
Különbség a HBase és a Cassandra között
A HBase egy adatbázis, amely a Hadoop elosztott fájlrendszerét használja tárolásához. A HBase a HDFS fontos része, és a Hadoop klaszter tetején fut. A HBase nem hagyományos relációs adatbázis, más adatmodellezési megközelítést igényel. A Cassandra az adatreplikációs modelleken működik, így bármely csomópont elérhetetlensége esetén az adatok nem vesznek el. A Cassandra egy elosztott adatbázis, amely azt jelenti, hogy az ügyfelek az adatokhoz bármilyen fürtből és csomópontból hozzáférhetnek
1.1) Cassandra:
A Facebook indította, mert mindig megfelel az alkalmazás követelményeinek. A Cassandra 2005-ben indult, és 2008-ban elérhetővé tette a nyilvánosság számára. A Cassandrát olyan állandó alkalmazásokra fejlesztették ki, mint például a közösségi hálózatok, például a Facebook és a Twitter.
A Cassandra „mindig bekapcsolt” architektúrán működik, és rendelkezik egy aktív-aktív csomópont-modellel, így nincs SPoF (egyetlen meghibásodási pont). A CQL (Cassandra Query Language) a Cassandra lekérdezési nyelve, de annak szintaxisa megegyezik az SQL-lel. Támogat minden olyan operációs rendszert, mint a Linux, az Unix, az OSX és a Windows.
Mindig be:
A Cassandra egy adatbázis disztribúciós modellel, és az összes csomópont azonos a fürtön belül. Az adatok replikálódnak a konfigurálható csomópontokon, tehát néhány nem működése esetén. A csomópontok száma nem eredményezi az adatok elvesztését.
(Mindig modell)
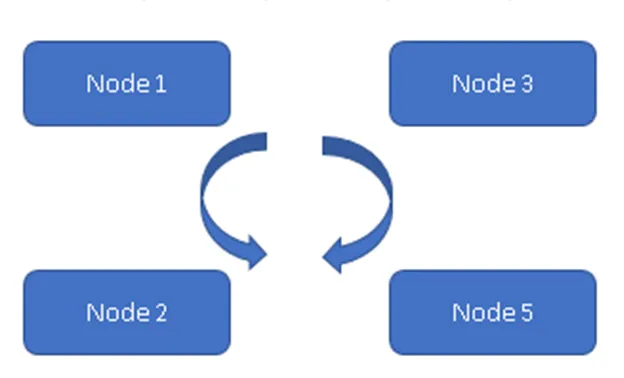
Az 1. ábrán mind a négy csomópont szinkronban van egymással és replikálják az adatokat a fürtön belül. Mindannyian aktívan aktív modelln dolgoznak, így bármely csomópont meghibásodása esetén az adatok nem vesznek el. Az ügyfél az adatokat a rendelkezésre álló csomópontok / csomópontok többi részéből tudja olvasni.
1.2) HBase:
A HBase egy NoSQL alapú adatbázis, amelyet olyan nagy táblákban végzett lekérdezések feldolgozására terveztek, amelyek milliárd sorban, millió oszlopmal rendelkeznek, és áthaladnak egy árucikk / normál hardver fürtön. Valós idejű lekérdezési képességeket biztosít a „ kulcs / értéktároló ” sebességével.
A HBase valójában négydimenziós adatmodellre épül / működik.
- Sor azonosítója / sor kulcsa
- Oszlopcsalád.
- Kulcs-érték párok.
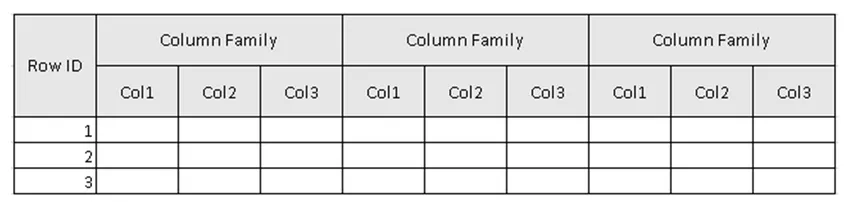
(2. ábra, a táblázat példája a HBase-ben.)
A 2. ábrán a táblázat az Oszlopcsalád gyűjteménye, az Oszlopcsalád az Oszlopok gyűjteménye. Az oszlopok a kulcs-érték párok gyűjteményét jelentik
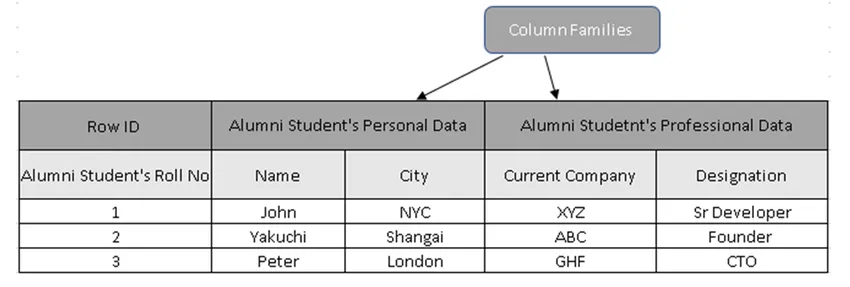
(3. ábra, Minta táblázat a HBase-ben)
A 3. ábrán az oszlopcsaládok az öregdiák hallgatói adatainak gyűjteményét tartalmazzák, és a Sor azonosítók (Sor Kulcsok) tartalmazzák a Diák tekercs számát.
Tény, hogy a sorgombok az oszlopcsalád adataival szemben mutatják az egyedi értéket. A Sor kulcs használatával kibontható a teljes részlet, megmagyarázva, hogy az Oszlop-orientált adatbázisok sokkal gyorsabbak, mint a hagyományos adatbázisok.
Az Apache HBase véletlenszerű olvasási / írási hozzáférésre használható, és támogatást nyújt a hibaelhárításhoz. Támogatja a replikációt és a disztribúciós adatbázis-modellel végzett munkát is.
A HBase és Cassandra összehasonlítása a fej és a fej között (Infographics)
Az alábbiakban bemutatjuk a 9 legfontosabb különbséget a HBase és a Cassandra között
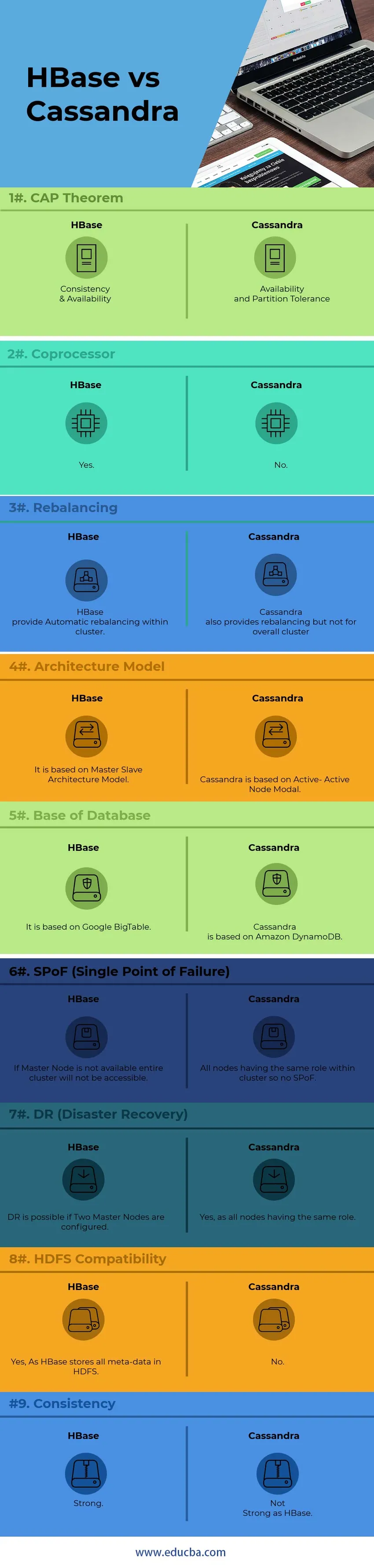 Főbb különbségek a HBase és a Cassandra között
Főbb különbségek a HBase és a Cassandra között
Az alábbiakban felsoroljuk a pontok listáját, írjuk le a HBase és a Cassandra közötti fő különbségeket:
1) A belső csomópont-kommunikációhoz a Cassandra a GOSSIP protokollt használja, míg a HBase az állatkertőrön alapul. A GOSSIP Protokoll szolgáltatásai integrálva vannak a Cassandra másik oldalával. A Zookeeper egy teljesen különálló disztribúciós alkalmazás.
2) A Cassandra architektúrában az összes csomópont aktív csomópontként működik, míg a HBase építész a Master-Slave Node modellt követi. Az Active-Active Node modellben nincs SPoF (Single Point of Failure). A HBase esetén, ha a fő csomópont leesik, a teljes fürt nem lesz elérhető.
3) HBase támogatás A bináris fa keresési modell, míg a Cassandra nem támogatja a B-fa modellt B-fa nélkül, nem lehet keresni a felhasználói oszlopcsaládban mindenki számára, akinek évfordulója van áprilisban, miközben mindenkit kereshet, aki Pekingben él egy Évforduló áprilisban.
4) HBase, támogatja a C, C ++, Java, Python, Scala szkriptnyelveket, míg a Cassandra a JavaScript és a Ruby támogatását is támogatja.
5) A HBase rendelkezik egy olyan funkcióval, amelyet koprocesszornak hívnak, míg a Cassandranak nincs ilyen funkciója jelenleg. Az együttprocesszorok könyvtárat és futási környezetet biztosítanak a felhasználói kód végrehajtásához a HBase régió szerverén és a master folyamatokon belül.
6) A HBase célja az Adatraktár támogatása, míg a Cassandra tökéletes lesz minden időben futó alkalmazásokhoz, mint például a Web és a Mobil alkalmazások.
7) A HBase lekérdezési nyelv egy egyedi nyelv, amelyet el kell tanulni, míg a Cassandra saját kifejlesztett CQL-jét (Cassandra Query Language) használja, amely SQL-szerű nyelv
8) A Cassandra kezelése sokkal könnyebb, mint a HBase-nél. Cassandrában egyetlen Java folyamatot kell futtatni csomópontonként, míg a HBase, teljes mértékben működőképes HDFS, több HBase folyamat és a Zookeeper rendszerhez.
9) A HBase véget vet az ellenőrző összegeknek és az automatikus újbóli kiegyenlítésnek, míg a Cassandra nem támogatja a klaszter általános egyensúlyba állítását.
10) A „ CAP tétel” alapján a Cassandra az AP Modelon működik, míg a HBase a CP modell.
KAP tétel
Ezt a tételt elosztott rendszerekhez használják. A C a következetesség, az A a rendelkezésre állás és a P a partíciós tolerancia. Az alábbiakban kifejtett KAP-tétel:
C (konzisztencia): A konzisztencia azt jelenti, hogy ha valaki értéket írt egy adatbázisba, mások azonnal elolvashatják ugyanazt az értéket.
A (Elérhetőség) : A rendelkezésre állás azt jelenti, ha néhány csomópont nem érhető el a fürtben (A csomópontok leolvadtak / nem élnek a fürtben valamilyen probléma miatt), az nem érinti az egész fürtöt, és az Elosztott rendszer / Adatbázis elérhető lesz az adatok eléréséhez. A klaszter mindenféle feladathoz elérhető lesz.
P (partíciós tolerancia): A partíciótűrés azt jelenti, hogy ha az egyik adatközpont lemegy, akkor az nem befolyásolja a csomópontokon megjelenő adatokat, és az összes adatnak bármikor hozzáférhetőnek kell lennie. A szétválasztási tűrés lehetővé teszi az adatok jobb replikálását más adatközpontokba és a fürt környezetében is.
HBase vs Cassandra összehasonlító táblázat
| Pont | HBase | Cassandra |
| KAP tétel | Konzisztencia és rendelkezésre állás | Rendelkezésre állás és partíciós tolerancia |
| Koprocesszor | Igen | Nem |
| Vegetarian | A HBase automatikusan újbóli kiegyenlítést biztosít a klaszterben. | A Cassandra szintén kiegyensúlyozást biztosít, de nem az általános klaszter számára |
| Építészeti modell | Ez a Master-Slave építészeti modelln alapul | A Cassandra az Active-Active Node modálon alapul |
| Adatbázis alapja | Ez a Google BigTable alapú | A Cassandra alapja az Amazon DynamoDB |
| SPoF (egyetlen hibapont) | Ha a fő csomópont nem érhető el, a teljes fürt nem lesz elérhető | Az összes csomópont azonos szerepet játszik a klaszterben, így nincs SPoF |
| DR (katasztrófa utáni helyreállítás) | A DR lehetséges, ha két fő csomópont van konfigurálva. | Igen, mivel minden csomópont azonos szerepet játszik |
| HDFS kompatibilitás | Igen, mivel a HBase az összes metaadatot HDFS-ben tárolja | Nem |
| Következetesség | Erős | Nem erős, mint HBase |
Következtetés - HBase vs Cassandra
A Facebook és más szociális hálózati oldalak inkább a HBase-t részesítik előnyben (korábban mindketten használtak Cassandrát, lásd a Facebook-posztot) elérhetősége miatt a másik oldalú banki domain szektor minden pénzügyi tranzakció számára biztonságot keres, így a Cassandrát választanák a HBase felett.
A Cassandra kulcsfontosságú tulajdonságai magukban foglalják a magas rendelkezésre állást, a minimális adminisztrációt és az SPoF (Single Point of Failure) másik oldalát. A HBase jó az adatok gyorsabb olvasására és írására, lineáris skálázhatósággal.
Az olyan cégek, mint a Verizon, a Bloomberg, a Bank of America és még sok más, a HBase-t használják, a Cassandra pedig olyan nagy közösségi oldalak, mint a Twitter, a Facebook stb.
Nem tudjuk megállapítani, melyik a legjobb, a HBase és a Cassandra mindkettőnek megvan a maga előnye és hátránya. A HBase és a Cassandra adatbázisok tényleges teljesítménye a termelési környezetben is látható.
Ajánlott cikkek:
Ez egy útmutató a HBase vs Cassandra, azok jelentésének, a fej-fej összehasonlításnak, a legfontosabb különbségeknek, az összehasonlító táblázatnak és a következtetéseknek. A következő cikkeket is megnézheti további információkért -
- Hadoop vs Apache Spark - Érdekes dolgok, amelyeket tudnod kell
- Hogyan lehet feltörni a Hadoop fejlesztői interjút?
- Az öt legfontosabb nagy adatindencia
- 5 A nagy adatelemzés kihívásai