

Bevezetés a Hadoop építészetbe
A Hadoop Architecture egy nyílt forráskódú keret, amely elősegíti a nagy adatkészletek könnyű feldolgozását. Segít olyan alkalmazások létrehozásában, amelyek hatalmas adatokat dolgoznak fel nagyobb sebességgel. Az elosztott számítási koncepciókat használja, ahol az adatok a klaszter különböző csomópontjai között vannak elosztva. Azok az alkalmazások, amelyek a Hadoop használatával készültek, árucikkekkel rendelkező számítógépeket használnak. Ezek a számítógépek olcsón elérhetők a piacon. Ez az eredmény nagyobb számítási teljesítményt eredményez alacsony költséggel. A Hadoop-ban lévő összes adat a helyi fájlrendszer helyett a HDFS-en található. A HDFS egy Hadoop elosztott fájlrendszer. Ez a modell az Adatok lokalitásán alapul, ahol a számítási logikát az adatokat tartalmazó fürtben lévő csomópontoknak küldik el. Ez a logika nem más, mint a programot összeállító logika.
Hadoop építészet
Ennek az építkezésnek az az alapvető gondolata, hogy a teljes tárolás és feldolgozás két lépésben és két módon történjen. Az első lépés a feldolgozás, amelyet a Map csökkent programozás hajt végre, a második lépés az adatok tárolása, amelyet a HDFS-en végeznek. Mester-szolga architektúrával rendelkezik a tároláshoz és az adatok feldolgozásához. A Hadoop adattárolásának fő csomópontja a névcsomópont. Van egy mester csomópont, amely a Hadoop Map Reduce használatával felügyeli és párhuzamosítja az adatfeldolgozást. A rabszolgák más gépek a Hadoop klaszterben, amelyek segítenek az adatok tárolásában, és összetett számításokat végeznek. Minden szolga csomóponthoz hozzárendelt egy feladatkövető, és egy adatcsomóponthoz van egy feladatkövető, amely segíti a folyamatok futtatását és hatékony szinkronizálását. Az ilyen típusú rendszert felhőben vagy helyszínen is fel lehet állítani. A Név csomópont egyetlen hibapont, ha nem magas rendelkezésre állás üzemmódban fut. A Hadoop architektúra rendelkezik a Név készenléti csomópont karbantartásával is a rendszer megóvása érdekében a meghibásodásoktól. Korábban voltak másodlagos névcsomópontok, amelyek biztonsági másolatként működtek, amikor az elsődleges névcsomópont le volt állítva.
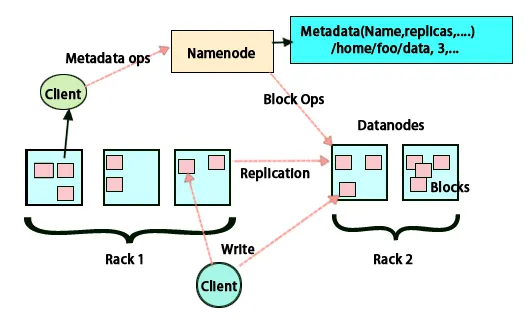
FSimage és napló szerkesztése
Az FSimage és a Szerkesztési napló biztosítja a fájlrendszer metaadatainak kitartását, hogy lépést tartsanak az összes információval, és a névcsomópont a metaadatokat két fájlban tárolja. Ezek a fájlok az FSimage és a szerkesztési napló. Az FSimage feladata, hogy egy adott pillanatban készítsen egy pillanatképet a fájlrendszerről. A rendszerben folyamatosan végrehajtott változásokról nyilvántartást kell vezetni. Ezeket a növekményes változásokat, például az átnevezést vagy a fájlhoz mellékelt adatokat a szerkesztési naplóban tárolják. A keretrendszer jobb lehetőséget kínál az új FSimage minden egyes létrehozása helyett, annál jobb lehetőség az adatok tárolása, míg egy új fájl az FSimage számára. Az FSimage új pillanatképet készít minden változtatáskor. Ha a Név csomópont meghiúsul, akkor visszaállíthatja az előző állapotát. A másodlagos névcsomópont frissítheti másolatát is, amikor változások történnek az FSimage-ban és szerkesztési naplókat. Így biztosítja, hogy annak ellenére, hogy a névcsomópont nem működik, a másodlagos névcsomópont jelenlétében nem vesznek el adatvesztés. A névcsomópont nem követeli meg, hogy ezeket a képeket újra kell tölteni a másodlagos névcsomóponton.
Adat replikáció
A HDFS célja az adatok gyors feldolgozása és megbízható adatok biztosítása. Az adatokat gépeken és nagy klaszterekben tárolja. Az összes fájlt blokkok sorozata tárolja. Ezeket a blokkokat megismételjük a hibatűrés érdekében. A blokk méretét és a replikációs tényezőt a felhasználók dönthetnek, és a felhasználói igényeknek megfelelően konfigurálhatók. Alapértelmezés szerint a replikációs tényező 3. A replikációs tényező a fájl létrehozásakor meghatározható, és később megváltoztatható. Az ezen replikákkal kapcsolatos minden döntést a névcsomópont hozza meg. A névcsomópont rendszeres időközönként továbbítja a pulzusokat és a blokk jelentést a fürt összes adatcsomópontjára. A szívverés vétele azt jelenti, hogy az adatcsomópont megfelelően működik. A blokkjelentés meghatározza az adatcsomóponton lévő összes blokk listáját.
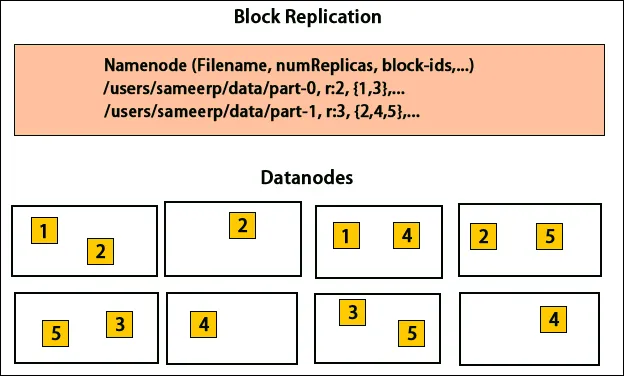
Replikák elhelyezése
A replikák elhelyezése nagyon fontos feladat a Hadoop számára a megbízhatóság és a teljesítmény szempontjából. Az összes különféle blokkot különféle állványokra helyezzük el. A replika elhelyezés megvalósítható megbízhatóság, rendelkezésre állás és a hálózati sávszélesség kihasználtság alapján. A számítógépek csoportja elosztható különféle állványok között. Ugyanazon rackre legfeljebb két csomópont helyezhető el. A harmadik replikát egy másik rack-re kell helyezni az adatok nagyobb megbízhatóságának biztosítása érdekében. Az állványon lévő két csomópont különféle kapcsolókkal kommunikál. A névcsomópont rack-azonosítóval rendelkezik minden adatcsomóponthoz. Az összes csomópont különféle állványokra helyezése megakadályozza az adatok elvesztését, és lehetővé teszi a sávszélesség felhasználását több állványból. Ez csökkenti az állványok közötti forgalmat és javítja a teljesítményt. Ezenkívül a rack meghibásodásának esélye is kevesebb, mint a csomópont meghibásodása. Csökkenti az összesített hálózati sávszélességet, amikor az adatokat két, nem pedig három egyedi rackről olvassa le.
Térkép csökkentése
A Map Reduce a HDFS-en tárolt adatok feldolgozására szolgál. Elosztott adatokat ír elosztott alkalmazások között, ami nagy mennyiségű adat hatékony feldolgozását biztosítja. Nagy fürtökön dolgoznak fel, és megbízható és hibatűrő árut igényelnek. A Map-redukció lényege három műveletből áll, mint például a leképezés, a párok összegyűjtése és a kapott adatok keverése.
Következtetés - Hadoop építészet
A Hadoop egy nyílt forráskódú keret, amely segíti a hibatűrő rendszert. Nagy mennyiségű adatot képes tárolni, és elősegíti a megbízható adatok tárolását. Az adatok HDFS-ben való tárolása és feldolgozása a térképen keresztül csökkenti a megfelelő és hatékony működés elősegítését. Ez egy olyan architektúrával rendelkezik, amely elősegíti az összes adatblokk kezelését, valamint a legfrissebb másolatot is, mivel azt az FSimage-ban tárolja és a naplókat szerkeszti. A replikációs tényező elősegíti az adatok másolatát is, és ha hibát észlel, akkor visszakapja azokat. A HDFS az eltávolított fájlokat is áthelyezi a kukába, a hely optimális felhasználása érdekében.
Ajánlott cikkek
Ez egy útmutató a Hadoop Architecture-hez. Itt megvitattuk az építészet, a térképcsökkentés, a replikák elhelyezését, az adatok replikációját. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Legyen Hadoop Fejlesztő
- Bevezetés az Android-hoz
- Mi az a Tableau? | Áttekintés
- Mi a MapReduce a Hadoopban?