

Bevezetés a csatlakozáshoz a Spark SQL-hez
Mint tudjuk, az SQL összekapcsolásait két vagy több táblázat adatainak vagy sorok összekapcsolására használják, a köztük lévő közös mező alapján. Ebben a témában megismerjük a Csatlakozás a Spark SQL-hez csatlakozást a Spark SQL-hez.
A Spark SQL esetében az Dataframe vagy az Adatkészlet egy memóriában lévő táblázatos struktúra, amelynek sorai és oszlopai vannak elosztva több csomópont között. A normál SQL táblázatokhoz hasonlóan a Spark SQL-ben jelen lévő Dataframe vagy Dataset is csatlakozási műveleteket hajthatunk végre köztük lévő közös mező alapján.
Különféle típusú Join műveletek érhetők el az SQL-ben. Az üzleti felhasználástól függően választhatjuk a Join műveletet. A következő szakaszban példákkal mutatjuk be az egyes csatlakozástípusokat.
Csatlakozás típusai a Spark SQL-ben
Az alábbiakban bemutatjuk a Spark SQL-ben elérhető különféle csatlakozásokat:
- BELSŐ ÖSSZEKAPCSOLÁS
- CSATLAKOZÁS
- Bal oldali csatlakozás
- JOGI KÜLSŐ CSATLAKOZÁS
- TELJES KÜLSŐ CSATLAKOZÁS
- Bal oldali félév csatlakozás
- Balra csatlakozás
Példa az adatok létrehozására
A következő adatokat fogjuk használni a különféle csatlakozási módok bemutatására:
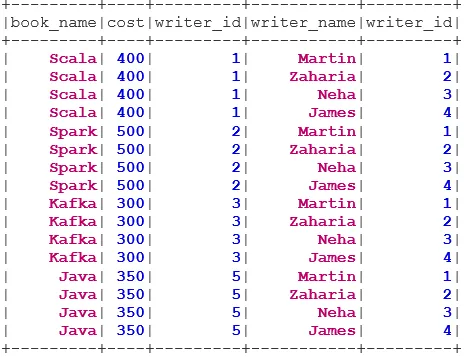
Könyv adatkészlet:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Író adatkészlete:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Csatlakozás típusai
Az alábbiakban felsoroljuk a 7 különféle csatlakozástípust:
1. Belső csatlakozás
Az INNER JOIN visszaadja azt az adatkészletet, amelynek sorai mindkét adatkészletben megegyezõ értékekkel rendelkeznek, azaz a közös mezõ értéke azonos lesz.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CSATLAKOZÁS
A CROSS JOIN visszaadja azt az adatkészletet, amely az első adatkészlet sorának száma szorozva a második adatkészletben szereplő sorok számával. Az ilyen eredményt Descartes terméknek nevezzük.
Előfeltétel: A keresztsugárzás használatához a spark.sql.crossJoin.enabled értékét true értékre kell állítani. Ellenkező esetben a kivétel elveszik.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
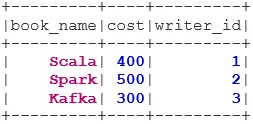
3. Bal oldali csatlakozás
A LEFT OUTER JOIN visszaadja azt az adatkészletet, amelyben minden sor található a bal oldali adatkészletből, és az illesztett sorokat a jobb oldali adatkészletből.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. JOGI KÜLSŐ CSATLAKOZÁS
A JOBB KIMENETI CSATLAKOZÁS visszaadja azt az adatkészletet, amelyben minden sor található a jobb oldali adatkészletből, és az illesztett sorok a bal oldali adatkészletből.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. TELJES KIEGÉSZÍTÉS
A FULL OUTER JOIN visszaadja azt az adatkészletet, amelyben minden sor szerepel, amikor egyezés található a bal vagy a jobb oldali adatkészletben.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. Bal oldali csatlakozás
A LEFT SEMI JOIN visszaadja azt az adatkészletet, amelyben a bal oldali adatkészlet összes sora szerepel, és amelyek megfelelnek a jobb oldali adatkészletben. A LEFT OUTER JOIN-tól eltérően a LEFT SEMI JOIN visszaadott adatállománya csak a bal oldali adatkészlet oszlopait tartalmazza.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. Bal oldali csatlakozás
Az ANTI SEMI JOIN visszaadja azt az adatkészletet, amelyben a bal oldali adatkészlet összes sora szerepel, és amelyek nem egyeznek meg a jobb oldali adatkészlettel. Csak a bal oldali adatkészlet oszlopait tartalmazza.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Következtetés - Csatlakozzon a Spark SQL-hez
Az adatok összekapcsolása az egyik leggyakoribb és legfontosabb művelet az üzleti felhasználási esetünk teljesítéséhez. A Spark SQL támogatja az összes alapvető csatlakozástípust. Csatlakozás közben figyelembe kell vennünk a teljesítményt is, mivel nagy hálózati átvitelt igényelhetnek, vagy akár adatkezelő készíthetik is a kezelési képességünket. A teljesítmény javítása érdekében a Spark az SQL optimalizálót használja a szűrők újrarendeléséhez vagy leállításához. A szikra korlátozza a veszélyes csatlakozást is. e CROSS JOIN. A keresztirányú csatlakozás használatához a spark.sql.crossJoin.enabled kifejezetten igazra kell állítani.
Ajánlott cikkek
Ez egy útmutató a Csatlakozás a Spark SQL-hez. Itt a Spark SQL-ben elérhető különféle csatlakozások típusát tárgyaljuk a példával. A következő cikket is megnézheti.
- Csatlakozás típusai az SQL-ben
- Táblázat SQL-ben
- SQL beszúrási lekérdezés
- Tranzakciók az SQL-ben
- PHP szűrők | Hogyan validálhatjuk a felhasználói bemeneteket különféle szűrőkkel?