
Mi a GLM az R-ben?
Az általánosított lineáris modellek a lineáris regressziós modellek egy részhalmaza, és hatékonyan támogatják a nem normális eloszlásokat. Ennek alátámasztására javasolt a glm () függvény használata. A GLM jól működik egy változóval, ha a szórás nem állandó és eloszlásban van. A kapcsolat függvényt úgy definiálják, hogy a válaszváltozót a megfelelő modellhez illeszsse. Az LM modell a családdal és a képlettel egyaránt készül. A GLM modellnek három kulcskomponense van: random (valószínűség), szisztematikus (lineáris prediktor), link komponens (logit függvény). A glm használatának előnye, hogy modellek rugalmassága, nem szükséges állandó szórás, és ez a modell illeszkedik a maximális valószínűség becsléséhez és arányaihoz. Ebben a témában megismerjük a GLM-et R-ben.
GLM funkció
Szintaxis: glm (képlet, család, adatok, súlyok, részhalmaz, Start = null, modell = igaz, módszer = ””)
Itt a családtípusok (ideértve a modelltípusokat) ide tartoznak a binomiális, a Poisson, a Gaussian, a gamma, a kvázi. Mindegyik eloszlás eltérő felhasználást hajt végre, és felhasználható mind besorolásra, mind előrejelzésre. És ha a modell gaussiai, a válasznak valódi egésznek kell lennie.
És amikor a modell binomiális, a válasznak bináris értékekkel kell osztályozni.
És ha a modell Poisson, a válasznak negatívnak kell lennie, numerikus értékkel.
És ha a modell gamma, akkor a válasznak pozitív számértéknek kell lennie.
glm.fit () - A modell illesztéséhez
Lrfit () - logisztikus regressziós illesztést jelöl.
update () - segít a modell frissítésében.
anova () - választható teszt.
Hogyan hozhatunk létre GLM-et R-ben?
Itt meglátjuk, hogyan hozhatunk létre egy egyszerű, általánosított lineáris modellt bináris adatokkal a glm () függvény felhasználásával. És folytatva a Trees adatkészletet.
Példák
// Könyvtár importálásalibrary(dplyr)
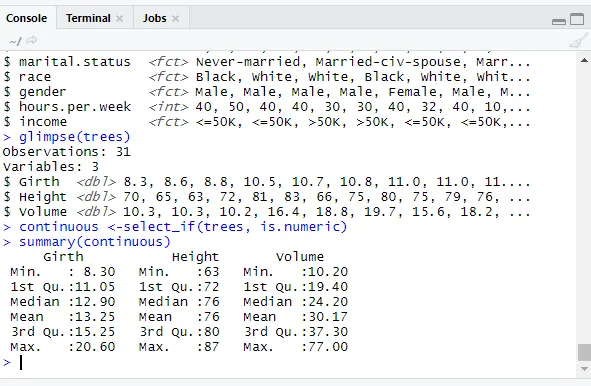
glimpse(trees)

A kategorikus értékek megtekintéséhez tényezőket rendelnek hozzá.
levels(factor(trees$Girth))
// Folyamatos változók ellenőrzése
library(dplyr)
continuous <-select_if(trees, is.numeric)
summary(continuous)
// Beleértve a fa adatkészletet az R keresés Pathattach-jába (fák)
x<-glm(Volume~Height+Girth)
x
Kimenet:
| Hívás: glm (képlet = Volume ~ Magasság + Kerület)
együtthatók: Magasság Girth -57.9877 0.3393 4.7082 Szabadságfokok: Összesen 30 (azaz Null); 28 Maradék Null Deviance: 8106 Maradékváltás: 421, 9 AIC: 176, 9 |
summary(x)
| Hívás:
glm (képlet = térfogat ~ magasság + kerület) Deviance maradványok: Min. 1Q Medián 3Q Max -6, 4065 -2, 6493 -0, 2876 2, 2003 8, 4847 együtthatók: Estimate Std. Hiba t érték Pr (> | t |) (Lehallgatás) -57.9877 8.6382 -6.713 2.75e-07 *** Magasság 0.3393 0.1302 2.607 0.0145 * Girth 4.7082 0.2643 17.816 <2e-16 *** - Signif. kódok: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (A gauss-család diszperziós paramétere 15.06862) Null eltérés: 8106.08 30 szabadsági fokon Megmaradt eltérés: 421, 92 a 28 szabadságfokon AIC: 176, 91 Fisher pontozási iterációk száma: 2 |
Az összefoglaló függvény kimenete megadja a hívásokat, együtthatókat és maradványokat. A fenti válasz azt mutatja, hogy mind a magasság, mind a kerület együtthatója nem szignifikáns, mivel valószínűsége kevesebb, mint 0, 5. És van két eltérési változat, null és reziduális. Végül, a fisher pontozása egy olyan algoritmus, amely megoldja a maximális valószínűséggel kapcsolatos kérdéseket. A binomiális válasz esetén a válasz vektor vagy mátrix. A cbind () -et arra használják, hogy az oszlopvektorokat mátrixban kössék. És az illeszkedésről szóló összefoglaló részletes információk megszerzéséhez használjuk.
Ehhez hasonlóan a motorháztető teszthez a következő kód kerül végrehajtásra.
step(x, test="LRT")
Start: AIC=176.91
Volume ~ Height + Girth
Df Deviance AIC scaled dev. Pr(>Chi)
421.9 176.91
- Height 1 524.3 181.65 6.735 0.009455 **
- Girth 1 5204.9 252.80 77.889 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call: glm(formula = Volume ~ Height + Girth)
Coefficients:
(Intercept) Height Girth
-57.9877 0.3393 4.7082
Degrees of Freedom: 30 Total (ie Null); 28 Residual
Null Deviance: 8106
Residual Deviance: 421.9 AIC: 176.9
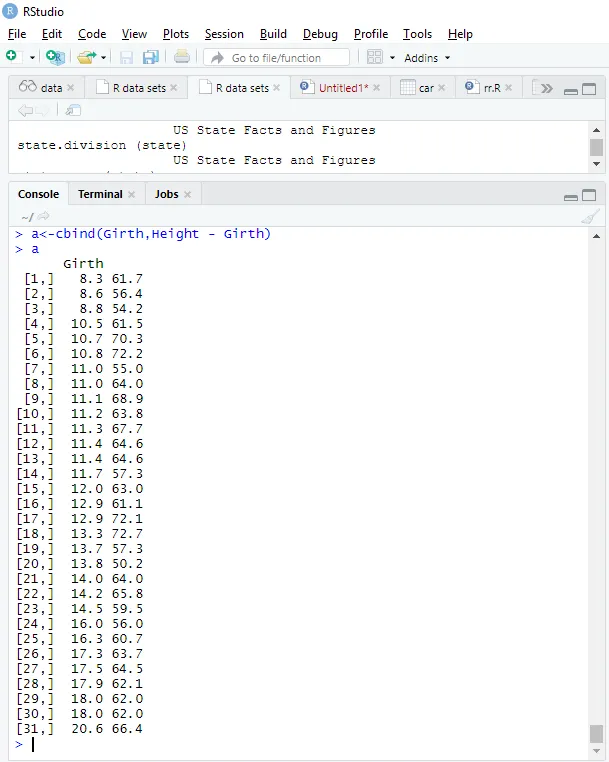
Modell illeszkedik
a<-cbind(Height, Girth - Height)
> a
összefoglaló (fák)
Girth Height Volume
Min. : 8.30 Min. :63 Min. :10.20
1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
Median :12.90 Median :76 Median :24.20
Mean :13.25 Mean :76 Mean :30.17
3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
Max. :20.60 Max. :87 Max. :77.00
A megfelelő szórás eléréséhez
apply(trees, sd)
Girth Height Volume
3.138139 6.371813 16.437846
predict <- predict(logit, data_test, type = 'response')
Ezután a válasz-válasz változóra hivatkozunk, a jó válasz illeszkedésének modellezésére. Ennek kiszámításához az USAccDeath adatkészletet fogjuk használni.
Írjuk be az alábbi kivonatokat az R konzolba, és nézzük meg, hogy az évszám és az év négyzet hogyan történik rajtuk.
data("USAccDeaths")
force(USAccDeaths)
// Az 1973-1978 közötti év elemzése.
disc <- data.frame(count=as.numeric(USAccDeaths), year=seq(0, (length(USAccDeaths)-1), 1)))
yearSqr=disc$year^2
a1 <- glm(count~year+yearSqr, family="poisson", data=disc)
summary(a1)
| Hívás:
glm (képlet = szám ~ év + évSqr, család = „poisson”, adat = lemez) Deviance maradványok: Min. 1Q Medián 3Q Max -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 együtthatók: Estimate Std. Hiba z érték Pr (> | z |) (Elhallgatás) 9.187e + 00 3.557e-03 2582.49 <2e-16 *** -7.207e-03 2.354e-04 -30.62 év <2e-16 év *** yearSqr 8.841e-05 3.221e-06 27.45 <2e-16 *** - Signif. kódok: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (A Poisson család diszperziós paramétere 1-nek tekinthető) Null eltérés: 7357, 4 71 szabadsági fokon Megmaradó eltérés: 6358, 0 69 szabadságfokon AIC: 7149.8 Fisher pontozási iterációk száma: 4 |
A modell legmegfelelőbb ellenőrzéséhez a következő parancs használható a kereséshez
a vizsgálat maradványai. Az alábbiak szerint az érték 0.
1 - pchisq(deviance(a1), df.residual(a1))
A QuasiPoisson család használata az adott adatok nagyobb szórásához
a2 <- glm(count~year+yearSqr, family="quasipoisson", data=disc)
summary(a2)
| Hívás:
glm (képlet = szám ~ év + évSqr, család = „quasipoisson”, adatok = lemez) Deviance maradványok: Min. 1Q Medián 3Q Max -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 együtthatók: Estimate Std. Hiba t érték Pr (> | t |) (Elhallgatás) 9.187e + 00 3.417e-02 268.822 <2e-16 *** év -7.207e-03 2.261e-03 -3.188 0.00216 ** yearSqr 8.841e-05 3.095e-05 2.857 0.00565 ** - (A quasipoisson család diszperziós paramétere 92, 28857 lesz.) Null eltérés: 7357, 4 71 szabadsági fokon Megmaradó eltérés: 6358, 0 69 szabadságfokon AIC: NA Fisher pontozási iterációk száma: 4 |
A Poisson és a binomiális AIC érték összehasonlítása jelentősen eltér. Elemezhetők pontosság és visszahívási arány alapján. A következő lépés annak ellenőrzése, hogy a maradék-variancia arányos-e az átlaggal. Ezután a ROCR könyvtár használatával megtervezhetjük a modell javítását.
Következtetés
Ezért az általánosított lineáris modellnek nevezett speciális modellre összpontosítottunk, amely segít a modell paramétereinek fókuszálásában és becslésében. Elsősorban a folyamatos válaszváltozó potenciálja. És láttuk, hogy a glm hogyan illeszkedik az R beépített csomagokhoz. Ezek a legnépszerűbb módszerek a számlálási adatok mérésére, és az adattudós által alkalmazott osztályozási technikák robusztus eszköze. Az R nyelv természetesen segíti a bonyolult matematikai funkciók elvégzését
Ajánlott cikkek
Ez egy útmutató a GLM számára R-ben. Itt tárgyaljuk a GLM függvényt és a GLM létrehozásának módját R-ben a faadatok példáival és kimeneteivel. A következő cikkben további információkat is megnézhet -
- R programozási nyelv
- Big Data architektúra
- Logisztikus regresszió R-ben
- Nagy adat-elemzési munkák
- Poisson regresszió az R-ben A Poisson regresszió végrehajtása