
Bevezetés az R CSV fájlokba
A CSV fájlokat széles körben használják az információk táblázatos formában történő tárolására, mindegyik sor adatrekordként. Annak érdekében, hogy az R-ben adatokat olvashassunk, írhassunk vagy manipulálhassunk, rendelkeznünk kell bizonyos adatokkal. Az adatok megtalálhatók az interneten, vagy különféle forrásokból, például felmérésekből is összegyűjthetők. Az R használatával elolvashatjuk, írhatjuk és szerkeszthetjük a külső környezetben tárolt adatokat. Az R különféle formátumokban képes adatokat olvasni és írni, például XML, CSV és Excel. Ebben a cikkben meglátjuk, hogyan lehet R felhasználni CSV fájlok olvasására, írására és különféle műveletek végrehajtására.
CSV fájl létrehozása R-ben
Ebben a szakaszban meglátjuk, hogyan lehet adatkeretet létrehozni és exportálni a CSV-fájlba R-ben. Az elsőben létrehozunk egy adatkeretet, amely az alkalmazotti és a megfelelő fizetés változóiból áll.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
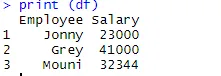
Az adatkeret létrehozása után itt az ideje, hogy az R exportáló funkciójával hozzuk létre a CSV fájlt R-ben. Az adatkeret CSV-be történő exportálásához az alábbi kódot használhatjuk.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
A fenti kódsorban megadtunk egy elérési útvonalat adathírnévünkhöz, és az adatkeretet CSV formátumban tároltuk. A fenti esetben a CSV fájlt a személyes asztalomra mentették. Ezt az adott fájlt az oktatóanyagban fogjuk használni több művelet végrehajtására.
CSV fájlok olvasása R-ben
Annak ellenére, hogy az R segítségével elemzést végezzünk, sok esetben a CSV-fájlból ki kell olvasnunk az adatokat. Az R nagyon megbízható a CSV fájlok olvasása közben. A fenti példában létrehoztuk a fájlt, amelyet az read.csv parancs segítségével olvasunk. Az alábbiakban látható példa erre R-ben.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

A fenti parancs beolvassa az Employee.csv fájlt, amely elérhető az asztalon, és megjeleníti azt az R stúdióban. A fejléc parancs azt jelenti, hogy a fejléc rendelkezésre áll az adatkészlet számára, a sep parancs pedig azt jelenti, hogy az adatokat vessző választja el egymástól.
Írjon CSV fájlokat R-be
A CSV-fájlba való írás az R-ben rendelkezésre álló egyik leghasznosabb funkció az adatelemzők számára. Ez felhasználható szerkesztett CSV-fájl új CSV-fájlba történő írására az adatok elemzése céljából. A Write.csv parancs a fájl CSV-re történő írására szolgál.
Az adatkeret alábbi df kódjában, amelyben az adatok rendelkezésre állnak, a függelék azt használja, hogy meghatározza, hogy az új fájlt a régi fájlhoz történő hozzáfűzés vagy felülírás helyett hozzák létre. Hamis hozzáfűzés azt sugallja, hogy létrejön egy új CSV fájl. A Sep vesszővel elválasztott mezőt jelöli.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV műveletek
A CSV műveletekhez az adatok ellenőrzéséhez szükségesnek kell lenniük, miután a rendszerbe lettek töltve. Az R több beépített funkcióval rendelkezik az adatok ellenőrzésére és ellenőrzésére. Ezek a műveletek teljes információt nyújtanak az adatkészlettel kapcsolatban.
Az egyik leggyakrabban használt parancs egy összefoglaló.
> summary(df)
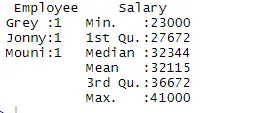
Az összefoglaló parancs oszlopkoncentrált statisztikákat szolgáltat nekünk. A numerikus változó statisztikai módon kerül leírásra, amely statisztikai eredményeket tartalmaz, például átlagot, min, mediánt és max. A fenti példában két, a Munkavállaló és a Fizetés változót szétválasztunk, és a numerikus változó, a Fizetés statisztikáit mutatjuk be nekünk.
A View () parancs segítségével az adatkészlet egy másik lapon nyitható meg, és manuálisan ellenőrizhető.
> View(df)

A Str függvény további részleteket nyújt a felhasználók számára az adatkészlet oszlopáról. Az alábbi példában láthatjuk, hogy az Alkalmazott változó tényezője adattípus, és a Fizetés változónak int (egész) az adattípusa.
> str(df)

Sok esetben a nagy adatkészlet esetében a rendelkezésre álló sorok számát kell látnunk, amelyre használhatjuk a nrow () parancsot. Kérjük, olvassa el az alábbi példát.
> # to show the total number of rows in the dataset
> nrow(df)

Az oszlopok teljes számának megjelenítéséhez hasonlóan használhatjuk az ncol () parancsot is
> ncol(df)

R lehetővé teszi a kívánt sorok megjelenítését az alábbi parancs segítségével. Amikor n számú sor rendelkezésre áll az adatkészletben, meghatározhatjuk a megjelenítendő sorok tartományát.
> # to display first 2 rows of the data
> df(1:2, )

Az adatműveletet a nagy adatkészlettel hajtjuk végre. A szemléltetés céljából letöltöttem az NI irányítószámú nyílt forrású adatkészletet az internetről.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
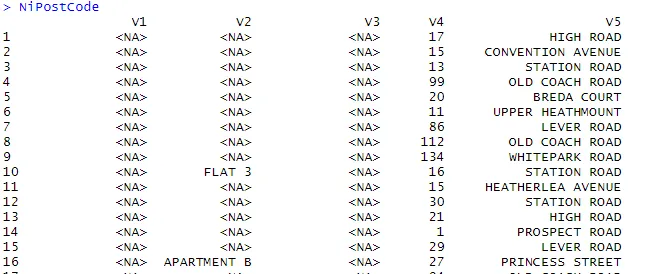
A fenti adatkészletben láthatjuk, hogy hiányoznak a fejlécek nevei, és sok nullérték van jelen. Az adatkészletet meg kell tisztítani, hogy készen álljon az elemzésre. A következő lépésben a fejlécek ennek megfelelően nevek lesznek.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Most számoljuk meg az adatkeretben hiányzó értékek számát, majd távolítsuk el őket ennek megfelelően.
> # count of all missing values
> table(is.na (NiPostCode))

A fenti parancsból láthatjuk, hogy az üres keretekben az üres mezők száma vagy az NA száma megközelíti az 5445148-at. Az összes nullérték eltávolítása hatalmas mennyiségű adatvesztést eredményez, ezért bölcs dolog eltávolítani azokat az oszlopokat, ahol több mint a fele az adatok 50% -át hiányzik.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Következtetés
Ebben az oktatóanyagban láttuk, hogyan lehet CSV fájlokat létrehozni, elolvasni és csatolni az R műveletekkel. Megtanultuk, hogyan lehet új adatkészletet létrehozni R formátumban, majd azt CSV formátumba importálni. Több műveletet is láthattunk, például a fejléc átnevezését és a sorok és oszlopok számát.
Ajánlott cikkek
Ez egy útmutató az R CSV fájlokhoz. Itt tárgyaljuk a CSV fájl létrehozását, olvasását és írását R formátumban a CSV műveletekkel. A következő cikkben további információkat is megnézhet -
- JSON vs CSV
- Adatbányászati folyamat
- Karrier az adatelemzésben
- Excel vs CSV