

Bevezetés a Python Regexbe
Napjainkban a Python a legfontosabb szó a tech iparban. Ez egy olyan nyelv, amely gyorsan növekszik. Ez egy nagyon dinamikus nyelv, és felhasználható webes alkalmazások készítésére gépi tanulási algoritmusokhoz. Ebben a cikkben megismerjük a Regex Pythonban történő használatát. A regex a reguláris kifejezés rövid formája, és alapvetõen karaktersorozat használható mintázatként. A jó dolog az, hogy a Pythonnak megvan a saját beépített Regex csomagja, az úgynevezett re.
Szintaxis:
A szintaxist egy példával fogjuk megérteni. Erre a példára kereshetünk egy karakterláncot, hogy megnézhessük: „He” -nel kezdődik és „smart” -val fejeződik be.
import reword = "He is very smart"
x =re.search("^He.*smart$", word)
print(x)
Ha megvizsgálja a szintaxist, ez nagyon egyszerű, akkor először csak importálnia kell a regex csomagot, amely újra van, majd használnia kell az importált csomag bármely funkcióját az igénye szerint. Ha a fenti mintakódot a Jupyterben futtatjuk, akkor az alábbi eredményt kapjuk.
Regex funkciók a Pythonban
Számos olyan regex funkció van, amelyek segítenek nekünk egy karakterlánc keresésében. Ezt megelőzően először megismerjük azokat a karaktereket, amelyeket általában egy regex funkcióban látunk.
|
() | Ez egy karakterkészletet képvisel. |
|
. | Bármely karaktert képvisel, kivéve egy új sort. |
|
* | 0 vagy annál több előfordulást jelent. |
|
+ | Egy vagy több eseményt képviseli. |
|
^ | Ez a kezdő karakter |
|
$ | Ez a befejező karakter. |
|
| |
Vagy vagy képviseli. |
|
() |
Ez a rögzítést és a csoportot képviseli. |
| \ |
Általában speciális karakterek elől menekülnek |
A Regexnek van néhány speciális szekvenciája is, amelyek hasznosak például a következők megismerésében:
|
\ w | Megmutatja az egyezést, ha a karakterláncon van valami szókarakterkészlet (0-9), AZ vagy az és aláhúzás alatt. |
|
\ W | Egyezést ad vissza, ha a karakterláncban nincsenek szókarakterek. |
|
\ d | Ezek a visszatérések megegyeznek, ha számjegyek vannak a karakterláncban. |
|
\ D | Ez ellentétes az előzővel, mivel egyezést ad vissza, ha a karakterláncban nincs számjegy. |
|
\ s | A szöveg szóköz karaktereinek ellenőrzésére szolgál. Visszaadja az egyezést, ha vannak szóköz karakterek. |
|
\ S | Visszaadja a mérkőzést, ha a szövegben nincs szóköz. |
A Regex műveletekhez használt funkciók
Nézzük meg az re modul különféle funkcióit, amelyek felhasználhatók a python regex műveleteire.
1. findall () függvény: Ez a funkció jelen van az új modulban. Visszaadja a karakterláncban található összes egyezés listáját. Balról jobbra itering a húron. A mérkőzések ugyanolyan keresési sorrendben kerülnek visszaadásra. Megismerünk erre egy példát. Tegyük fel, hogy meg akarjuk találni az összes karakterláncban jelen lévő számot. Ehhez a findall () függvényt fogjuk használni, amelyben megtalálja a karakterláncban lévő összes számot. Most nézzük meg ennek kódját:
Kód:
import re
word = "Raju is 22 years old and his mobile number last three-digit is 789"
rgex ='\d+'
x =re.findall(rgex, word)
print(x)
Ha átmegyünk a kódon, akkor alapvetően hozzárendeljük a változó szót egy számjegyeket tartalmazó karakterlánccal, majd átadjuk a megfelelő regex szimbólumot a számokhoz és a változó szót argumentumként a findall () függvényben
Most nézzük meg a kimenetet.
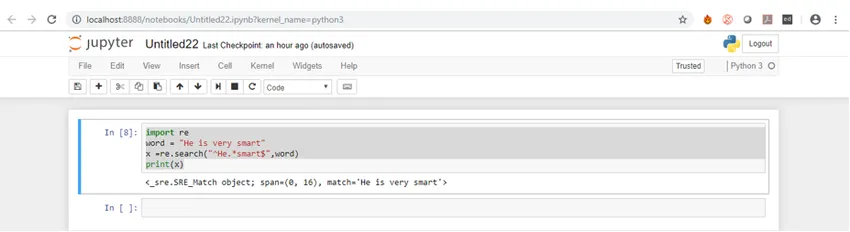
Mint láthatja, ennek eredményeként kapunk egy számok listáját.
2. keresés () függvény: A keresési függvény mintákat keres egy karakterláncban, és ha egyezés található, akkor visszaadja az objektumot. Itt egy olyan dolgot kell megjegyeznünk, hogy ha egynél több mérkőzés van, akkor csak az első eseményt adja vissza. Ha nem található egyezés, akkor semmit sem ad vissza. Látni fogunk egy példát erre a feltevésre, ha meg akarjuk találni egy adott szót tartalmazó karakterláncot. Teszteljük mind a pozitív, mind a negatív mérkőzés eseteit. Lássuk ugyanazt a kódot.
Kód:
import re
word = "Raju is 22 years old"
rgex ='^Raju'
x =re.search(rgex, word)
print(x)
regex1= '^Mohan'
x1 = re.search(regex1, word)
print(x1)
Itt a 'regex' változót használják a pozitív forgatókönyvben, a 'regex1' változót pedig a negatív forgatókönyvhöz. Most nézd meg a kimenetet.
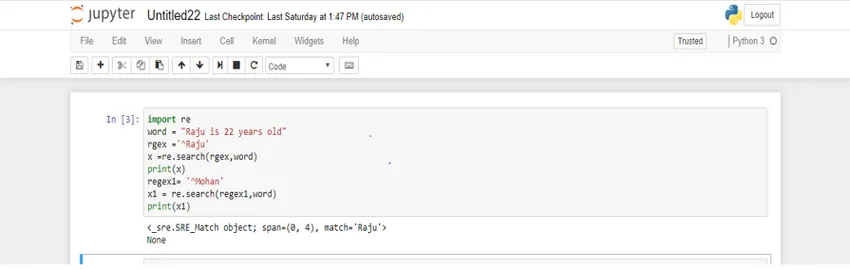
Az első esetben a mérkőzés objektumot kapjuk vissza, míg a második esetben a „Nincs” értéket kapjuk vissza.
3. Osztott () függvény: Ez a függvény minden egyes mérkőzés után felosztja a karakterláncot, ami azt jelenti, hogy amint egyezés található a karakterláncon, ez a funkció felosztja a karakterláncot onnan. Tehát, ha három mérkőzés van, akkor három osztódás lesz. Látni fogunk egy példát. Tegyük fel, hogy sztringeket akarunk szétosztani minden szóköz után. Tehát ezt a megosztott függvényt jól használhatjuk ebben a helyzetben.
Kód:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.split(rgex, word)
print(x)
Itt a minták a szóköz karaktert képviselik. Most nézzük meg a kimenetet.
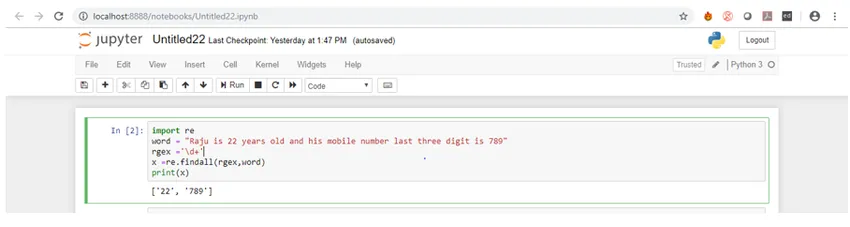
Mint látható a kimeneten, a karakterlánc minden szóköz után fel van osztva.
4. sub () függvény: Ez a funkció felváltja a találatokat a felhasználó által választott karakterlánccal vagy karakterrel. Alapvetően azt jelenti, hogy ha van egyezés a karakterláncban, akkor az egyező karaktert vagy karakterláncot helyettesíti a karakterlánccal vagy karakterrel, és visszaadja a módosított karakterláncot. Három érvre van szükség. Például a szöveg helyét csak a & & helyettesítjük a karakterláncban.
Kód:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.sub(rgex, '&', word)
print(x)
Most nézzük meg a fenti kód kimenetét.
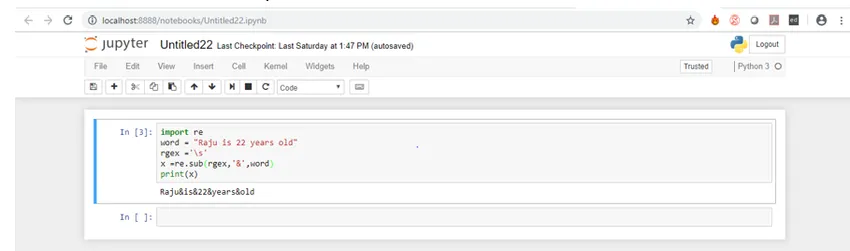
Mint láthatja, az összes szóközt „&” váltotta fel.
Következtetés
Ebben a cikkben a regex modult és annak különféle Python beépített funkcióit tárgyaltuk. A Regex nagyon fontos, és széles körben használják a különféle programozási nyelveken.
Ajánlott cikkek
Ez egy útmutató a Python Regex-hez. Itt bemutatjuk a Python Regex bevezetését és néhány fontos regex funkciót, valamint egy példát. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Amíg a hurok a Pythonban van
- Fordított szám Pythonban
- Python Kulcsszavak
- Python készletek
- PHP kulcsszavak
- C ++ Kulcsszavak