

Bevezetés a kaptárparancsokba
A Hive parancs egy adattárház-infrastruktúra eszköz, amely a Hadoop tetején ül a nagy adatok összefoglalására. Strukturált adatokat dolgoz fel. Megkönnyíti az adatok lekérdezését és elemzését. A kaptár parancsot „séma olvasáskor” -nak is hívják. A kaptár nem ellenőrzi az adatokat betöltésekor, az ellenőrzés csak lekérdezés kiadásakor történik. A Hive tulajdonsága megkönnyíti az első berakodást. Olyan, mint egy fájl lemásolása vagy egyszerű áthelyezése bármilyen korlátozás vagy ellenőrzés nélkül. A kaptár először a Facebook fejlesztette ki. Az Apache Software Foundation később felvette és továbbfejlesztette.
Íme a Hive parancs komponensei:
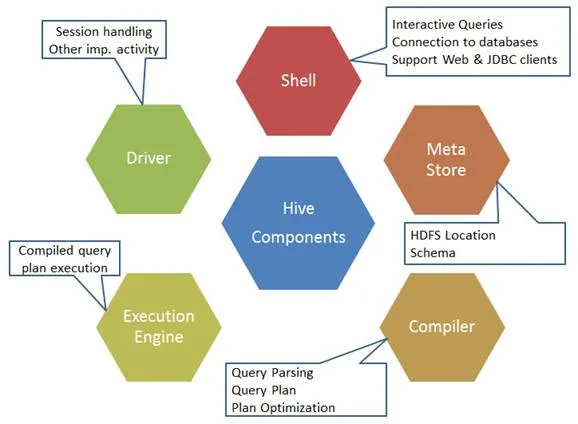
1. ábra: A kaptár összetevői
https://www.developer.com/
Az alábbiakban felsoroljuk a Kaptár parancs tulajdonságait:
- A kaptárboltok nyers és feldolgozott adatkészlet a Hadoopban.
- Úgy tervezték, hogy online tranzakciós feldolgozásra (OLTP) folytasson. Az OLTP azok a rendszerek, amelyek nagyon sok idő alatt megkönnyítik a nagy mennyiségű adatot, egyetlen kiszolgálóra támaszkodva.
- Gyors, méretezhető és megbízható.
- Az itt megadott SQL típusú lekérdezési nyelv HiveQL vagy HQL. Ez megkönnyíti az ETL feladatokat és az egyéb elemzéseket.
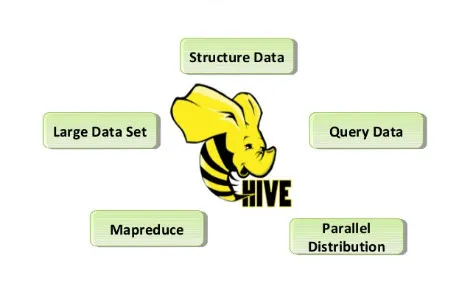
2. ábra Kaptár tulajdonságai
Forrásképek: - Google
A Hive parancsra is vannak néhány korlátozás, amelyeket alább sorolunk fel:
- A kaptár nem támogatja a részkereséseket.
- A Hive biztosan támogatja a túlírást, de sajnos nem támogatja a törlést és a frissítéseket.
- A kaptárt nem OLTP számára fejlesztették ki, de ehhez használják.
A kaptár interaktív héjába belépés:
$ HIVE_HOME / bin / kaptár
Alapvető kaptárparancsok
-
teremt
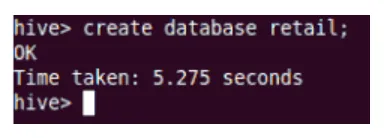
Ez létrehozza az új adatbázist a Hive-ben.
-
Csepp
A csepp eltávolítja asztalt a kaptárból
-
Változtat
Az Alter parancs segít az asztal vagy az oszlopok átnevezésében.
Például:
kaptár> VÁLTOZATTÁBLÁZAT MEGNEVEZÉSE AZ alkalmazott1;
-
Előadás
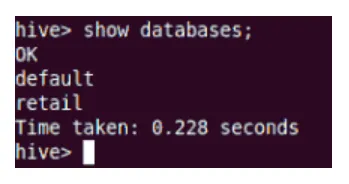
A Show parancs megmutatja a Hive-ben található összes adatbázist.
-
Ismertesse
A Leírás parancs segít a táblázat sémájával kapcsolatos információkkal.
Köztes kaptárparancsok
A Hive oszlopok alapján osztja meg a táblákat különféle módon kapcsolódó partíciókra. Ezeket a partíciókat használva könnyebb lesz lekérdezni az adatokat. Ezeket a partíciókat tovább osztják vödrökre, hogy hatékonyan futtassák le az adatokat.
Más szóval, a vödrök az adatokat a klaszterek halmazába osztják el a lekérdezésben említett kulcs kivonatkódjának kiszámításával.
-
Partíció hozzáadása
A partíció hozzáadása a tábla megváltoztatásával valósítható meg. Tegyük fel, hogy van „EMP” táblája, olyan mezőkkel, mint például az Id, a név, a fizetés, az osztály, a kijelölés és a yoj.
kaptár> ALTER TABLE alkalmazott
> RÉSZ hozzáadása (év = '2012')
tartózkodási hely '/ 2012 / part2012';
-
Partíció átnevezése
kaptár> ALTER TÁBLÁZAT munkavállalói RÉSZ (év = '1203')
RENAME OF PARTITION (Yoj = '1203');
-
Csepp partíció
kaptár> VÁLTOZATTÁBLÁZAT munkavállalói csepegtetés (HA létezik)
> PARTÍCIÓ (év = '1203');
-
Relációs operátorok
A relációs operátorok bizonyos operátorkészletből állnak, amelyek elősegítik a vonatkozó információk beolvasását.
Például: Mondja el, hogy az „EMP” táblázata így néz ki:
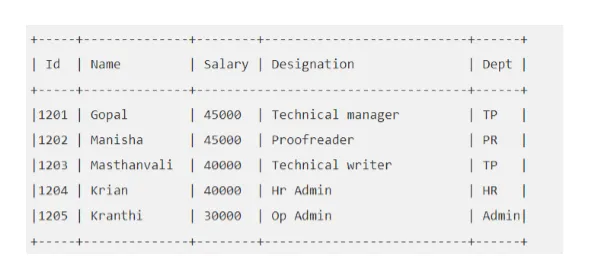
Végezzük el a Hive lekérdezést, amely megkapja nekünk az alkalmazottat, akinek a fizetése meghaladja a 30000-at.
kaptár> KIVÁLASZT * EMP-BŐL, Ahol fizetés> = 40000;
-
Számtani operátorok
Ezek olyan operátorok, amelyek segítenek a számtani műveletek végrehajtásában az operandusokon, és viszont mindig visszatérnek a számtípusokhoz.
Például: Két szám hozzáadásához, például 22 és 33
kaptár> SELECT 22 + 33 ADD FROM temp;
-
Logikai operátor
Ezeknek az operátoroknak logikai műveleteket kell végrehajtaniuk, amelyek cserébe mindig igaz / hamis értéket adnak vissza.
kaptár> KIVÁLASZT * EMP-BŐL, Ahol fizetés> 40000 && Dept = TP;
Speciális kaptárparancsok
-
Kilátás
A View koncepció a Hive-ben hasonló, mint az SQL. A nézet a SELECT utasítás végrehajtásakor hozható létre.
Példa:
kaptár> CREATE VIEW EMP_30000 AS
Kiválasztás * az EMP-től
Ahol fizetése> 30000;
-
Adatok betöltése a táblázatba
Kaptár> Töltse be az adatok helyi '/home/hduser/Desktop/AllStates.csv' táblázati állapotait;
Itt az „Államok” a Hive már létrehozott táblája.
https://www.tutorialspoint.com/hive/
A Hive rendelkezik néhány beépített funkcióval, amelyek segítenek az eredmény jobb megszerzésében.
Mint kerek, padló, BIGINT stb.
-
Csatlakozik
A csatlakozási záradék segíthet két táblázat összekapcsolásában ugyanazon oszlopnév alapján.
Példa:
kaptár> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
ÜGYFELEKTŐL c CSATLAKOZÁSOK
BE (c.ID = o.CUSTOMER_ID);
A Hive támogat mindenféle csatlakozást: bal oldali külső csatlakozás, jobb külső csatlakozás, teljes külső csatlakozás.
Tippek és trükkök a kaptárparancsok használatához
A Hive megkönnyíti az adatfeldolgozást, egyértelművé és kibővíthetővé, és a felhasználó kevesebb figyelmet fordít a Hive lekérdezéseinek optimalizálására. Ha azonban a Hive lekérdezése közben figyelünk néhány dologra, ez nagy sikerrel jár a munkaterhelés kezelésében és a pénzmegtakarításban. Az alábbiakban bemutatunk néhány tippet erre vonatkozóan:
- Partíciók és vödrök: A kaptár egy nagy adatszerszám, amely nagy adatkészletekre képes lekérdezni. A lekérdezés írása a domain megértése nélkül azonban nagyszerű partíciókat eredményezhet a Hive-ben.
Ha a felhasználó tisztában van az adatkészlettel, akkor a releváns és a nagyon használt oszlopok csoportosíthatók ugyanabba a partícióba. Ez elősegíti a lekérdezés gyorsabb és nem hatékony végrehajtását.
Végül a nem. A térképező és az I / O műveletek száma szintén csökken.
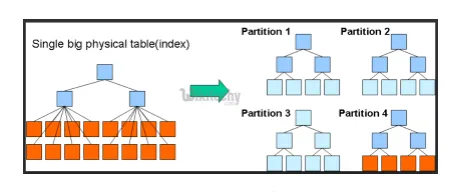
3. ábra
Források: Google kép
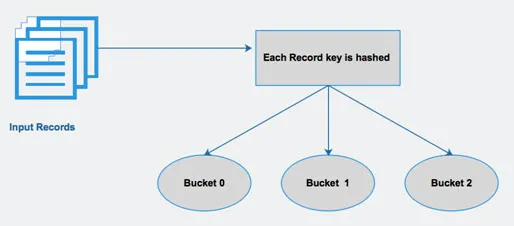
4. ábra Vödör
Forrásképek: - Google kép
- Párhuzamos végrehajtás: A kaptár több lépésben futtatja a lekérdezést. Bizonyos esetekben ezek a szakaszok függhetnek más szakaszoktól, így nem indulhat el, miután az előző szakasz befejeződött. A független feladatok azonban futtathatók párhuzamosan az általános futási idő megtakarítása érdekében. A párhuzamos futtatás engedélyezése a kaptárban:
set hive.exec.parallel = true;
Ez tehát javítja a klaszterek kihasználását.
- Mintavétel blokkolása: Az adatok mintavételezése egy táblából lehetővé teszi az adatokkal kapcsolatos lekérdezések feltárását.
A blokkolás ellenére inkább véletlenszerűen szeretnénk mintát venni. A blokk-mintavétel különféle erőteljes szintaxissal érkezik, amely különféle módon segíti az adatok mintavételét.
A mintavétel felhasználható kb. információ az adatkészletből, például az eredeti és a rendeltetési hely közötti átlagos távolság.
A nagy adatok 1% -ának lekérdezése megközelíti a tökéletes választ. A feltárás könnyebbé és hatékonyabbá válik.
Következtetés - Kaptárparancsok
A Hive magasabb szintű absztrakció a HDFS tetején, amely rugalmas lekérdezési nyelvet biztosít. Segít az adatok lekérdezésében és feldolgozásában.
A kaptár összeilleszthető más Big data elemekkel is, hogy funkcionalitását teljes mértékben kihasználhassa.
Ajánlott cikkek
Ez egy útmutató a Kaptárparancsokhoz. Itt megvitattuk az alapvető, valamint a fejlett Kaptárparancsokat és néhány azonnali Kaptárparancsot. A következő cikkben további információkat is megnézhet -
- Kaptárinterjúval kapcsolatos kérdések
- Hive VS Hue - A 6 legnépszerűbb összehasonlítás
- Tableau parancsok
- Adobe Photoshop parancsok
- Az ORDER BY funkció használata a kaptárban
- Töltse le és telepítse a kaptár lépésről lépésre