

Bevezetés az RDBMS interjúkérdéseire és válaszaira
Tehát ha munkainterjúra készül az RDBMS-ben. Biztos vagyok benne, hogy meg akarja tudni a leggyakoribb 2019-es RDBMS-interjúkérdéseket és válaszokat, amelyek segítenek könnyedén feltörni az RDBMS-interjút. Az alábbiakban felsoroljuk a legmegfelelőbb RDBMS-interjúkérdések és válaszok listáját.
Ennélfogva hajlamosak a 2019. évi RDBMS interjúkérdések kérdéseit hozzáadni, amelyeket főként egy interjúban kérnek fel
1.Melyek az RDBMS különféle jellemzői?
Válasz:
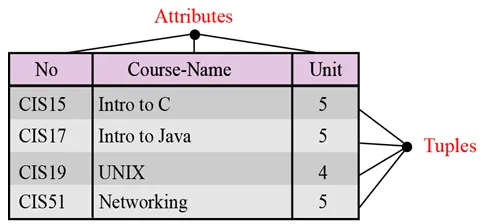
Név. A relációs adatbázisban szereplő minden relációnak nevével kell rendelkeznie, amely minden más kapcsolat között egyedi.
Attribútumokat. A reláció minden oszlopát attribútumnak nevezzük.
Sorok. A reláció minden egyes sorát tuple-nak nevezzük. Egy elem meghatározza az attribútum értékek gyűjteményét.
2. Magyarázza meg az ER modellt?
Válasz:
Az ER modell egy entitás-kapcsolat modell. Az ER modell egy valós világon alapul, amely entitásokból és kapcsolatobjektumokból áll. Az entitásokat egy adatbázisban egy attribútumkészlet ábrázolja.
3. Definiálja az objektum-orientált modellt?
Válasz:
Az objektum-orientált modell objektumok gyűjteményein alapul. Az objektum olyan értékeket fogad el, amelyeket például az objektumon belül változók tárolnak. Az azonos típusú értékekkel és pontosan ugyanazokkal a módszerekkel rendelkező objektumokat osztályokba csoportosítják.
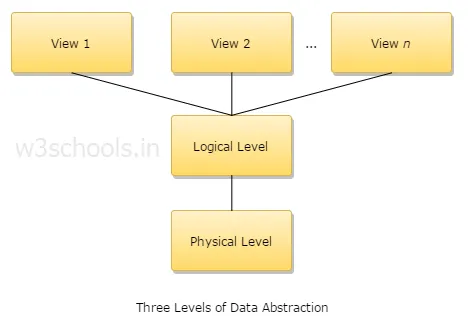
4. Magyarázza meg az absztrakció három szintjét?
Válasz:
1. Fizikai szint: Ez az absztrakció legalacsonyabb szintje, és leírja az adatok tárolásának módját.
2. Logikai szint: Az absztrakció következő szintje logikus, leírja, hogy milyen típusú adatokat tárolnak az adatbázisban, és milyen kapcsolat áll fenn ezen adatok között.
3. Nézet szint: Az absztrakció legmagasabb szintje, és leírja az egyetlen teljes adatbázist.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5.Melyek a Codd 12 különféle szabálya a relációs adatbázisra?
Válasz:
Codd 12 szabálya tizenhárom szabályból áll (nullától tizenkettőig számozva), amelyeket Edgar F. Codd javasolta.
Codd szabályai: -
0. szabály: A rendszernek relacionálisnak, adatbázisnak és kezelési rendszernek kell minősülnie.
1. szabály: Az információs szabály: Az adatbázisban szereplő minden információt egyedileg kell képviselni, elsősorban a táblázat különböző sorain lévő oszloppozíciók neveinek értékét.
2. szabály: A garantált hozzáférési szabály: Minden adatnak behatolónak kell lennie. Azt mondja, hogy az adatbázis minden skaláris értékének helyesen / logikailag címezhetőnek kell lennie.
3. szabály : A null értékek szisztematikus kezelése: A DBMS-nek lehetővé kell tennie, hogy minden egyes null maradjon nulla.
4. szabály: Aktív online katalógus (adatbázis felépítése) a relációs modell alapján: A rendszernek támogatnia kell egy online, relációs stb. Struktúrát, amely rendszeres lekérdezéssel lehetővé teszi az engedélyezett felhasználók számára.
5. szabály: Az adatok átfogó alnyelve: A rendszernek támogatnia kell legalább egy relációs nyelvet, amely:
1.Van egy lineáris szintaxis
2.Mely interaktív módon és alkalmazási programokban egyaránt felhasználható,
3.Támogatja az adatmeghatározási műveleteket (DDL), az adatkezelési műveleteket (DML), a biztonsági és integritási korlátozásokat, valamint a tranzakciókezelési műveleteket (kezdés, átadás és visszatekerés).
6. szabály: A nézetet frissítő szabály: Az összes nézetet, amelyet elméletileg javítanak, a rendszernek frissítenie kell.
7. szabály: Magas szintű beillesztés, frissítés és törlés: A rendszernek támogatnia kell az operátorok beszúrását, frissítését és törlését.
8. szabály: A fizikai adatok függetlensége: A fizikai szint módosítása (az adatok tárolásának módja, tömbök vagy csatolt listák stb. Felhasználásával) nem igényli az alkalmazás módosítását.
9. szabály: Logikai adatok függetlensége: A logikai szint (táblázatok, oszlopok, sorok stb.) Módosítása nem igényli az alkalmazás módosítását.
10. szabály: Az integritás függetlensége: Az integritás korlátozásait az alkalmazási programoktól külön kell azonosítani, és a katalógusban tárolni.
11. szabály: Terjesztési függetlenség: Az adatbázis egyes részeinek különböző helyekre történő eloszlása nem lehet látható az adatbázis felhasználóinak.
12. szabály: A nem szubverziós szabály: Ha a rendszer alacsony szintű (azaz rekordok) felületet biztosít, akkor ez a felület nem használható a rendszer felborításához.
6.Mit jelent a normalizálás? és mi magyarázza a különböző normalizációs formákat.
Válasz:
Az adatbázis normalizálása az adatok szervezésének folyamata az adat redundanciájának minimalizálása érdekében. Ez pedig biztosítja az adatok konzisztenciáját. Az adat redundanciával sok probléma merül fel, például a lemezterület-pazarlás, az adatok inkonzisztenciája, a DML (Data Manipulation Language) lekérdezések lassúvá válnak. Különböző normalizálási formák léteznek: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Az egyes oszlopok adatainak atomi szám többszörös értékeinek kell lennie, vesszővel elválasztva. A táblázat nem tartalmaz ismétlődő oszlopcsoportokat. Az egyes rekordok azonosítása az elsődleges kulcs felhasználásával történik.
2. 2NF: - A táblázatnak meg kell egyeznie az 1NF összes feltételével, és a redundáns adatokat külön táblába kell helyeznie. Ezenkívül kapcsolatot hoz létre e táblák között idegen kulcsok segítségével.
3. 3NF: - A 3NF asztaloknak teljesíteniük kell az 1NF és a 2NF összes feltételét. A 3NF nem tartalmaz olyan attribútumokat, amelyek részben függnek az elsődleges kulcstól.
7.Define elsődleges kulcs, idegen kulcs, jelölt kulcs, szuper kulcs?
Válasz:
Elsődleges kulcs: az elsődleges kulcs az a kulcs, amely nem engedélyezi a másodpéldányokat és a null értékeket. Az elsődleges kulcs meghatározható oszlopszinten vagy táblázat szinten. Táblázatonként csak egy elsődleges kulcs megengedett.
Idegen kulcs: az idegen kulcs csak a hivatkozott oszlopban szereplő értékeket engedélyezi. Lehetővé teszi duplikált vagy null értékeket. Meg lehet határozni oszlopszintként vagy táblázatszintként. Hivatkozhat az egyedi / elsődleges kulcs oszlopára.
Jelölt kulcs: A jelölt kulcs minimális szuper kulcs, nincs megfelelő alcsoport a jelölt kulcs attribútumok lehetnek szuper kulcs.
Szuper kulcs: A szuper kulcs egy relációs séma attribútumainak halmaza, amelyen a séma összes attribútuma részben függ. Két sornak nem lehet ugyanaz a szuperkulcs-attribútumainak értéke.
8.Milyen típusú indexek vannak?
Válasz:
Az indexek a következők: -
Fürtözött index: - Az az index, amelyen az adatokat fizikailag tárolják a lemezen. Ezért csak egy fürtözött index hozható létre az adatbázis táblához.
Nem fürtözött index: - Nem határozza meg a fizikai adatokat, de meghatározza a logikai sorrendet. Általában a B-fa vagy a B + fa jön létre erre a célra.
9.Melyek az RDBMS előnyei?
Válasz:
• Az redundancia ellenőrzése.
• Az integritás érvényesíthető.
• Az inkonzisztencia elkerülhető.
• Az adatok megoszthatók.
• A szabvány érvényesíthető.
10.Névezze az RDBMS egyes alrendszereit?
Válasz:
Bemenet-kimenet, biztonság, nyelvfeldolgozás, tároláskezelés, naplózás és helyreállítás, disztribúció-vezérlés, tranzakció-vezérlés, memóriakezelés.
11. Mi az a Buffer Manager?
Válasz:
A Pufferkezelőnek sikerül adatokat gyűjtenie a lemeztárolóból a fő memóriába, és eldönti, hogy mely adatoknak kell lennie a gyorsítótárban a gyorsabb feldolgozáshoz.
Ajánlott cikk
Ez egy útmutató az RDBMS interjúkérdések és válaszok listájához, így a jelölt könnyen meg tudja oldani ezeket az RDBMS interjúkérdéseket. A következő cikkeket is megnézheti további információkért -
- A legfontosabb adatanalitikai interjúkérdések
- 13 Csodálatos adatbázis-tesztelési interjúkérdések és válaszok
- A 10 legnépszerűbb interjúkérdés és válaszok
- 5 Hasznos SSIS interjú kérdés és válasz