfontosabb különbség
- Tudja meg a 7 legjobb különbséget a Hadoop és a HBase között
- Az Apache Hive és az Apache HBase 12 legfontosabb összehasonlítása (Infographics)
- Hadoop vs Hive - derítse ki a legjobb különbségeket