

Bevezetés a hash-hoz a DBMS-ben
Amikor a hatalmas adatbázis-felépítésről és azok bonyolultságáról beszélünk, akkor nagyon hatékonnyá válik az összes index keresése, és a kívánt adatok elérése nagyon homályos és összetett lehetőség. A hash technikának alkalmazásával ezek az állapotok elérhetők, és egy közvetlen mutató hozzárendelhető, hogy megismerje az adott rekord pontos és közvetlen helyét a lemezen anélkül, hogy felhasználná a komplex index struktúrát. A kivonási technika esetén az adatokat olyan adatblokkok formájában tárolják, amelyek címét a kivonási funkcióként általában ismert funkció felhasználásával állítják elő. A memória azon helyét, ahol ez található, és a rekordokat tárolják, adatblokkoknak vagy adatvödröknek nevezzük.
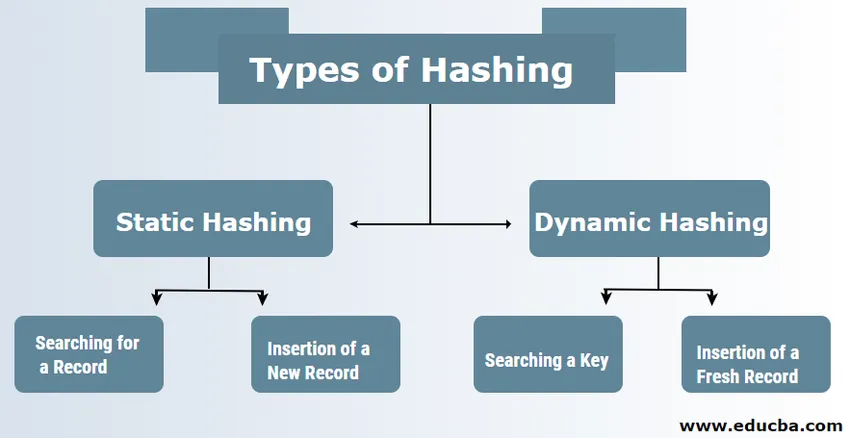
A hashing típusai a DBMS-ben
A DBMS-ben általában kétféle kivonási technika létezik:
1. Statikus hashizálás
2. Dinamikus hashizálás
1) Statikus hashizálás
Statikus kivonás esetén a kialakított adatkészlet és a vödör címe megegyezik. Ez azt jelenti, hogy ha megpróbáljuk a USER_ID = 113 címet előállítani az 5 hash funkció funkciómodul felhasználásával, akkor a 3. eredményt mindig ugyanazzal a vödör címmel látja el. Ebben az esetben a megadott vödör címe nem változik. Ezért a vödrök száma állandó marad a művelet során.
Statikusan tipizált hashing működése
a. Rekordok keresése: Ha szükség van a rekordra, akkor pontosan ugyanazt a kivonási funkciót kell használni az adatvödör címének és elérési útjának lekérésére a tárolt adatokkal együtt.
b. Új rekord beillesztése: Ha egy új és friss rekordot beillesztenek egy asztalba, akkor egy új rekordhoz egy címet generálnak a hash-kulcs alapján, ezáltal a rekordot az adott helyre tárolva.
- A bejegyzés törlése: A bejegyzés törléséhez először le kell töltenie azt a bejegyzését, amely törölhető. Miután ezt a feladatot elvégezte, törölnie kell a memóriacímhez tartozó rekordokat.
- Egy rekord frissítése : A rekord frissítéséhez először a hash-alapú funkció használatával keressük meg a rekordot, és miután megtettük, akkor azt mondhatjuk, hogy az adatrekordja frissített állapotban van. Annak érdekében, hogy új rekordot illessünk be a fájlba, és a hash-alapú funkcióból és az adat-vödörből generált cím nem üres, vagy ha az adatok már vannak a megadott címen. Ezt a helyzetet, amely különösen a statikus hasítás esetén jelentkezik, jobban nevezzük a vödör túlcsordulásának, ezért a probléma leküzdésére van néhány módszer, például:
(i) Nyitott hashizálás: Ha egy kivonatoló funkció létrehozza azt a címet, amelyre az adatok már tárolt állapotban is láthatók, akkor a vödör következő szintje automatikusan kiosztásra kerül. Ezt a mechanizmust lineáris tapintási technikának lehet nevezni.
Például, ha R3 az a friss cím, amelyet el kell helyezni, akkor a hash-alapú függvény az R3 cím 102-es számát generálja. A létrehozott cím teljes állapotban van, ezért a rendszernek az a célja, hogy megkeresse az új 113-as adatcsomagot, és az R3-t hozzárendeli ehhez az adat-csoporthoz.
(ii) Zárt hashing: Amikor a vödrök teljesen megtelnek, egy új vödröt allokálnak egy adott hash-eredményhez, amelyet közvetlenül összekapcsolnak a korábban elvégzett módszerrel, és ezért ezt a módszert Overflow chaining technikának hívják.
Például R3 az a friss cím, amelyet be kell tölteni az új táblába, a kivonási funkcióval pedig a 110-es címként generálódik a cím. Ez a vödör viszont tele van, és ezért nem tud új adatokat fogadni, ezért 100 végi után egy friss vödör kerül a végére.
2) Dinamikus hashizálás
Ez a fajta hash-alapú módszer felhasználható a statikus alapú hash-ok olyan alapvető problémáinak megoldására, mint például a vödör túlcsordulása, mivel az adat-vödrök növekedhetnek és összehúzódhatnak, mivel ez nagyobb tér-optimalizált módszer, ezért kibővíthetőnek hívják. hash-alapú módszer. Ebben a módszerben a hasítás dinamikussá válik, ami azt jelenti, hogy a beillesztési tevékenység vagy a törlés megengedett anélkül, hogy rossz teljesítményt nyújtana.
a. Kulcs keresése: Számítsa ki a szükséges kulcs hash-alapú címét, és ellenőrizze az i-nek nevezett könyvtár esetén használt bitszámot. Ezután azokat a könyvtárat veszik át, amelyek a legkevésbé jelentik az I biteket, és amelyek képet adnak a könyvtárban szereplő indexről. Ennek az indexértéknek a felhasználásával lépjen a könyvtárba, és keresse meg a vödör címét a jelenlegi rekordok kereséséhez.
b. Friss rekord beszúrása: Először ugyanazt a visszakeresési eljárást kell követnie, amelyet valahol a vödörben kell végezni. Keresse meg a helyet a vödörben, majd tegye bele a rekordokat. Ha a létrehozott vödör teljes és tele van, akkor a vödör felosztásra kerül, és a rekordok újraelosztásra kerülnek.
Például a 2. és a 4. szám utolsó két bitje 00 van. Tehát bemegyek a B0 vödörbe és így tovább, a modulusfüggvény függvényében. A 9 kulcs címe 10001, amelynek jelen kell lennie az első vödörben, de megosztódik, és az új B1 vödörbe költözik, és addig folytatódik, amíg az összes vödör és kulcs dinamikusan ki nem hasad. A hash-funkciót olyan módon használják, ahol a hash-funkcióval az oszlopot és annak értékét választják ki a cím generálásához. A hash függvény maximális alkalma az elsődleges kulcsot használja, amelyet viszont az adatblokk címeinek előállításához használnak. Ez egy egyszerű matematikai függvény, ahol az elsődleges kulcs adatblokk címének is tekinthető, ami azt jelenti, hogy az első sorban ugyanazzal a címmel rendelkező sor minden adatot el fog tárolni.
Ajánlott cikkek
Ez egy útmutató a Hashing számára a DBMS-ben. Itt tárgyaljuk a bevezetést és a különféle típusú kivonásokat a DBMS-ben, amely tartalmaz egy statikus és dinamikus kivonatolást, valamint példákat. Lehet, hogy megnézi a következő cikkeket is, ha többet szeretne megtudni -
- Adatmodellek a DBMS-ben
- A DBMS előnyei
- Adatintegrációs eszköz
- Mi az RDBMS?