

A Kafka alkalmazások áttekintése
Az informatikai ipar egyik trendje a Big Data, ahol a vállalat nagy mennyiségű ügyféladattal foglalkozik, és hasznos betekintést nyer, amely segíti az üzleti vállalkozást és jobb kiszolgálást kínál az ügyfelek számára. Az egyik kihívás az, hogy ezeket a nagy mennyiségű adatot kezeljük és továbbítsuk egyik végükről a másikra elemzésre vagy feldolgozásra. Itt jelenik meg a Kafka (megbízható üzenetküldő rendszer), amely elősegíti a hatalmas mennyiségű adat gyűjtését és szállítását. valós időben. A Kafkát elosztott nagy teljesítményű rendszerekre tervezték, és nagyszerűen alkalmazható nagyszabású üzenetfeldolgozó alkalmazásokhoz. A Kafka támogatja a mai legtöbb kereskedelmi és ipari alkalmazást. Szükség van olyan Kafka szakemberekre, akiknek erős készségeik és gyakorlati ismereteik vannak.
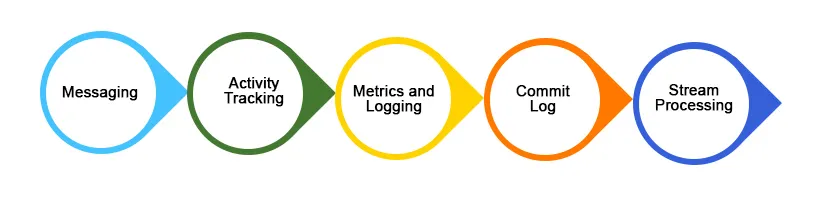
Ebben a cikkben megismerjük a Kafkát, annak jellemzőit, felhasználási eseteit és megismerjük néhány figyelemre méltó alkalmazást, ahol használják.
Mi a Kafka?
Az Apache Kafkát a LinkedIn-ben fejlesztették ki, később nyílt forrású Apache-projektgé vált. Az Apache Kafka egy gyors, hibatűrő, skálázható és elosztott üzenetküldő rendszer, amely lehetővé teszi kommunikációt két entitás között, azaz a termelők (az üzenet generátora) és a fogyasztók (az üzenet fogadója) között üzenet alapú témák segítségével, és platformot biztosít az összes a valós idejű adattáblák.
Az olyan szolgáltatások, amelyek jobbá teszik az Apache Kafkát, mint a többi üzenetküldő rendszer, és alkalmazhatók a valósidejű rendszerekre, a magas rendelkezésre állás, azonnali, automatikus helyreállítás a csomópontok hibáitól és támogatják az alacsony késleltetésű üzenetek kézbesítését. Az Apache Kafka ezen tulajdonságai elősegítik a nagyméretű adatrendszerek integrálását, és ideális összetevővé teszik a kommunikációt. 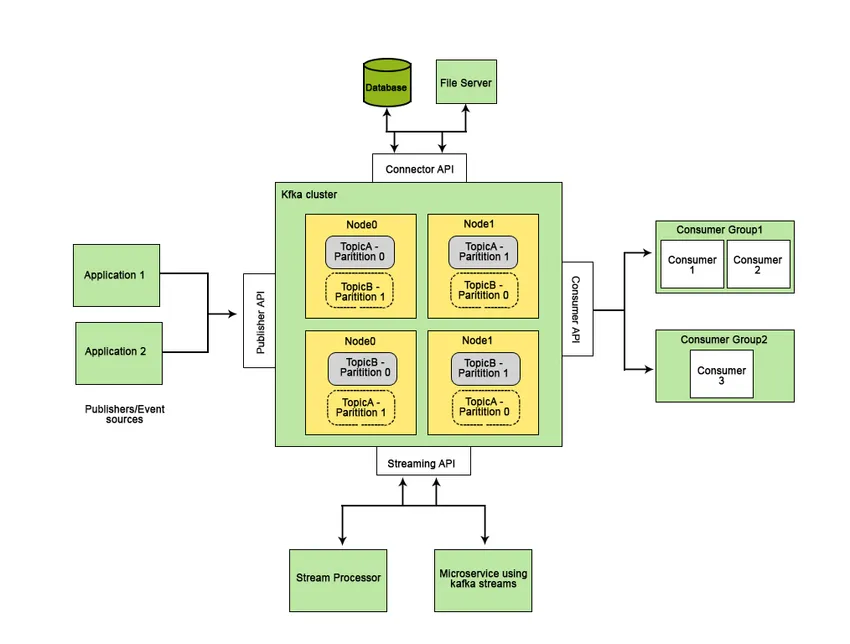
A legnépszerűbb Kafka alkalmazások
A cikk ezen részében néhány népszerű és széles körben alkalmazott felhasználási esetet, valamint a Kafka valós megvalósítását látjuk.
Valós alkalmazások
1. Twitter: adatfeldolgozási tevékenység
A Twitter egy olyan szociális hálózati platform, amely a Storm-Kafkát (nyílt forrású adatfeldolgozó eszköz) használja adatfolyam-feldolgozási infrastruktúrájának részeként, ahol a bemeneti adatokat (tweetteket) felhasználják az összesítésre, átalakításokra és dúsításra további fogyasztás vagy nyomon követés céljából. feldolgozási tevékenységek.
2. LinkedIn: adatfeldolgozás és metrikák
A LinkedIn a Kafkát használja az adatok streamingjéhez és az operatív metrikus tevékenységekhez. A LinkedIn a Kafkát olyan kiegészítő funkcióinak felhasználására használja, mint például a Newsfeed az üzenetek fogyasztására és a kapott adatok elemzésére.
3. Netflix: Valós idejű megfigyelés és adatfolyam-feldolgozás
A Netflix rendelkezik saját beillesztési keretrendszerrel, amely a bemeneti adatokat az AWS S3-ba dobja, és a Hadoop segítségével videofolyamok elemzését, felhasználói felület tevékenységeket, eseményeket fejleszti a felhasználói élmény fokozása érdekében, valamint a Kafka szolgáltatást valósidejű adatfelvételhez az API-k segítségével.
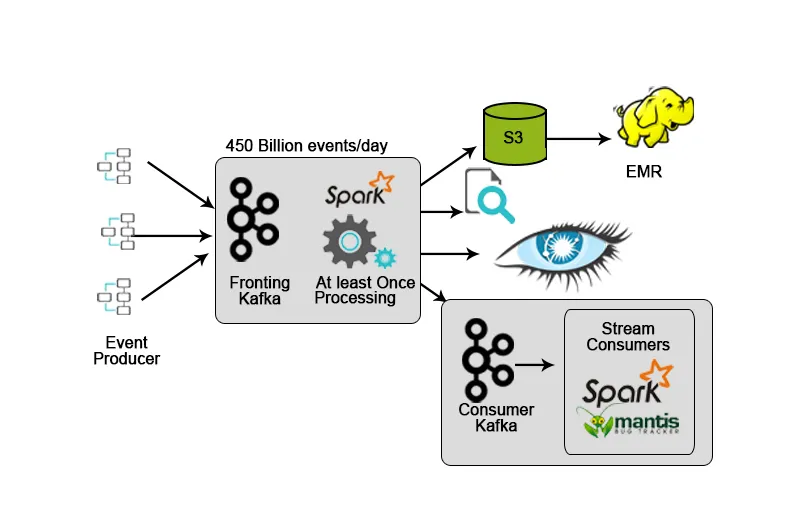
4. Hotstar: adatfeldolgozás
A Hotstar bemutatta a saját adatkezelési platformját - a Bifrost-ot, ahol a Kafkát használják az adatfolyamhoz, a megfigyeléshez és a célkövetéshez. Skálázhatóságának, elérhetőségének és alacsony késleltetési képességeinek köszönhetően a Kafka ideális választás volt azon adatok kezelésére, amelyeket a hotstar platform napi rendszerességgel vagy bármilyen különleges alkalomra (koncertek élő közvetítése, koncertek élő közvetítése stb.) az adatmennyiség jelentősen növekszik.
Az Apache Kafka legtöbbször építőköveként kerül felhasználásra az adatfolyam-architektúra fejlesztésére. Ezt a fajta architektúrát alkalmazzák olyan alkalmazásokban, mint például a termék- / szervernaplók gyűjtése, a kattintásáram elemzése és az információk kiszámítása a géppel generált adatokból.
De a Kafkával együtt további erőforrásokat vagy eszközöket kell használnunk a kapott adatfolyamnak olyan értelmes adatokké konvertálására, amely elősegíti az adatközpontú döntésekhez felhasználható betekintést. Előfordulhat például, hogy betekintést kell nyernünk az IoT eszközökből nyert nyers adatokból vagy a szociális média platformjaiból nyert adatokból valós időben, és végezzünk elemzést vagy feldolgozást, és bemutassuk az üzleti vállalkozásnak, hogy jobb döntéseket hozzon, vagy segítsen nekik a fejlesztésben szolgáltatásaik teljesítését.
Az ilyen típusú felhasználási esetekben bemeneti / nyers adatainkat adat-tóba szeretnénk közvetíteni, ahol adatainkat tárolhatjuk és az adatok minőségét a teljesítmény akadályozása nélkül biztosíthatjuk.
Más helyzet lehet, ha közvetlenül a Kafka adatait olvassa be, amikor rendkívül alacsony végpontok közötti késésre van szükségünk, például az adatok valósidejű alkalmazásokhoz való adagolására.
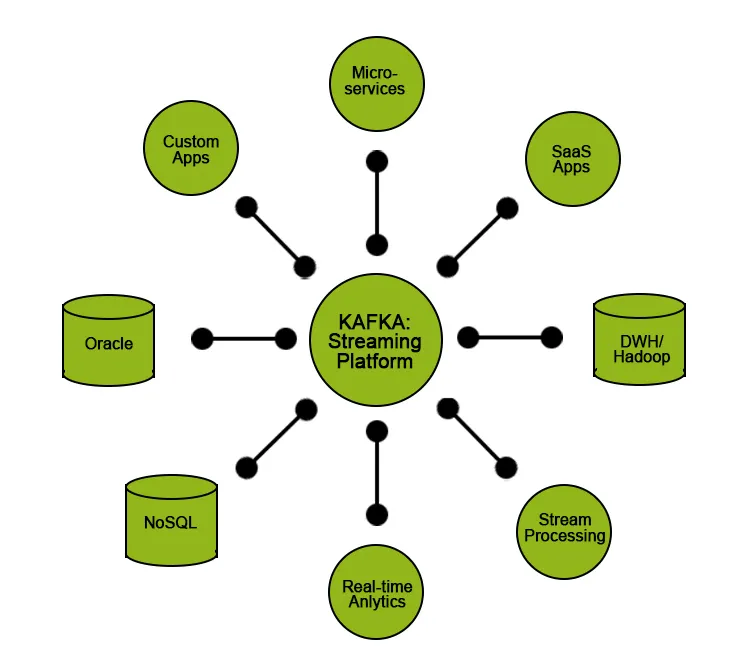
A Kafka bizonyos funkciókat határoz meg felhasználói számára:
- Tegye közzé és iratkozzon fel az adatokra.
- Tárolja az adatokat a hatékony előállításuk sorrendjében.
- Az adatok valós idejű / repülés közbeni feldolgozása.
A Kafkát általában az alábbiakra használják:
- Olyan on-the-fly streaming adatcsatornák bevezetése, amelyek megbízhatóan szolgáltatnak adatokat a rendszerben lévő két entitás között.
- Az adatfolyamokat átalakító, manipuláló vagy feldolgozó on-the-line streaming alkalmazások megvalósítása.
Használjon tokot
Az alábbiakban bemutatjuk a Kafka alkalmazás néhány, széles körben alkalmazott felhasználási esetét:
1. Üzenetek
A Kafka jobban működik, mint más hagyományos üzenetküldő rendszerek, mint például az ActiveMQ, RabbitMQ stb. Összehasonlításképpen a Kafka jobb átviteli képességet, beépített partíciót, replikációt és hibatűrő képességeket kínál, ami jobb üzenetküldő rendszert jelent a nagyméretű feldolgozási alkalmazásokhoz. .
2. A webhely tevékenységének követése
A felhasználói tevékenységek (oldalmegtekintések, keresések vagy bármilyen elvégzett művelet) nyomon követhetők és táplálhatók valós idejű megfigyeléshez vagy elemzéshez a Kafkán keresztül, vagy a Kafka segítségével tárolhatja az ilyen típusú adatokat a Hadoopba vagy az adattárházba későbbi feldolgozás vagy manipuláció céljából. A tevékenységkövetés hatalmas mennyiségű adatot generál, amelyet a kívánt helyre kell továbbítani anélkül, hogy bármilyen adatvesztés lenne.
3. Naplóösszetétel
A naplóösszegzés egy fizikai naplófájlok összegyűjtése / egyesítése az alkalmazás különböző kiszolgálóiról egyetlen lerakatba (fájlkiszolgáló vagy HDFS) feldolgozás céljából. A Kafka jó teljesítményt nyújt, alacsonyabb végpontok közötti látenciát mutat a Flume-hoz képest.

Következtetés
A Kafkát nagy adatelérben használják annak érdekében, hogy nagy mennyiségű adatot gyorsan begyűjtsenek és mozgathassanak, teljesítmény jellemzői és jellemzői miatt, amelyek elősegítik a skálázhatóságot, megbízhatóságot és fenntarthatóságot. Ebben a cikkben megvitattuk az Apache Kafka jellemzőit, felhasználási eseteit és alkalmazását, és mi teszi az adatfolyam jobb eszközévé.
Ajánlott cikkek
Ez egy útmutató a Kafka Applications alkalmazáshoz. Itt megvitatjuk, mi a Kafka, a Kafka legfontosabb alkalmazásaival együtt, amelyek kiterjednek a széles körben megvalósított használati esetekre és néhány valós életvitelre. A következő cikkeket is megnézheti további információkért -
- Mi a Kafka?
- Hogyan telepítsük a Kafkát?
- Kafka interjúkérdések
- Apache Kafka vs Flume
- A tárgyak internetének 8 legfontosabb eszköze, amelyet tudnia kell
- Kafka vs Kinesis Különbségek az infographics-ban
- Különböző típusú alkatrészek a Kafka szerszámokhoz
- Ismerje meg az ActiveMQ és a Kafka legfontosabb különbségeit