
A neurális hálózati algoritmusok áttekintése
- Először tudjuk meg, mit jelent egy neurális hálózat? A neurális hálókat az agy biológiai ideghálójai inspirálják, vagy mondhatjuk az idegrendszert. Nagyon sok izgalmat generált, és a kutatások továbbra is folynak az iparban a Géptanulás ezen részhalmazán.
- Az idegi hálózat alapvető számítási egysége egy neuron vagy csomópont. Értékeket kap más neuronoktól és kiszámítja a kimenetet. Minden csomópont / neuron a súly (w) -hoz van társítva. Ezt a súlyt az adott neuron vagy csomópont relatív fontosságára vonatkoztatva adjuk meg.
- Tehát, ha f csomópontfüggvényt veszünk, akkor az f csomópont függvény az alábbiak szerint szolgáltatja a kimenetet: -
A neuron teljesítménye (Y) = f (w1.X1 + w2.X2 + b)
- Ahol w1 és w2 súlya, X1 és X2 numerikus bemenetek, míg b a torzítás.
- A fenti f funkció nemlineáris függvény, amelyet aktiválási függvénynek is nevezünk. Alapvető célja a nemlinearitás bevezetése, mivel szinte minden valós adat nemlineáris, és azt akarjuk, hogy az idegsejtek megtanulják ezeket a reprezentációkat.
Különböző neurális hálózat algoritmusok
Nézzük meg most négy különféle neurális hálózat algoritmust.
1. Színátmenet leszállás
Ez az egyik legnépszerűbb optimalizálási algoritmus a gépi tanulás területén. A gépi tanulási modell képzése során használják. Egyszerű szavakkal: Alapvetően az együtthatók olyan értékének meghatározására használják, amely egyszerűen csak a lehető legkisebbre csökkenti a költségfüggvényt. Először is, néhány paraméterértéket határozunk meg, majd egy kalkulus használatával megismételjük az értékeket úgy, hogy az elveszett funkció csökken.
Most menjünk arra a részre, ami a gradiens ?. Tehát egy gradiens jelentősen azt jelenti, hogy bármely funkció kimenete megváltozik, ha kicsit csökkentjük a bemenetet, vagyis más szavakkal hívhatjuk le a lejtőn. Ha a meredekség meredek, akkor a modell gyorsabban megtanul, hasonlóan egy modell leállítja a tanulást, ha a meredekség nulla. Ennek oka az, hogy egy minimalizáló algoritmus minimalizálja az adott algoritmust.
A következő helyzet meghatározására szolgáló képlet alatt a gradiens leszállás esetén látható.
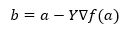
Ahol b a következő helyzet
a a jelenlegi helyzet, a gamma egy várakozási funkció.
Tehát, amint láthatja, a gradiens leszállás nagyon jó technika, de sok olyan területen van, ahol a gradiens leszállás nem működik megfelelően. Néhány közülük az alábbiakban található:
- Ha az algoritmust nem hajtják végre megfelelően, akkor felmerülhet valami hasonló a gradiens eltűnésének problémájához. Ezek akkor fordulnak elő, ha a gradiens túl kicsi vagy túl nagy.
- Problémák merülnek fel, amikor az adatok elrendezése nem konvex optimalizálási problémát jelent. A megfelelő színátmenet csak olyan problémákkal működik, amelyek a konvex optimalizált probléma.
- Az algoritmus alkalmazása során az egyik nagyon fontos tényező az erőforrások. Ha kevesebb memória van hozzárendelve az alkalmazáshoz, kerüljük a gradiens leszállási algoritmust.
2. Newton-módszer
Ez egy másodrendű optimalizálási algoritmus. Második rendnek hívják, mert felhasználja a hessiai mátrixot. Tehát a Hessian mátrix nem más, mint egy skaláris értékű függvény másodrendű részleges deriváltjainak négyzetes mátrixa. Newton módszerének optimalizálási algoritmusában az kettős differenciálódású függvény első deriváltjára alkalmazzuk, hogy megtalálja a gyökereket. / álló helyek. Most kezdjük bele a Newton módszerének az optimalizáláshoz szükséges lépéseibe.
Először kiértékeli a veszteségi mutatót. Ezután ellenőrzi, hogy a megállási kritériumok igazak-e vagy sem. Ha hamis, akkor kiszámítja Newton edzési irányát és edzési sebességét, majd javítja a neuron paramétereit vagy súlyát, és ismét ugyanaz a ciklus folytatódik. Tehát most azt mondhatja, hogy kevesebb lépést igényel a gradiens leszállásához képest, hogy elérje a minimumot. a függvény értéke. Bár kevesebb lépést igényel a gradiens leszállási algoritmushoz képest, mégsem használják széles körben, mivel a hessian és annak inverzének pontos kiszámítása számítási szempontból nagyon költséges.
3. Konjugált színátmenet
Ez egy módszer, amelyet valamelynek tekinthetünk a gradiens leszármazás és Newton módszer között. A fő különbség az, hogy felgyorsítja a lassú konvergenciát, amelyet általában a gradiens leszálláshoz társítunk. Egy másik fontos tény, hogy mind lineáris, mind nemlineáris rendszerekhez használható, és ez egy iteratív algoritmus.
Ezt Magnus Hestenes és Eduard Stiefel fejlesztették ki. Mint fentebb már említettük, hogy gyorsabb konvergenciát hoz létre, mint a gradiens leszállás, Ennek oka az, hogy a Conjugate Gradient algoritmusban a keresést a konjugált irányokkal együtt végzik, amelynek eredményeként gyorsabban konvergál, mint a gradiens leszállási algoritmusok. Fontos megjegyezni, hogy a γ konjugátum paraméter.
Az edzési irányt periodikusan visszaállítják a gradiens negatívjára. Ez a módszer hatékonyabb, mint a gradiens leszállás a neurális hálózat képzésében, mivel nem igényli a hessiai mátrixot, amely növeli a számítási terhelést, és gyorsabban konvergál, mint a gradiens leszállás. Helyénvaló használni nagy ideghálózatokban.
4. Kvázi-Newton módszer
Ez egy Newton-módszer alternatív megközelítése, mivel most tisztában vagyunk azzal, hogy Newton-módszer számítási szempontból drága. Ez a módszer annyiban oldja meg ezeket a hátrányokat, hogy a Hessian mátrix kiszámítása és az inverz közvetlen kiszámítása helyett ez a módszer ehhez az algoritmus minden iterációjához közelítést készít a Hessian inverzére.
Ezt a közelítést a veszteségfüggvény első deriváltjának felhasználásával számítják ki. Tehát azt mondhatjuk, hogy ez valószínűleg a legmegfelelőbb módszer nagy hálózatok kezelésére, mivel ez megtakarítja a számítási időt, és sokkal gyorsabb, mint a gradiens leszállás vagy a konjugált gradiens módszer.
Következtetés
Mielőtt befejeznénk ezt a cikket, hasonlítsuk össze a fent említett algoritmusok számítási sebességét és memóriáját. A memóriaigények szerint a gradiens leeresztése a legkevesebb memóriát igényli, és a leglassabb. Ezzel ellentétben Newton módszerének nagyobb számítási teljesítményre van szüksége. Tehát ezeket mindezt figyelembe véve a Quasi-Newton módszer a legmegfelelőbb.
Ajánlott cikkek
Ez egy útmutató a neurális hálózat algoritmusaihoz. Itt tárgyaljuk a neurális hálózati algoritmus áttekintését is, négy különféle algoritmussal együtt. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Gépi tanulás vs neurális hálózat
- Gépi tanulási keretek
- Neurális hálózatok vs mély tanulás
- K - klaszterezési algoritmus
- Útmutató a neurális hálózat osztályozásához