

Mi az AWS Kinesis?
A Kinesis egy olyan platform, amely elősegíti az adatfolyam adatgyűjtését, feldolgozását és elemzését az Amazon Web Services szolgáltatásban. A streaming adatok nagy mennyiségű adat, amelyet különféle forrásokból, például közösségi média, tárgyak internete érzékelők, időjárás-előrejelzés, egészségügyi ellátás stb. Származtatnak. Ezeket az alkalmazásokat építik fel a felhasználói igények alapján. Néhány általános alkalmazás magában foglalja a prediktív elemzést a Big Data, a Machine Learning stb. Területén. Ebben a témakörben megismerjük az AWS Kinesis rendszert.
AWS Kinesis Services
Mielőtt a szolgáltatásokba lépnénk, először megértsük a Kinesis-ben használt néhány terminológiát.
Terminológia
| kifejezés | Meghatározás |
| Adatrekord | A Kinesis adatfolyamában tárolt adat egység. Ez adatblobból, sorszámból és partíciós kulcsból áll |
| Szilánk | Az adatrekordok sorozata. A szilánkok száma növelhető vagy csökkenthető, ha az adatátviteli sebességet megnövelik. |
| Megőrzési időszak | Az az időtartam, amely alatt az adatok hozzáférhetők az adatfolyamba való hozzáadása után.
Alapértelmezett megőrzési idő: 24 óra |
| Termelő | Az adatrekordokat a Kinesis Streambe továbbítja |
| Fogyasztó | Nyilvántartásokat kap a Kinesis Stream-ből, és feldolgozza azokat. |
A Kinesis 3 alapvető szolgáltatást nyújt. Ők:
1. Kinesis Streams
A Kinesis Stream adatrekord-sorozatból áll, Shards néven ismert. Ezeknek a Shards-nak egy rögzített kapacitása van, amely maximális olvasási sebességet biztosít 2 MB / másodperc és írási sebességet 1 MB / sec. A patak maximális kapacitása az egyes szilánkok kapacitásának összege.
Kinesis működése:
- Az IoT és más források, amelyeket Producer néven ismertek, adatait a Kinesis Streams tárolják Shards-ban.
- Ezek az adatok Shard-ban lesznek elérhetők legfeljebb 24 órán keresztül.
- Ha az alapértelmezett időnél hosszabb ideig kell tárolni, a felhasználó meghosszabbíthatja a 7 napos megőrzési időszakot.
- Miután az adatok elérték a Shards-ot, az EC2 példányok ezeket az adatokat különböző célokra vehetik fel.
- Az adatokat lekérő EC2 példányokat fogyasztóknak nevezzük.
- Az adatok feldolgozása után bekerül az Amazon webszolgáltatások egyikébe, mint például az Egyszerű tárolási szolgáltatás (S3), a DynamoDB, a Redshift stb.
2. Kinesis Firehose
A Kinesis Firehose hasznos az adatok áthelyezésében az Amazon webszolgáltatásokba, például a Redshift, az Egyszerű tárolási szolgáltatás, az Elastic Search stb.. Ez a streaming-platform része, amely nem kezeli az erőforrásokat. Az adatgyártók úgy vannak konfigurálva, hogy az adatokat el kell küldeni a Kinesis Firehose-nak, majd automatikusan eljuttatják a megfelelő rendeltetési helyre.
A Kinesis Firehose működése:
- Amint azt az AWS Kinesis Streams munkájában megemlítették, a Kinesis Firehose olyan gyártóktól is adatokat szerez, mint mobiltelefonok, laptopok, EC2 stb. Ennek oka az, hogy a Kinesis Firehose automatikusan megteszi.
- Az adatokat ezután automatikusan elemezzük és továbbítják az Simple Storage Service szolgáltatásba
- Mivel nincs megőrzési időszak, az adatokat vagy elemezni kell, vagy bármilyen tárolóhoz el kell küldeni, a felhasználó igényeitől függően.
- Ha az adatokat el kell küldeni a Redshift-hez, akkor azokat először az egyszerű tárolási szolgáltatásba kell helyezni, és onnan onnan a Redshift-re kell másolni.
- De az Elastic Search esetében az adatok közvetlenül bevihetők bele az egyszerű tárolási szolgáltatáshoz hasonlóan.
3. Kinesis Analytics
A Kinesis Firehose lehetővé teszi az SQL lekérdezések futtatását a Kinesis Firehose alkalmazásban található adatokban. Az SQL lekérdezések segítségével az adatok tárolhatók a Redshift, az Simple Storage Service, az ElasticSearch stb.
AWS Kinesis Architecture
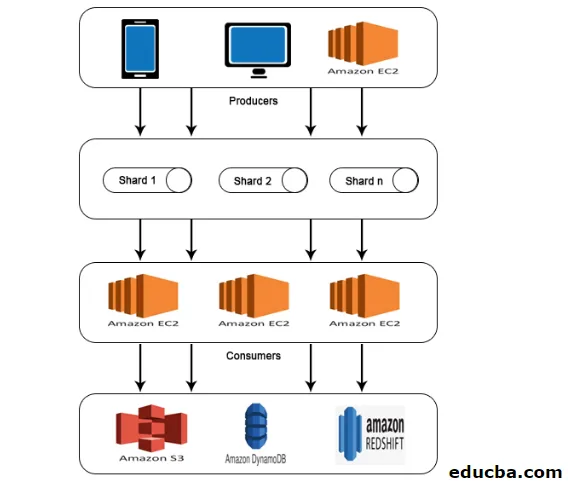
Az AWS Kinesis Architecture az alábbiakat foglalja magában:
- A termelők
- szilánkok
- fogyasztók
- Tárolás
Az AWS Kinesis adatfolyamban ismertetett munkához hasonlóan a termelőktől származó adatokat a Shards-ba továbbítják, ahol az adatokat feldolgozzák és elemezik. Az elemzett adatokat azután az EC2 példányokba helyezik át bizonyos alkalmazások végrehajtása céljából. Végül az adatokat az Amazon bármely webszolgáltatásában tárolják, például az S3, a Redshift stb.
Hogyan kell használni az AWS kinesist?
Az AWS Kinesis alkalmazásához a következő két lépést kell elvégezni.
1. Telepítse az AWS parancssori felületét (CLI).
A parancssori felület telepítése különböző operációs rendszerek esetén eltérő. Tehát telepítse a CLI-t az operációs rendszer alapján.
Linux felhasználók számára használja a sudo pip install AWS CLI parancsot
Győződjön meg arról, hogy a python verziója 2.6.5 vagy újabb. A letöltés után konfigurálja az AWS configure paranccsal. Ezután a következő részleteket kérjük, az alábbiak szerint.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Windows felhasználók számára töltse le a megfelelő MSI Installer programot, és futtassa azt.
2. Végezzen Kinesis műveleteket CLI segítségével
Felhívjuk figyelmét, hogy a Kinesis adatfolyamai nem érhetők el az AWS szabad szintjére. Tehát a létrehozott Kinesis adatfolyamokat felszámítják.
Most nézzük meg néhány kinesis műveletet a CLI-ben.
- Patak létrehozása
Hozzon létre egy KStream adatfolyamot a Shard count 2-rel a következő paranccsal.
aws kinesis create-stream --stream-name KStream --shard-count 2
Ellenőrizze, hogy a patak létrehozott-e.
aws kinesis describe-stream --stream-name KStream
Ha létrehozza, akkor megjelenik a következő példához hasonló kimenet.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Jegyezze fel
Most egy adatrekord beszúrható a put-record paranccsal. Itt egy adattesztet tartalmazó rekord kerül beillesztésre a patakba.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Ha a beillesztés sikeres, a kimenet az alább látható módon jelenik meg.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Get Record
Először a felhasználónak be kell szereznie a szilánk iterátort, amely képviseli az áramlás helyzetét a szilánkhoz.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Ezután futtassa a parancsot a kapott szilánk iterátor segítségével.
aws kinesis get-records --shard-iterator ###########
A mintát az alábbiak szerint kapjuk meg.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Tisztítsd meg
A díjak elkerülése érdekében a létrehozott adatfolyam az alábbi paranccsal törölhető.
aws kinesis delete-stream --stream-name KStream
Következtetés
Az AWS Kinesis egy olyan platform, amely adatgyűjtést, feldolgozást és elemzést végez számos alkalmazás számára, például gépi tanuláshoz, prediktív elemzéshez stb. A streaming adatok bármilyen formátumúak lehetnek, például audio-, video-, érzékelőadatok stb.
Ajánlott cikkek
Ez egy útmutató az AWS Kinesis-hez. Itt megvitatjuk az AWS Kinesis használatát, valamint a szolgáltatás és a munka és az építészet használatát. A következő cikkben további információkat is megnézhet -
- AWS architektúra
- Mi az AWS Lambda?
- Big Data Technologies
- Adatbányászati architektúra
- AWS tárolási szolgáltatások
- Útmutató a jellemzőkkel rendelkező AWS versenytársainak