
Bevezetés a kaptárcsoportba
A csoport szerint, ahogy a neve is sugallja, az a rekordot csoportosítja, amely megfelel bizonyos kritériumoknak. Ebben a cikkben a HIVE csoportját vizsgáljuk meg. A régi RDBMS-ben, például a MySQL, SQL stb., A csoportosítás az egyik legrégebbi záradék, amelyet használnak. Most hasonló módon találta meg a helyét a HIVE néven ismert fájl alapú adattárolásban.
Tudjuk, hogy a Hive sok régi RDBMS-t meghaladt a hatalmas adatok kezelésében anélkül, hogy az eladókra egy fillért költenének az adatbázisok és szerverek karbantartására. Be kell állítanunk a HDFS-t a kaptár kezelésére. Általában a táblázatokhoz költözünk, mert a végfelhasználó értelmezheti a szerkezetét, és lekérdezheti, mivel a fájlok ügyetlenek számukra. De ezt azért kellett megtennünk, hogy fizetésünk volt az eladóknak, hogy kiszolgálókat biztosítsanak és adataikat táblázatok formájában tartsák fenn. Tehát a Hive biztosítja a költséghatékony mechanizmust, ahol kihasználja a fájl alapú rendszerek (a mód, ahogyan a kaptár elmenti az adatait), valamint a táblák (táblaszerkezet a végfelhasználók számára a lekérdezéshez) előnyeit.
Csoportosít
A csoportosítással a Kaptáblázat meghatározott oszlopait használja az adatok csoportosításához. Tehát fontolja meg, hogy van egy táblája az összes állam összes országának népszámlálási adataival, ahol a város neve és az állam neve az egyik oszlop. Most a lekérdezésben, ha állatokat csoportosítunk, akkor egy adott állam különféle városaiból származó összes adatot csoportosítunk, és az adatok jobban megjeleníthetők, még mielőtt az alkalmaznánk a csoportot.
A kaptárcsoport szintaxisa
A csoport általános szintaxisa az alábbiak szerint:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
vagy egyszerűbb lekérdezésekhez,
from Group By
Select department, count(*) from the university.college Group By department;
Itt az osztály a kollégiumtáblázat egyik oszlopára utal, amely az egyetemi adatbázisban található, és értéke különböző olyan osztályokon működik, mint a művészet, a matematika, a mérnöki munka, stb. Most lássunk néhány példát a csoport bemutatására.
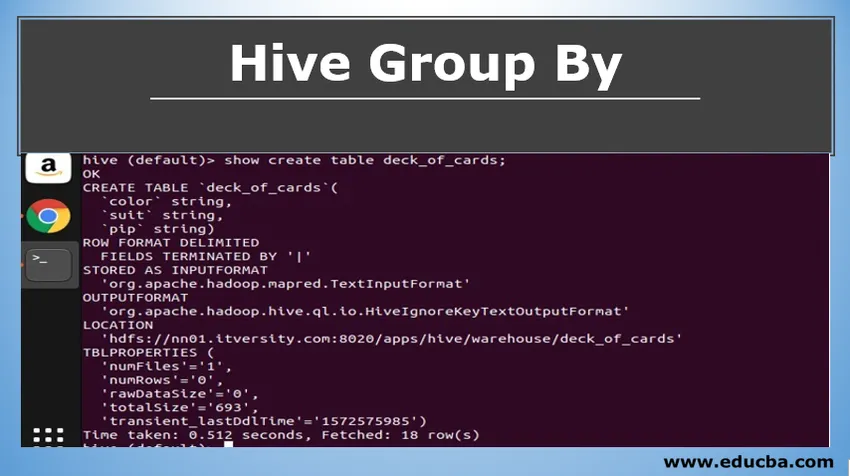
Készítettem egy deck_of_cards kártyatáblát a csoport bemutatására. A tábla létrehozása utasítás a következő:
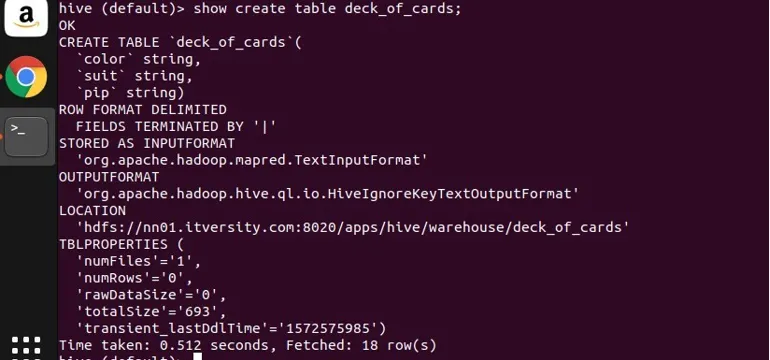
felülről láthatja, hogy három karakterlánc-oszlopgal rendelkezik, szín, öltöny és pip. Hadd írjak lekérdezést az adatok szín szerinti csoportosítása és számlálása céljából.
select color, count(*) from deck_of_cards group by color;
A Hive alapvetően a fenti lekérdezést veszi át, hogy átalakítsa azt térkép-csökkentő programmá a megfelelő java kód és jar fájl létrehozásával, majd végrehajtja. Ez a folyamat eltarthat egy kicsit, de határozottan képes kezelni a nagy adatokat a hagyományos RDBMS-hez képest. A fenti lekérdezés végrehajtásához lásd az alábbi képernyőképet a részletes naplóval.
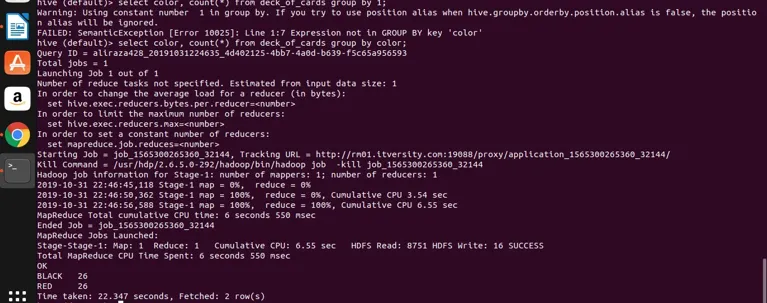
láthatja, hogy a FEKETE 26 és a Vörös 26.
most alkalmazzuk a csoportosítást két oszlopra (szín és szín, valamint a csoportszám kiszámítása), és az eredményt lásd alább.
Select color, suit, count(*) from deck_of_cards group by color, suit
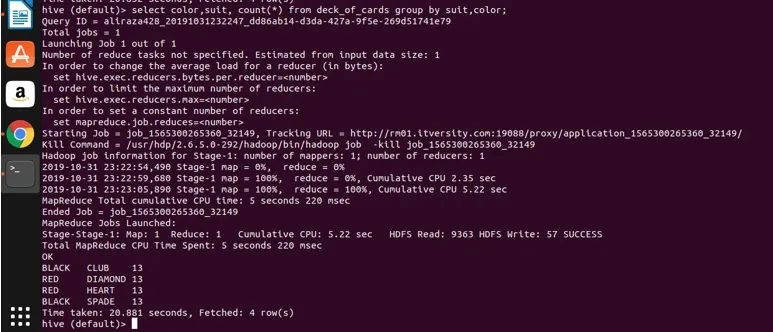
Alapvetően négy különálló csoport van a Club, Spade felett, amelyek fekete színűek, a gyémánt és a szív pedig piros színű.
Az eredmény csoportonként történő tárolása ok szerint egy másik táblázatban
A Hive, mint bármely más RDBMS, biztosítja az adatok beillesztését táblázatok létrehozásával. Nézzük meg az eredmény tárolását egy kiválasztott kifejezésből egy csoport felhasználásával egy másik táblázatba. Hadd használjam maga a fenti lekérdezést, ahol két oszlopot használtam csoportonként.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
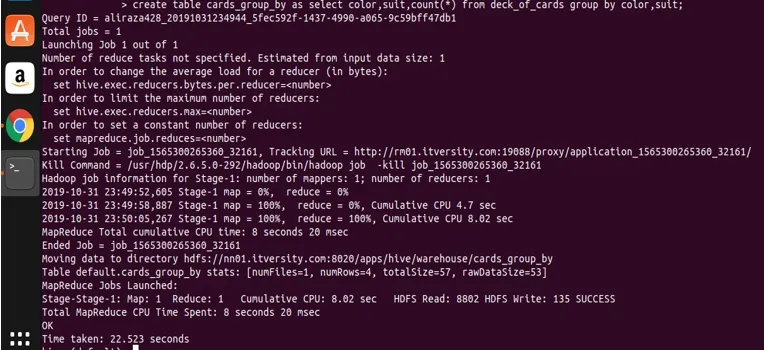
Most kérdezzünk a létrehozott táblára az adatok megtekintéséhez és érvényesítéséhez.

Most korlátozjuk a csoport eredményét záradék használatával. Amint az általános szintaxisból kiderül, korlátozást alkalmazhatunk a csoportra a következő használatával. Itt az ordser_items táblát használom, és szerkezete a következő a leírásban.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
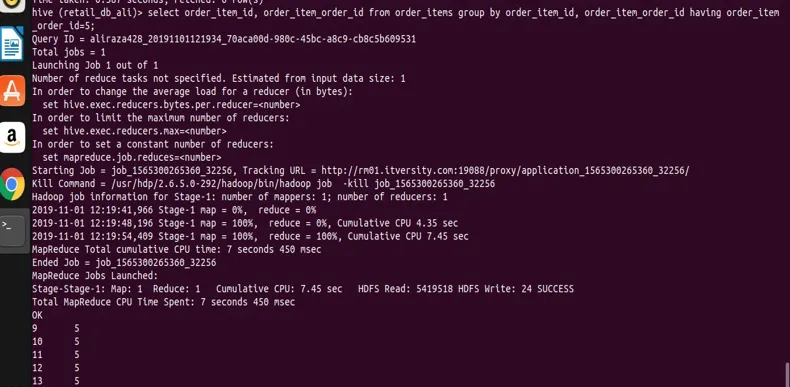
az eredményből láthatja a képernyőképet, hogy csak a order_item_order_id 5. értékkel rendelkezik rekordokkal.
Csoportosítva az esettanulmány alapján
Most nézzük meg a bonyolult lekérdezéseket, amelyekben a CASE állítások tartalmazzák a csoportot. Ezt alkalmazni fogjuk a order_items táblára. Az alábbiakban látni fogjuk, hogy kategorizálhatjuk azokat a nem szegmentáló oszlopokat, amelyekre nem alkalmazhatjuk a csoportot kifejezés alapján.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
Végezzük el eredményeket a kaptárban
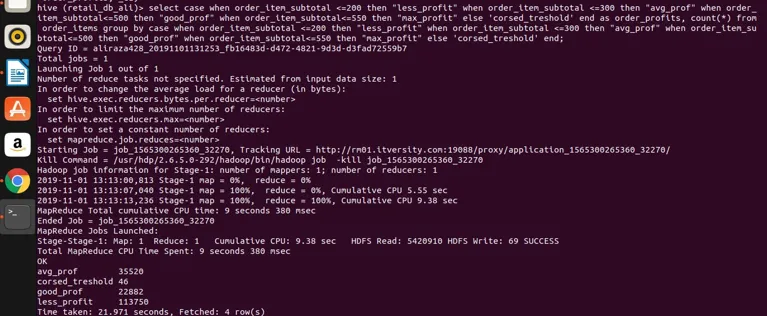
Következtetés - Hive Group By
így láthatjuk, hogy a order_item_subtotal-t négy különböző kategóriába csoportosítottuk (ha megjegyezzük, hogy a order_item_subtotal nem aggregálódó oszlop, és a közvetlen csoport nem alkalmazható rajta), és összecsoportosítottuk őket, és számukra is megkaptuk a azokat az értékeket, amelyek kielégítik a kiválasztott kifejezésben meghatározott tartományt. Itt az egyszerű szabály, ha az oszlop nem sorolódik, és a kiválasztott kifejezésünk összetett, akkor bármi is van a kiválasztott kifejezésben, amelynek szintén jelen kell lennie a csoportban kifejezés kifejezéssel. Tehát láttuk, hogy a híres RDBMS záradékcsoport miként is korlátozások nélkül alkalmazható a Kaptárban. Alkalmazható egyszerű kiválasztott kifejezésekre. Összesített és szűrő kifejezések, csatlakozási kifejezések és komplex CASE kifejezések is.
Ajánlott cikkek
Ez egy útmutató a Hive Group By-nak. Itt tárgyaljuk a csoportot szintaxis szerint, a kaptárcsoport példáit, különféle feltételekkel és megvalósítással. A következő cikkeket is megnézheti további információkért -
- Csatlakozik a kaptárba
- Mi a kaptár?
- Kaptár építészet
- Kaptár funkció
- Kaptárrendelés
- Kaptár telepítése
- A MySQL 6 legfontosabb csatlakozási típusa példákkal