
Bevezetés az együttes technikájába
Az együttes tanulás egy olyan módszer a gépi tanuláshoz, amely több alapmodell segítségével, és egyesíti a kimeneteiket egy optimalizált modell előállításához. Az ilyen típusú gépi tanulási algoritmus elősegíti a modell általános teljesítményének javítását. Itt a leggyakrabban használt alapmodell a döntési fa osztályozó. A döntési fa alapvetően több szabályon működik, és prediktív eredményt szolgáltat, ahol a szabályok a csomópontok, és döntéseik gyermekeik lesznek, és a levélcsomók képezik a végső döntést. Amint az a döntési fa példáján látható.
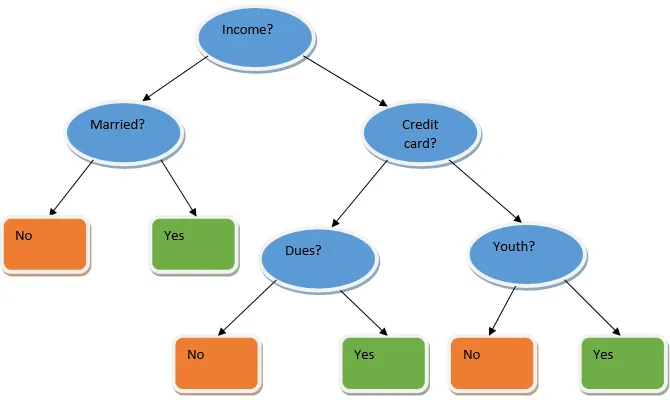
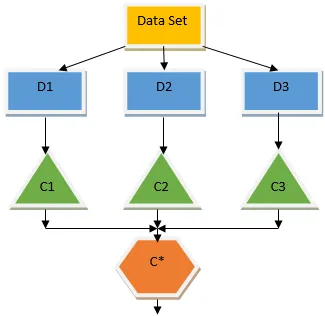
A fenti döntési fa alapvetően arról szól, hogy egy személynek / ügyfélnek kölcsön adható-e. A hitel kölcsönös elfogadhatóságának egyik szabálya az, hogy ha (jövedelem = igen && Házas = Nem) Akkor hitel = igen, így működik a döntési fa osztályozó. Ezeket az osztályozókat több alapmodellként fogjuk beépíteni, és kombináljuk outputjaikat egy optimális prediktív modell felépítéséhez. Az 1.b ábra egy együttes tanulási algoritmusának általános képét mutatja.
Az együttesek technikáinak típusai
Különböző típusú együttesek, de leginkább az alábbi két típusra koncentrálunk:
- Zsákolás
- fellendítése
Ezek a módszerek csökkentik a gépi tanulási modell varianciáját és torzulását. Most próbáljuk megérteni, mi az elfogultság és a szórás. A torzítás egy hiba, amely az algoritmusunk téves feltételezései miatt merül fel; a nagy torzítás azt jelzi, hogy modellünk túl egyszerű / alsó. A variancia az a hiba, amelyet a modell érzékenysége okoz az adatkészlet nagyon kicsi ingadozásaival szemben; a nagy szórás azt mutatja, hogy modellünk rendkívül összetett / túlzott. Az ideális ML modellnek megfelelő egyensúlyban kell lennie az elfogultság és a variancia között.
Bootstrap összeszerelés / csomagolás
A csomagolás egy olyan együttes technika, amely elősegíti a modell varianciájának csökkentését, és ezzel elkerüli a túlzott felszerelést. A csomagolás a párhuzamos tanulási algoritmus példája. A zsákolás két elven alapszik.
- Rendszerindítás: Az eredeti adathalmazból a különböző mintapopulációkat veszik fontolóra pótlással.
- Összesítés: Az összes osztályozó eredményének átlagolása és egységes kimenet biztosítása, ehhez osztályozás esetén többségi szavazást alkalmaz, és regressziós probléma esetén átlagolást alkalmaz. Az egyik híres gépi tanulási algoritmus, amely a csomagolás fogalmát használja, egy véletlenszerű erdő.
Véletlenszerű erdő
Véletlenszerű erdőben a véletlenszerű mintából, amelyet a populációból kiváltottak pótlással, és egy tulajdonság egy részhalmazát választják meg az összes tulajdonság halmaza közül egy döntési fa épül. A tulajdonságok ezen alkészleteiből az a döntési fa gyökér kerül kiválasztásra, amelyik a legjobb megosztást nyújt. A szolgáltatások részhalmazát véletlenszerűen kell kiválasztani, bármilyen áron, különben csak a korrelált tress-et fogjuk előállítani, és a modell szórása nem javul.
Most a népességből vett mintákkal készítettük modellünket, az a kérdés, hogyan validáljuk a modellt? Mivel a minták cseréjét fontolóra vesszük, így az összes mintát nem vesszük figyelembe, és részben nem kerülnek bele semmilyen zsákba, ezeket a zsákból ki nem vett mintáknak nevezzük. Ezzel az OOB (out of bag) mintákkal validálhatjuk modellünket. A véletlenszerű erdőben figyelembe veendő fontos paraméterek a minták száma és a fák száma. Tekintsük az „m” -et mint a funkciók részhalmazát, a „p” pedig a szolgáltatások teljes készletét, hüvelykujjszabályként mindig ideális választani
- m as√, és egy minimális csomópontméret 1, mint egy osztályozási probléma.
- m mint P / 3, és a csomópont minimális mérete 5 legyen egy regressziós probléma esetén.
Az m és p hangolási paramétereket kell kezelni, amikor egy gyakorlati problémával foglalkozunk. Az edzés megszakítható, amint az OOB hiba stabilizálódik. A véletlenszerű erdő egyik hátránya, hogy ha az adatkészletben 100 szolgáltatás van, és csak néhány funkció fontos, akkor ez az algoritmus rosszul fog teljesíteni.
fellendítése
A Boosting egy szekvenciális tanulási algoritmus, amely segíti a modell torzulásának és a variancia csökkentését a felügyelt tanulás egyes eseteiben. Segít abban is, hogy a gyenge tanulókat erős tanulókká alakítsák. Az erősítés azon elv alapján működik, hogy a gyenge tanulókat egymás után helyezzék el, és minden forduló után súlyt rendel az egyes adatpontokhoz; nagyobb súlyt kap az előző körben tévesen osztályozott adatpont. Ez a szekvenciálisan súlyozott módszer az adatkészlet kiképzéséhez a legfontosabb különbség a csomagoláshoz képest.
A 3.a ábra az erősítés általános megközelítését mutatja
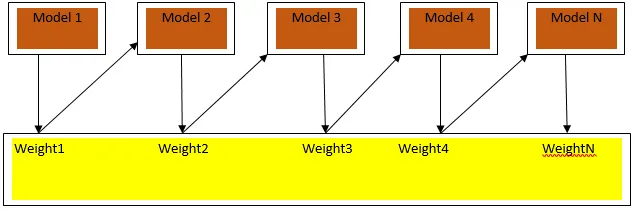
A végső előrejelzéseket a besorolás esetén a súlyozott többségi szavazás és a regresszió esetén a súlyozott összeg alapján kombináljuk. A legszélesebb körben alkalmazott fokozó algoritmus az adaptív fokozás (Adaboost).
Adaptív fellendülés
Az Adaboost algoritmusban szereplő lépések a következők:
- Az adott n adatpontra meghatározzuk a célosztályt, és az összes súlyt 1 / n-re inicializáljuk.
- Az osztályozókat az adatkészlethez illesztjük, és a legkevésbé súlyozott osztályozási hibával rendelkező osztályozást választjuk
- A súlyokat az osztályozóhoz egy pontosságon alapuló hüvelykujjszabály segítségével osztjuk meg, ha a pontosság nagyobb, mint 50%, akkor a súly pozitív, és fordítva.
- Az osztályozók súlyát az iteráció végén frissítjük; frissítjük a tévesen besorolt pontok súlyát, hogy a következő iterációban helyesen osztályozzuk.
- Az iteráció után megkapjuk a végső előrejelzési eredményt a többségi szavazás / súlyozott átlag alapján.
Az Adaboosting hatékonyan működik gyenge (kevésbé összetett) tanulókkal és magas elfogultságú osztályozókkal. Az Adaboosting fő előnye, hogy gyors, nincs hangolási paraméter, amely hasonló lenne a zsákolás esetéhez, és nem teszünk feltételezéseket a gyenge tanulókra. Ez a technika nem ad pontos eredményt, amikor
- Több adat van az adatainkban.
- Az adatkészlet nem elegendő.
- A gyenge tanulók nagyon összetettek.
A zajra is érzékenyek. A fellendítés eredményeként előállított döntési fák korlátozott mélységgel és nagy pontossággal rendelkeznek.
Következtetés
Az együttes tanulási technikáit széles körben használják a modell pontosságának javításához; az adatkészletünk alapján el kell döntenünk, hogy melyik technikát kell használni. De ezeket a technikákat nem részesítik előnyben olyan esetekben, amikor az értelmezhetőség fontos, mivel a teljesítmény javításának árán elveszítjük az értelmezhetőséget. Ezek óriási jelentőséggel bírnak az egészségügyi ágazatban, ahol a teljesítmény kis javulása nagyon értékes.
Ajánlott cikkek
Ez az útmutató az Ensemble Techniques-hoz. Itt tárgyaljuk az Ensemble Techniques bevezetését és két fő típusát. Megnézheti más kapcsolódó cikkeinket, hogy többet megtudjon-
- Steganográfiai technikák
- Gépi tanulási technikák
- Csapatépítési technikák
- Adattudomány algoritmusai
- Az együttesek tanulásának leggyakrabban használt technikái