

Bevezetés a térképhez Csatlakozz a kaptárba
A térképcsatlakozás egy olyan szolgáltatás, amelyet a kaptár lekérdezéseiben használnak a hatékonyság növelése érdekében a sebesség szempontjából. A csatlakozás egy olyan feltétel, amelyet a 2 táblázat adatainak összevonására használnak. Tehát, amikor egy normál csatlakozást hajtunk végre, akkor a feladatot egy Map-Reduce feladatra küldjük, amely a fő feladatot két szakaszra osztja - “Map stage” és “Reduce stage”. A Térkép szakasz értelmezi a bemeneti adatokat és visszaadja a kimenetet a redukciós szakaszhoz kulcs-érték párok formájában. Ez a következő lépés megy keresztül a véletlen sorrendben, ahol válogatják és kombinálják. A reduktor veszi ezt a rendezett értéket és befejezi az egyesítési feladatot.
Az asztalok teljesen feltölthetők a memóriába a térképkészítőben, anélkül, hogy a Térkép / reduktor folyamatot kellene használni. Olvassa ki az adatokat a kisebb táblából, és tárolja azokat a memóriában lévő kivonat-táblában, majd soroszi azokat hash-memória fájlba, ezáltal jelentősen csökkentve az időt. Map Side Join in Hive néven is ismert. Alapvetően magában foglalja a 2 tábla közötti összekapcsolás végrehajtását, csak a Térkép fázis használatával és a Reduce fázis kihagyásával. A lekérdezések kiszámításának időbeli csökkenése figyelhető meg, ha rendszeresen használnak egy kis táblát.
Szintaxis a térképhez Csatlakozz a kaptárhoz
Ha csatlakozási lekérdezést akarunk végrehajtani térkép-csatlakozás segítségével, akkor a következő nyilatkozatban meg kell határoznunk a „/ * + MAPJOIN (b) * /” kulcsszót:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Ebben a példában létre kell hoznunk 2 táblát, amelyeknek a neve1 és 1. név, és amelyeknek két oszlopa van: emp_id és emp_name. Az egyiknek nagyobbnak kell lennie, és egynek kisebbnek kell lennie.
A lekérdezés futtatása előtt az alábbi tulajdonságot igazra kell állítanunk:
hive.auto.convert.join=true
A térképi csatlakozáshoz tartozó csatlakozási lekérdezés a fentiek szerint van írva, és az eredményt kapjuk:
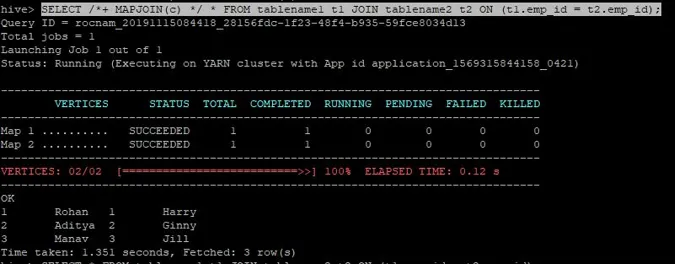
A lekérdezés 1.351 másodperc alatt fejeződött be.
Példák a Map Csatlakozz a kaptárba
Az alábbiakban említjük a következő példákat
1. Térkép csatlakozási példa
Ehhez a példához készítsünk 2 táblát, amelyeknek neve1 tábla1 és 2, 100, illetve 200 rekordokkal. Az alábbi parancsra és a képernyőképekre hivatkozhat ugyanazon végrehajtáshoz:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

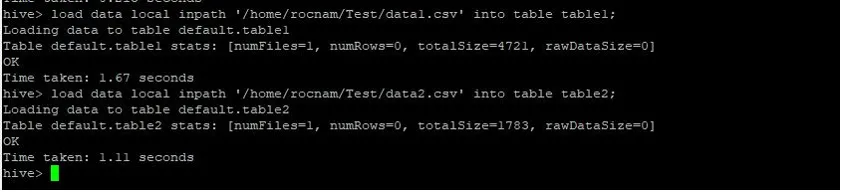
Most az alábbi parancsokkal töltjük be a rekordokat mindkét táblázatba:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Végezzünk szokásos térkép-csatlakozási lekérdezést az azonosítójukon, az alább látható módon, és ellenőrizzük az ehhez szükséges időt:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
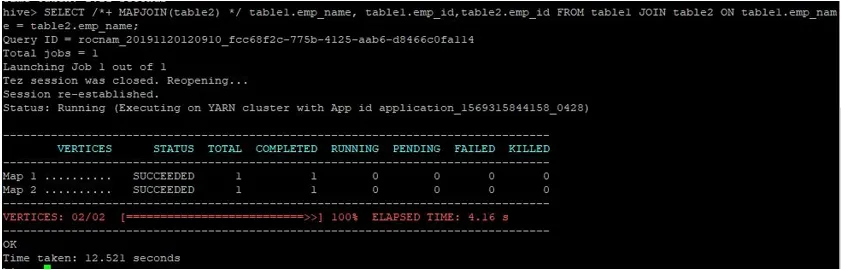
Mint láthatjuk, a normál térkép-összekapcsolási lekérdezés 12.521 másodpercet vett igénybe.
2. Vödör-térkép csatlakozási példa
Használjuk most a Bucket-map csatlakozást ugyanazon futtatáshoz. Van néhány korlátozás, amelyeket be kell tartani a vödörkészítéshez:
- A vödrök csak akkor kapcsolhatók egymáshoz, ha bármelyik asztal összes vöre többszöröse a másik táblázat vödörjeinek.
- Vödör tábláknak kell lennie a vödrözés végrehajtásához. Tehát hozzuk létre ugyanazt.
Az alábbiakban található táblázatok létrehozására használt parancsok: table1 és table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Ugyanezeket a táblázatokat az 1. táblázatból beillesztjük ezekbe a kibontott táblákba is:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
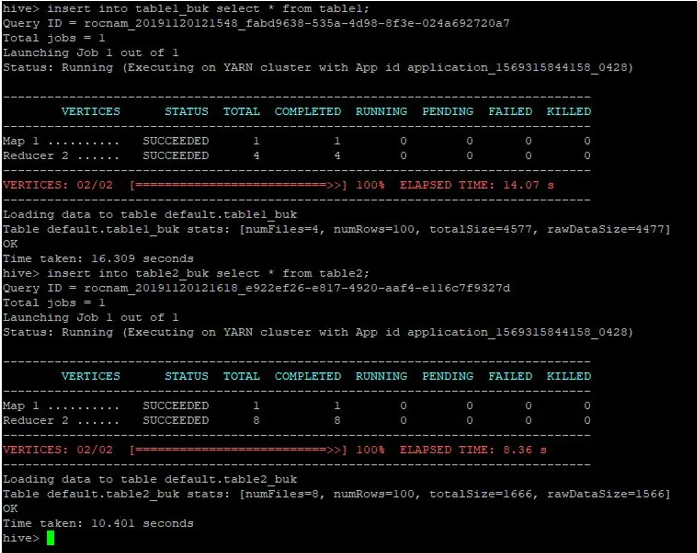
Most, hogy megvan a 2 vödör asztalunk, végezzünk vödör-térkép csatlakozást ezekre. Az első asztal 4 vödröt tartalmaz, míg a második táblázat 8 vödröt tartalmaz ugyanabban az oszlopban.
Ahhoz, hogy a vödör-térkép csatlakozási lekérdezés működjön, az alábbi tulajdonságot igaznak kell állítanunk a kaptárban:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
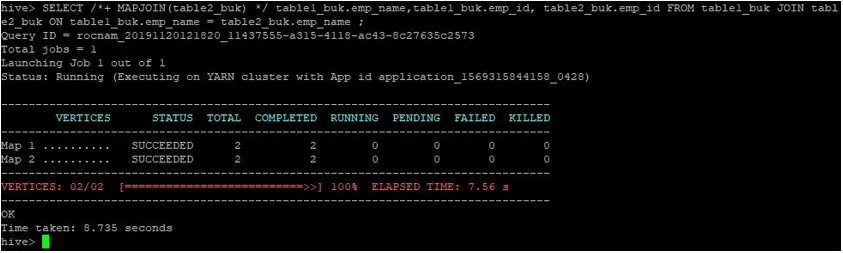
Mint látjuk, a lekérdezés 8.735 másodperc alatt fejeződött be, ami gyorsabb, mint egy normál térkép-csatlakozás.
3. Rendezés a Merge Bucket Map Csatlakozás példájához (SMB)
Az SMB végrehajtható azonos számú vödörrel ellátott, vödörített táblákon, és ha a táblákat rendezni és kibontani kell az egyesítő oszlopokon. A Mapper szint ennek megfelelően csatlakozik ezekhez a vödrökhöz.
Ugyanaz, mint a Bucket-map összekapcsolásnál, 4 vödör van az 1. táblázathoz és 8 vödör a 2. táblázathoz. Ehhez a példához egy új 4 vödör táblát készítünk.
Az SMB lekérdezés futtatásához be kell állítanunk az alábbi kaptár tulajdonságokat:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Az SMB-csatlakozás végrehajtásához az adatokat az egyesítési oszlopok szerint kell rendezni. Ezért felülírjuk az 1. táblázat adatait, az alábbiak szerint sorolva:
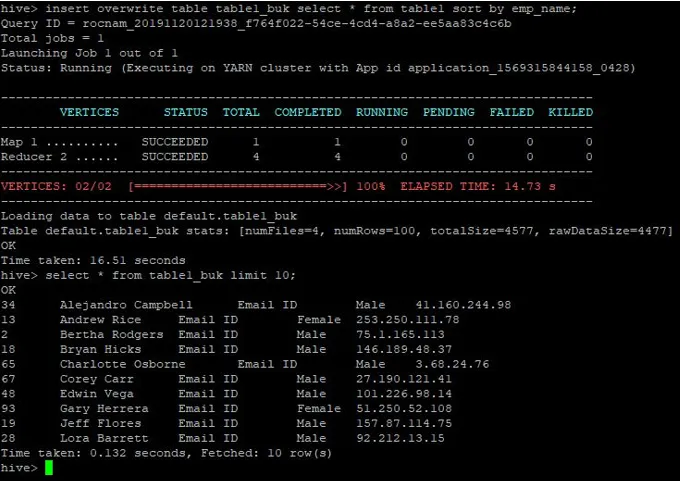
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Az adatok sorrendje megoszlik, amely az alábbi képernyőképen látható:
Az adatokat felülírjuk a kibontott 2. táblázatban is, az alábbiak szerint:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Végezzük el az összekapcsolást a fenti 2 táblázat felett az alábbiak szerint:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
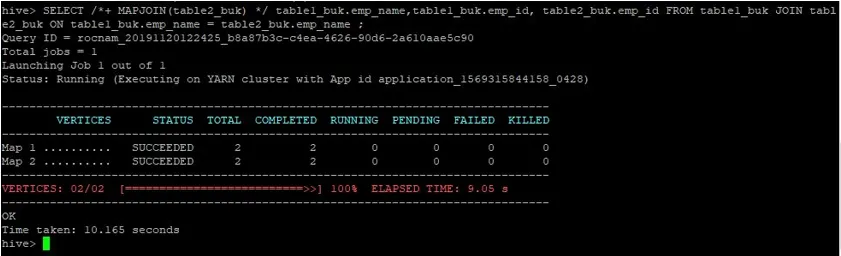
Láthatjuk, hogy a lekérdezés 10.165 másodpercet vett igénybe, ami ismét jobb, mint egy normál térképcsatlakozás.
Hozzunk létre egy új táblát a table2 számára, 4 vödörrel és ugyanazokkal az adatokkal, az emp_name név szerint rendezve.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
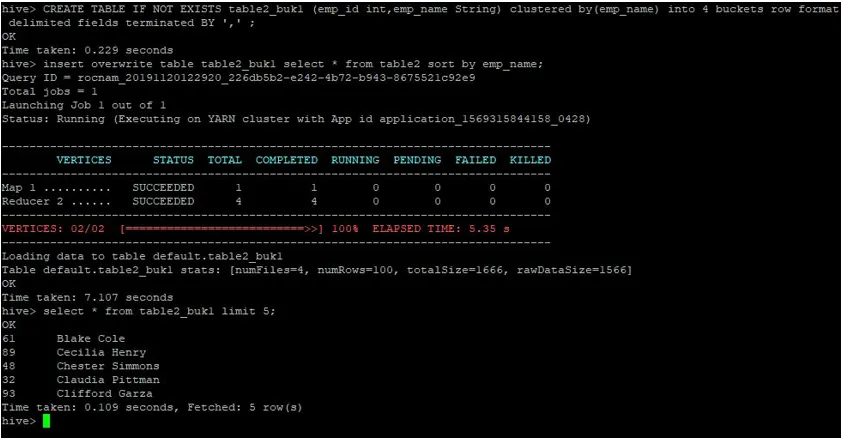
Tekintettel arra, hogy mostantól mindkét asztalunk 4 vödörrel rendelkezik, végezzük újra a csatlakozási lekérdezést.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
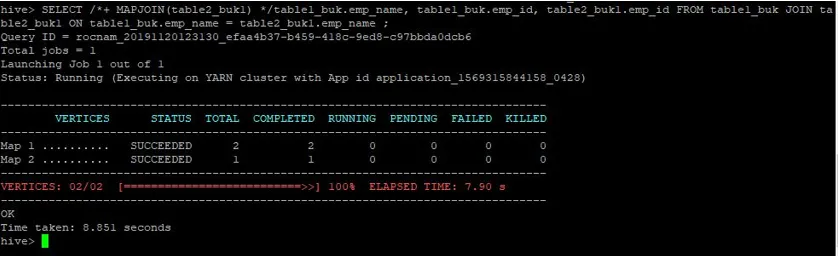
A lekérdezés ismét 8 851 másodperccel gyorsabb, mint a normál térkép-csatlakozási lekérdezés.
Előnyök
- A térképcsatlakozás csökkenti a shuffleban zajló rendezési és egyesítési folyamatokhoz szükséges időt, és csökkenti a szakaszokat, minimalizálva ezzel a költségeket is.
- Ez növeli a feladat teljesítményének hatékonyságát.
korlátozások
- Ugyanaz a tábla / álnév nem használható különféle oszlopok összekapcsolására ugyanazon lekérdezésben.
- A térképi csatlakozási lekérdezés nem képes a teljes külső illesztéseket átalakítani a térképoldali illesztésekké.
- A térképcsatlakozást csak akkor lehet végrehajtani, ha az egyik tábla elég kicsi ahhoz, hogy illeszkedjen a memóriához. Ezért nem hajtható végre, ha a táblázat adatai hatalmasak.
- A bal oldali csatlakozást csak akkor lehet elvégezni egy térképi csatlakozáshoz, ha a megfelelő táblázat mérete kicsi.
- A jobb oldali csatlakozást csak akkor lehet elvégezni egy térképi csatlakozáshoz, ha a bal oldali asztal mérete kicsi.
Következtetés
Megpróbáltuk a lehető legjobb pontokat beilleszteni a Map Join in Hive-be. Mint fentebb láttuk, a térképoldali csatlakozás akkor működik a legjobban, ha egy táblában kevesebb adat van, így a munka gyorsan befejeződik. Az itt bemutatott lekérdezésekhez szükséges idő az adatkészlet méretétől függ, ezért az itt bemutatott idő csak elemzésre szolgál. A térképi csatlakozás valósidejű alkalmazásokban egyszerűen megvalósítható, mivel hatalmas adataink vannak, így segítve a hálózat I / O forgalmának csökkentését.
Ajánlott cikkek
Ez egy útmutató a Map Csatlakozz a kaptárhoz című útmutatóba. Itt tárgyaljuk a Map Join in Hive példáit, valamint az előnyeket és korlátozásokat. A következő cikkben további információkat is megnézhet -
- Csatlakozik a kaptárba
- Kaptár beépített funkciói
- Mi a kaptár?
- Kaptárparancsok