

Bevezetés a lineáris regresszió elemzésébe
Gyakran zavaró, ha elsajátítunk néhány fogalmat, amely szintén része a mindennapi életünknek. De ez nem jelent problémát, segíthetjük és fejleszteni tudjuk magunkat a mindennapi tevékenységeinkből való tanuláshoz, csupán a dolgok elemzésével, és nem félünk kérdéseket feltenni. Miért befolyásolja az ár az áruk keresletét, miért befolyásolja a kamatlábak változása a pénzkínálatot? Mindezekre egy egyszerű, lineáris regressziónak nevezett megközelítéssel lehet válaszolni. Az egyetlen komplexitás, amelyet a lineáris regressziós elemzés során érez, a függő és független változók azonosítása.
Meg kell találnunk, hogy mi befolyásolja, és a probléma felét megoldjuk. Látnunk kell, hogy az ár vagy a kereslet befolyásolja-e egymás viselkedését. Miután megismertük, melyik a független változó és a függő változó, érdemes megvizsgálnunk az elemzést. A regressziós elemzésnek többféle típusa elérhető. Ez az elemzés a rendelkezésre álló változóktól függ.
A regressziós elemzés 3 típusa
Ez a három regressziós elemzés a valós világban maximálisan felhasználható eseteket tartalmaz, különben több mint 15 típusú regressziós elemzés létezik. A regressziós elemzés típusai, amelyeket megvitatunk:
- Lineáris regressziós elemzés
- Többszörös lineáris regressziós elemzés
- Logisztikus regresszió
Ebben a cikkben az egyszerű lineáris regresszió elemzésére összpontosítunk. Ez az elemzés segít azonosítani a független tényező és a függő tényező kapcsolatát. Egyszerűbben fogalmazva: a regressziós modell segít bebizonyítani, hogy a független tényező változásai hogyan befolyásolják a függő tényezőt. Ez a modell többféle módon segít bennünket, például:
- Ez egy egyszerű és hatékony statisztikai modell
- Segít becslések és előrejelzések készítésében
- Ez segít nekünk jobb üzleti döntés meghozatalában
- Segít az eredmények elemzésében és a hibák kijavításában
A lineáris regresszió egyenletét és ossza meg releváns részekre
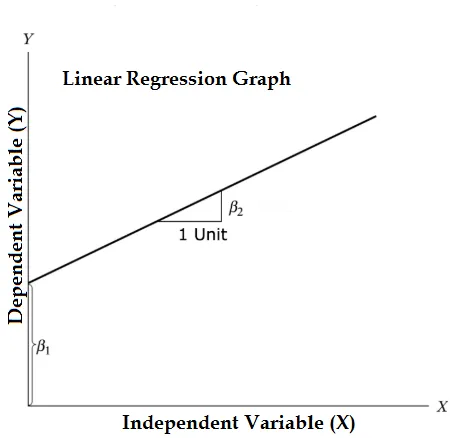
Y = β1 + β2X + ϵ
- Ahol β1 a matematikai terminológiában, mint intercept és β2 a matematikai terminológiában, mint lejtő. Regressziós együtthatóként is ismertek. ϵ a hiba kifejezés, az Y azon része, amelyet a regressziós modell nem tud magyarázni.
- Y egy függő változó (a függő változókra felcserélhetően használt egyéb kifejezések: válaszváltozó, regresszív, mért változó, megfigyelt változó, válaszadó változó, magyarázott változó, kimeneti változó, kísérleti változó és / vagy output változó).
- X független változó (regresszorok, szabályozott változó, manipulált változó, magyarázó változó, expozíciós változó és / vagy bemeneti változó).
Probléma: Annak megértése érdekében, hogy mi a lineáris regressziós elemzés, a „Cars” adatkészletet vesszük, amely alapértelmezés szerint az R könyvtárakban található. Ebben az adatkészletben 50 megfigyelés található (alapvetően sor) és 2 változó (oszlop). Az oszlopok neve „Dist” és „Speed”. Itt látnunk kell a sebességváltozók változásának hatását a távolságváltozókra. Az adatok szerkezetének megtekintéséhez futtathatunk Str kódot (adatkészlet). Ez a kód segít megérteni az adatkészlet felépítését. Ezek a funkciók segítenek jobb döntések meghozatalában, mivel a fejünkben jobb képet kapunk az adatkészlet felépítéséről. Ez a kód segít azonosítani az adatkészletek típusát.
Kód:

Hasonlóan az adatkészlet statisztikai ellenőrző pontjainak ellenőrzéséhez használhatjuk az Összegzés (autók) kódot is. Ez a kód az adatállomány átlagos, medián tartományát adja meg egy menetben, amelyet a kutató felhasználhat a probléma kezelése során.
Kimenet:
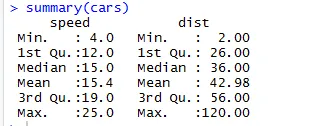
Itt láthatjuk minden olyan változó statisztikai eredményét, amely az adatkészletünkben található.
Az adatkészletek grafikus ábrázolása
Az itt bemutatott grafikus ábrázolás típusai és miért:
- Scatter Plot: A gráf segítségével láthatjuk, milyen irányba halad a lineáris regressziós modellünk, függetlenül attól, hogy van-e erős bizonyíték a modellünk igazolására, vagy sem.
- Boxterület: Segít bennünket a távolságok megtalálásában.
- Density Plot: Segítsen megérteni a független változó eloszlását, esetünkben a független változó a „Speed”.
A grafikus ábrázolás előnyei
A következő előnyök vannak a következők:
- Könnyen érthető
- Segít a gyors döntéshozatalban
- Összehasonlító elemzés
- Kevesebb erőfeszítés és idő
1. Scatter Plot: Ez segít a független változó és a függő változó közötti bármilyen kapcsolat megjelenítésében.
Kód:

Kimenet:
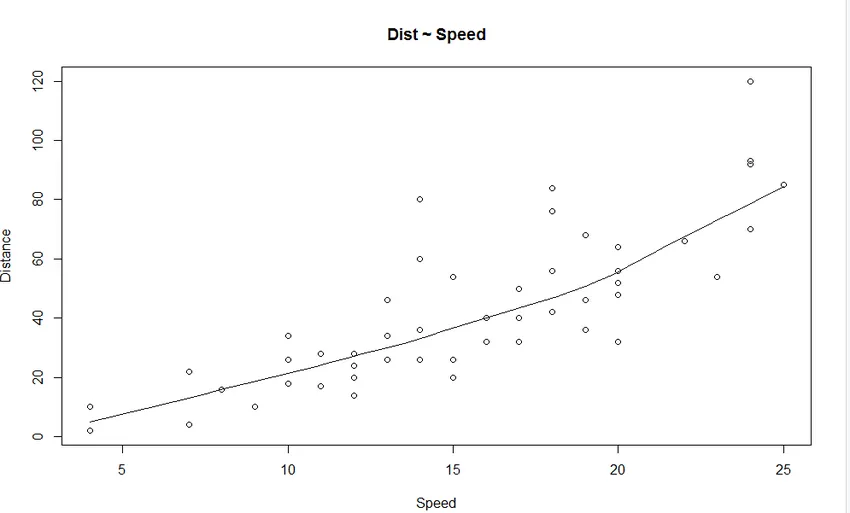
A grafikonból egyenesen növekvő kapcsolatot láthatunk a függő változó (távolság) és a független változó (sebesség) között.
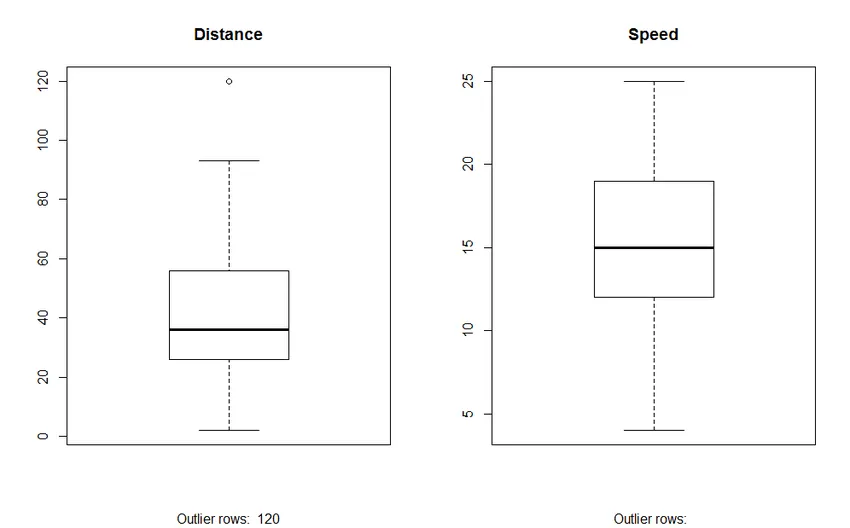
2. Box Plot: A Box plot segít beazonosítani az adatkészletekben szereplő távolságokat. A dobozterület használatának előnyei a következők:
- A változók helyének és eloszlásának grafikus megjelenítése.
- Segít megérteni az adatok ferde és szimmetriáját.
Kód:

Kimenet:
3. Sűrűségábra (az eloszlás normalitásának ellenőrzésére)
Kód:
 Kimenet:
Kimenet:
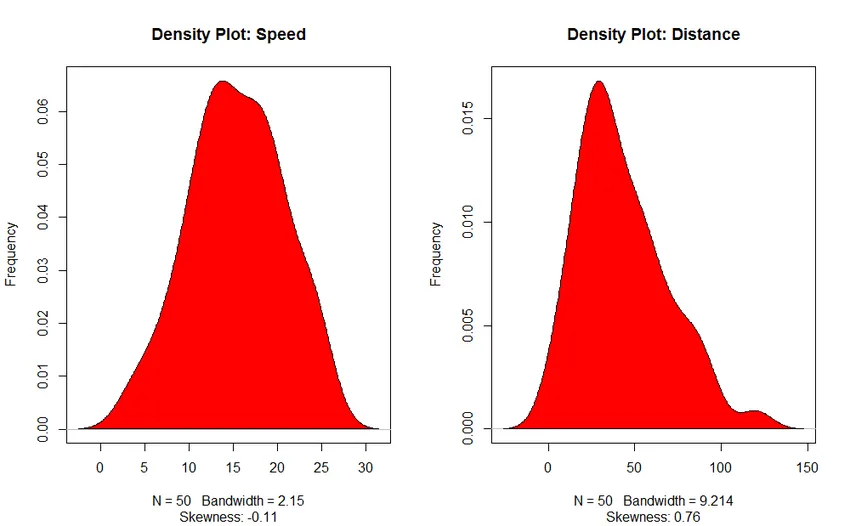
Korrelációs elemzés
Ez az elemzés segít megtalálni a változók közötti kapcsolatot. Főként hat típusú korrelációs elemzés létezik.
- Pozitív korreláció (0, 01 - 0, 99)
- Negatív korreláció (-0, 99 -0, 01)
- Nincs kapcsolat
- Tökéletes korreláció
- Erős korreláció (± 0, 99-nél közelebb eső érték)
- Gyenge korreláció (0-hoz közelebb álló érték)
A szórási diagram segít azonosítani, hogy mely típusú korrelációs adatkészletek vannak közöttük, és mi a kód a korreláció megtalálására

Kimenet:
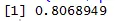
Itt erős pozitív korreláció van a sebesség és a távolság között, ami azt jelenti, hogy közvetlen kapcsolat van közöttük.
Lineáris regressziós modell
Ez az elemzés központi eleme, korábban csak próbáltunk próbálni és tesztelni, hogy a meglévő adatkészlet elég logikus-e az ilyen elemzés futtatásához. A függvény, amelyet használni akarunk, az lm (). Ez a funkció két elemet tartalmaz, amelyek a képlet és az adatok. Mielőtt hozzárendelnénk azt, hogy melyik változó függ vagy független, nagyon meg kell bizonyosodnunk arról, mert az egész képlet attól függ.
A képlet így néz ki,
Lineáris regresszió <- lm (függő változó ~ független változó, adatok = dátum.keret)
Kód:

Kimenet:
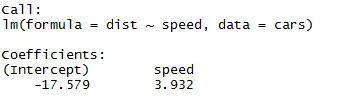
Amint a cikk fenti szegmenséből emlékezhetünk, a lineáris regresszió egyenlete:
Y = β1 + β2X + ϵ
Most beleilleszkedünk az információba, amelyet a fenti kódból kaptunk ebben az egyenletben.
dist = −17, 579 + 3, 932 ∗ sebesség
Csak a lineáris regresszió egyenletének megtalálása nem elegendő, annak statisztikai szignifikanciáját is ellenőriznünk kell. Ehhez át kell adnunk egy „Összegzés” kódot a lineáris regressziós modellünkben.
Kód:

Kimenet:

A modell statisztikailag szignifikáns ellenőrzésének többféle módja van, itt a P-érték módszerét használjuk. Statisztikai szempontból megfelelőnek tekinthetjük a modellt, ha a P-érték alacsonyabb, mint az előre meghatározott statisztikailag szignifikáns szint, amely ideális esetben 0, 05. Az összefoglaló táblázatban (lineáris_regresszió) láthatjuk, hogy a P-érték 0, 05 alatt van, tehát megállapíthatjuk, hogy modellünk statisztikailag szignifikáns. Ha biztosak vagyunk a modellünkben, felhasználhatjuk az adatkészletünket a dolgok előrejelzésére.
Ajánlott cikkek
Ez egy útmutató a lineáris regresszió elemzéséhez. Itt tárgyaljuk a lineáris regresszió elemzésének három típusát, az adatkészletek grafikus ábrázolását az előnyökkel és a lineáris regressziós modelleket. Megnézheti más kapcsolódó cikkeinket, hogy többet megtudjon-
- Regressziós képlet
- Regressziós teszt
- Lineáris regresszió R-ben
- Az adatelemzési technikák típusai
- Mi a regressziós elemzés?
- A regresszió és a besorolás legfontosabb különbségei
- A lineáris regresszió és a logisztikai regresszió 6 legfontosabb különbsége