
Bevezetés a kaptár-építészetbe
A Hive Architecture a Hadoop ökoszisztéma tetején épül. A kaptár gyakran kölcsönhatásba lép a Hadoop-tal. Az Apache Hive együttműködik mind a domain SQL adatbázis rendszerrel, mind a Map-redukcióval. A kaptár alkalmazások különféle nyelveken írhatók, például Java, python. A kaptár architektúrája megmutatja, hogyan kell a kaptár nyelvet írni, és hogyan történik a programozó közötti interakció a parancssori felületen. A kaptár lekérdezési nyelve elvégzi az összes Hadoop-fürt feladat átalakítását a térkép-csökkentés segítségével. Mivel mindannyian tudtuk, hogy Hadoop a nagy adatok elosztott környezetben történő feldolgozására nyílt forráskódú keretet képez. A kaptár használatával rugalmas a lekérdezés kezelése és végrehajtása, valamint jó támogató olyan funkciók elvégzésére, mint például a beágyazás és az ad-hoc lekérdezések. Ez a cikk rövid bevezetést nyújt a kaptár architektúrájához, amely a Hadoop rétegen található, hogy nagy adatokon összegyűjtse.
Kaptár építészet annak alkatrészeivel
A kaptár nagy szerepet játszik az adatok elemzésében és az üzleti intelligencia integrációjában, és támogatja a fájl formátumokat, például a szöveges fájlt, az rc fájlt. A Hive elosztott rendszert használ a lekérdezések feldolgozására és végrehajtására, és a tárolást végül a lemezen végzik, és végül egy térkép-csökkentési keretrendszer segítségével dolgozzák fel. Megoldja a térkép-csökkentés és a kaptár alatt található optimalizálási problémát kötegelt munkák elvégzésében, amelyeket a munkafolyamat világosan ismertet. Itt a metatár tárolja a séma információkat. Az Apache Tez nevű keretet valós idejű lekérdezések teljesítményére tervezték.
A kaptár főbb elemei az alábbiakban találhatók:
- Kaptár ügyfelek
- Kaptári szolgáltatások
- Kaptár tárolása (Meta tárolás)
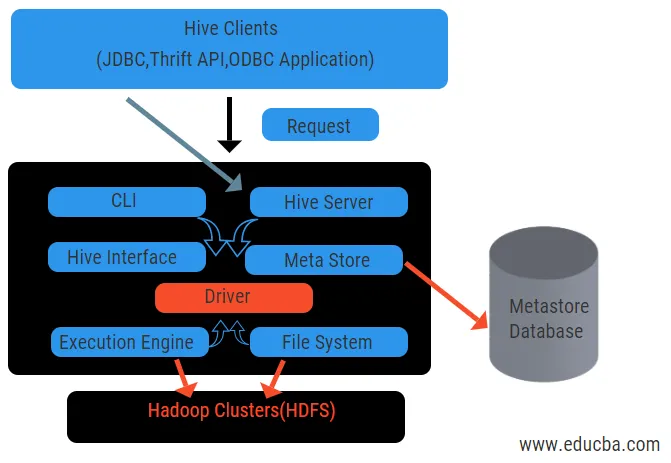
A fenti ábra a Kaptár és annak alkotóelemeinek architektúráját mutatja.
Kaptár ügyfelek:
Tartalmazzák a Thrift alkalmazást az egyszerű kaptárparancsok végrehajtására, amelyek python, ruby, C ++ és illesztőprogramok számára elérhetők. Ezek az ügyfélalkalmazások előnyei vannak a lekérdezések végrehajtásának a kaptárban. A Hive háromféle ügyfél-kategorizálást végez: takarékos ügyfelek, JDBC és ODBC kliensek.
Kaptár szolgáltatások:
Az összes lekérdezés feldolgozására a kaptár számos szolgáltatással rendelkezik. Az összes funkciót a felhasználó könnyen meghatározhatja a kaptárban. Lássuk röviden az összes ilyen szolgáltatást:
- Parancssori felület (felhasználói felület): Lehetővé teszi a felhasználó és a kaptár közötti interakciót, ez egy alapértelmezett héj. Ez egy grafikus felhasználói felületet biztosít a kaptár parancssorának és a kaptár betekintésének végrehajtásához. Webes felületeket (HWI) is használhatunk a webböngészővel történő lekérdezések és interakciók benyújtására.
- Kaptár-illesztőprogram: Különféle forrásokból és ügyfelekről kap lekérdezéseket, például a takarékosság-kiszolgálótól, és tárolja, és letölti az ODBC és JDBC illesztőprogramokon, amelyek automatikusan kapcsolódnak a kaptárhoz. Ez a komponens szemantikai elemzést végez, amikor a lekérdezést elemző metastore táblázatait látja. Az illesztőprogram a fordító segítségével segíti az elemzőt, a Tervezőt, a MapReduce jobok végrehajtását és az optimalizálót.
- Kompilátor: A lekérdezés elemzését és szemantikai folyamatát a fordító hajtja végre. Konvertálja a lekérdezést egy absztrakt szintaxis fává, majd a kompatibilitást újra DAG-ként. Az optimalizáló viszont felosztja a rendelkezésre álló feladatokat. A végrehajtó feladata a feladatok futtatása és a feladatok folyamatos ütemezésének figyelemmel kísérése.
- Végrehajtó motor: Az összes lekérdezést végrehajtó motor dolgozza fel. A DAG szakasz terveket a motor hajtja végre, amelyek segítenek a rendelkezésre álló szakaszok közötti függőségek kezelésében és a megfelelő összetevőn történő végrehajtásában.
- Metastore: Központi lerakatként szolgál a metaadatok összes strukturált információjának tárolására, és ez szintén fontos szempont a kaptár számára, mivel olyan információkkal rendelkezik, mint például táblázatok és partíciós részletek, valamint a HDFS fájlok tárolása. Más szavakkal, azt kell mondanunk, hogy a metastore táblázatok névtereként működik. A Metastore külön adatbázisnak tekinthető, amelyet más összetevők is megosztanak. A Metastore két részből áll, úgynevezett service és backlog storage.
A kaptár adatmodellje partíciókra, vödrökre és táblázatokra van felépítve. Mindezek szűrhetők, partíciókulccsal rendelkeznek és a lekérdezés kiértékeléséhez. A kaptárkérdezés a Hadoop kereten működik, nem pedig a hagyományos adatbázison. A kaptárkiszolgáló egy felület egy távoli kliens között, amely a kaptárhoz kérdezi. A végrehajtó motor teljesen be van ágyazva a kaptárkiszolgálóba. Találhat kaptár alkalmazást a gépi tanulásban, az üzleti intelligencia az észlelési folyamatban.
A kaptár munkafolyamata:
A kaptár kétféle üzemmódban működik: interaktív módban és nem interaktív módban. A korábbi mód lehetővé teszi, hogy az összes kaptárparancs közvetlenül a kaptárhéjba kerüljön, míg a későbbi típus konzol módban hajtja végre a kódot. Az adatokat partíciókra osztják, amelyek tovább osztódnak vödrökre. A végrehajtási tervek az összesítésen és az adatok eltorzulásain alapulnak. A kaptár használatának további előnye, hogy egyszerűen feldolgozza a nagy mennyiségű információt, és több felhasználói felülettel rendelkezik.
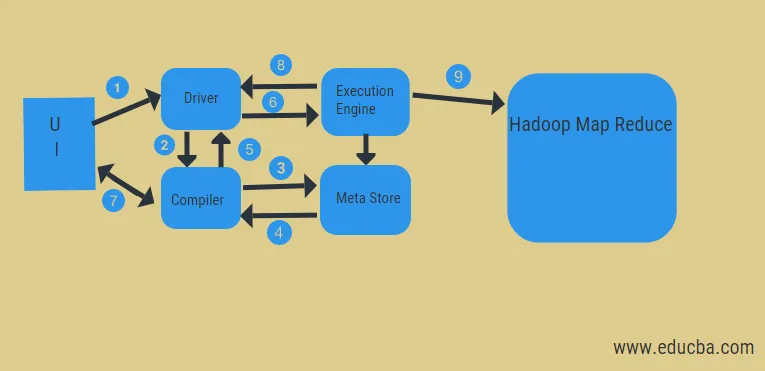
A fenti ábra alapján bepillantást nyerhetünk a Hadoop rendszerrel történő adatáramlásba a kaptárban.
A lépések a következők:
- hajtsa végre a lekérdezést felhasználói felületről
- szerezzen egy tervet a vezető feladatok DAG szakaszaiból
- lekérheti a metaadat-kérelmet a metatárból
- küldjön metaadatokat a fordítóról
- visszaadja a tervet a sofőrnek
- Végrehajtási terv a végrehajtó motorban
- az eredmények lekérése a megfelelő felhasználói lekérdezéshez
- az eredmények kétirányú továbbítása
- végrehajtó motor feldolgozása HDFS-ben a térkép-csökkentés és letöltés eredményekkel a job tracker által létrehozott adatcsomópontokból. csatlakozóként működik a Hive és a Hadoop között.
A végrehajtó motor feladata a csomópontokkal való kommunikáció, hogy megkapja a táblázatban tárolt információkat. Itt olyan SQL műveleteket hajtanak végre, mint például a létrehozás, a csepp és a módosítás, hogy elérjék a táblázatot.
Következtetés:
Megvizsgáltuk a Hive Architecture-t és azok működési folyamatát, a kaptár alapvetően petabájt mennyiségű adatot hajt végre, és így ez egy adattárház csomag a Hadoop platformon. Mivel a kaptár jó választás a nagy adatmennyiség kezelésére, elősegíti az adatok előkészítését az SQL interfész útmutatóval a MapReduce problémák megoldásában. Az Apache kaptár egy ETL eszköz a strukturált adatok feldolgozásához. A kaptár-építészet működésének ismerete segít a vállalati embereknek megérteni a kaptár működésének alapelveit, és jó kezdetben van a kaptár programozásával.
Ajánlott cikkek:
Ez egy útmutató a kaptár építészetéhez. Itt a kaptár architektúráját, a különféle összetevőit és a kaptár munkafolyamatait tárgyaljuk. a következő cikkeket is megnézheti további információkért -
- Hadoop építészet
- Ruby felhasználás
- Mi az a C ++?
- Mi a MySQL adatbázis?
- Kaptárrendelés