
Bevezetés a megerősítő tanulásba
A megerősítéses tanulás egyfajta gépi tanulás, és ezért a mesterséges intelligencia részét képezi, amikor a rendszerekre alkalmazzák, a rendszerek lépéseket hajtanak végre, és a lépések kimenetele alapján tanulnak, hogy elérjék egy összetett célt, amelyet a rendszernek el kell érnie.
Ismerje meg a megerősítési tanulást
Próbáljuk meg a megerősítő tanulás keretein belül 2 egyszerű felhasználási eset segítségével:
1. eset
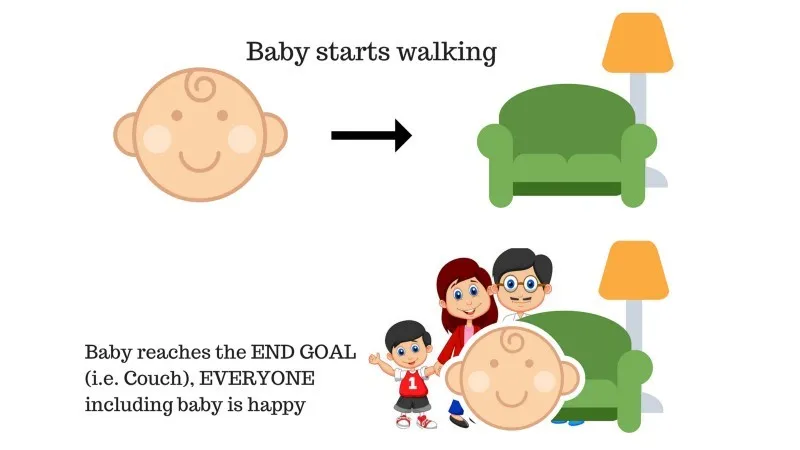
A családban van egy csecsemő, és most kezdte járni, és mindenki nagyon örül neki. Egy nap a szülők megpróbálnak egy célt kitűzni, hagyjuk, hogy a baba kinyíljon a kanapén, és megnézze, vajon képes-e a baba erre.
Az 1. eset eredménye: A csecsemő sikeresen eléri a kanapét, így a család mindenki nagyon örül ennek. A választott út most pozitív jutalommal jár.
Pontok: Jutalom + (+ n) → Pozitív jutalom.
Forrás: https://images.app.goo.gl/pGCXJ1N1bzLAer126
2. eset
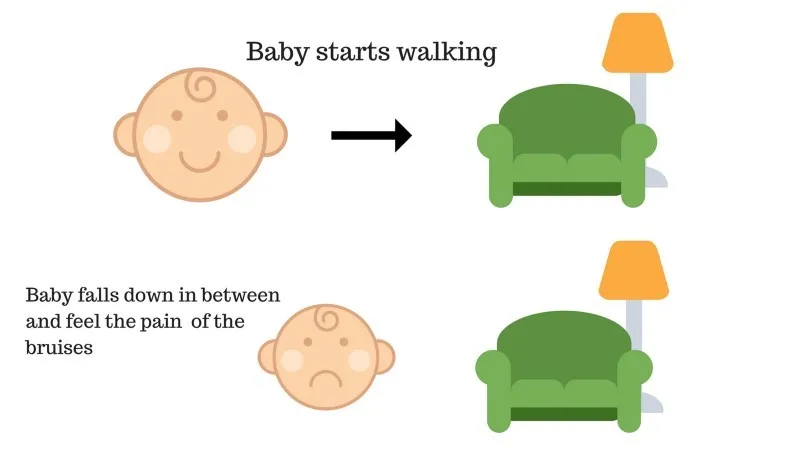
A baba nem tudta elérni a kanapét, és a baba elesett. Ez fáj! Mi lehet ennek oka? Lehet, hogy vannak akadályok a kanapé felé vezető úton, és a baba akadályokba esett.
A 2. eset eredménye: A baba néhány akadályba esik, és sír! Ó, ez rossz volt, megtanulta, hogy legközelebb ne essen akadály csapdájába. A választott út most negatív jutalommal jár.
Pontok: Jutalom + (-n) → Negatív jutalom.
Forrás: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Most már láttuk az 1. és a 2. esetet, a megerősítéses tanulás fogalmilag ugyanezt teszi, azzal a különbséggel, hogy nem emberi, hanem számítástechnikai jellegű.
A megerősítés lépésről lépésre
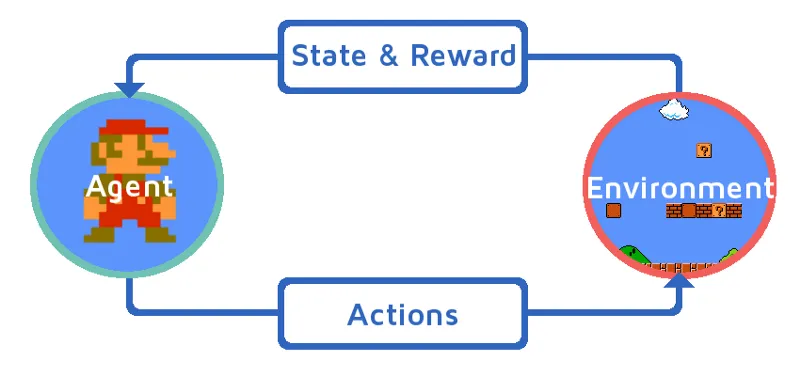
Megértjük a megerősítés tanulását azáltal, hogy lépésről lépésre hozzuk a megerősítő ágenst. Ebben a példában a megerősítő tanulási ügynökünk Mario, aki megtanulja önállóan játszani:
Forrás: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- A Mario játék környezetének jelenlegi állapota S_0. Mivel a játék még nem kezdődött el, és a Mario a helyén van.
- Ezután elindul a játék és a Mario mozog, a Mario ie RL ügynök megteszi és cselekszik, mondjuk A_0.
- A játék környezetének állapota S_1 lett.
- Ezenkívül az RL ügynöknek, azaz a Mario-nak van pozitív jutalompontja, R_1, valószínűleg azért, mert a Mario még mindig életben van, és nem volt semmilyen veszély.
A fenti hurok tovább fut, amíg a Mario végül meg nem hal, vagy a Mario el nem éri a rendeltetési helyét. Ez a modell folyamatosan adja ki a tevékenységet, a jutalmat és az állapotot.
Maximalizációs jutalmak
A megerősítéses tanulás célja a jutalom maximalizálása, figyelembe véve bizonyos egyéb tényezőket, például a jutalomkedvezményt; röviden elmagyarázzuk egy illusztráció segítségével, hogy mit jelent a kedvezmény.
A kedvezményes jutalmak halmozott képlete a következő:
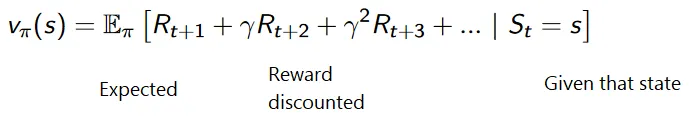
Kedvezményes jutalmak
Megértjük ezt egy példán keresztül:
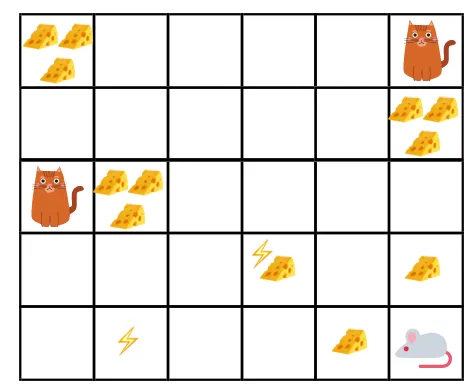
- Az adott ábrán a cél az, hogy a játékban lévő egérnek annyi sajtot kell fogyasztania, mielőtt egy macska megeszi, vagy anélkül, hogy áramütést kapna.
- Most feltételezhetjük, hogy minél közelebb vagyunk a macskához vagy az elektromos csapdához, annál nagyobb a valószínűsége, hogy az egér megeszik vagy sokkoljon.
- Ez azt jelenti, hogy még ha az elektromos sokk közelében vagy a macska közelében van a teljes sajt, minél kockázatosabb odamenni, jobb a közelben lévő sajtot enni a kockázat elkerülése érdekében.
- Tehát annak ellenére, hogy van egy „sajt1” sajt, amely tele van és messze van a macskától és az áramütés blokkjától, és a másik „blokk2”, amely szintén tele van, de vagy közel van a macskához vagy az elektromos sokkhoz, a későbbi sajtblokk, azaz a „2. blokk” jutalmakban kedvezményesebben részesülnek, mint az előző.
Forrás: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Forrás: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
A megerősítéses tanulás típusai
Az alábbiakban bemutatjuk a megerősítéses tanulás két típusát, azok előnyeivel és hátrányaival:
1. Pozitív
Amikor a viselkedés erőssége és gyakorisága növekszik egy adott viselkedés előfordulása miatt, akkor pozitív megerősítő tanulásnak nevezzük.
Előnyök: A teljesítmény maximalizált, és a változás hosszabb ideig megmarad.
Hátrányok: Az eredmények csökkenthetők, ha túl sok a megerősítés.
2. Negatív
Ez a viselkedés erősítése, elsősorban a negatív kifejezés miatt eltűnik.
Előnyök: Növekszik a viselkedés.
Hátrányok: Csak a modell minimális viselkedése érhető el negatív megerősítő tanulással.
Hol kell használni a megerősítő tanulást?
Olyan dolgok, amelyeket meg lehet erősíteni a megerősítő tanulással / példákkal. Az alábbiakban ismertetjük azokat a területeket, ahol manapság a megerősítéses tanulást alkalmazzák:
- Egészségügy
- Oktatás
- Játékok
- Számítógépes látás
- Üzleti menedzsment
- robotika
- Pénzügy
- NLP (természetes nyelv feldolgozása)
- Szállítás
- Energia
Karrier a megerősítő tanulásban
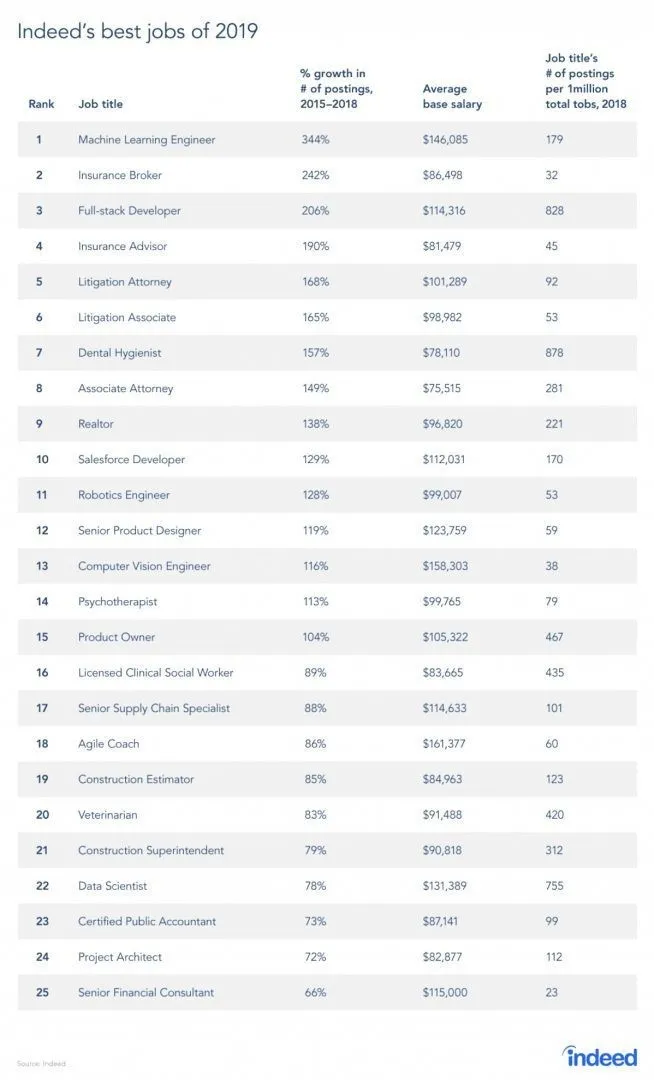
Van egy jelentés a munkahelyről, mivel az RL a gépi tanulás egyik ága, a jelentés szerint a Machine Learning a 2019. legjobb munka. Az alábbiakban a jelentés pillanatképe található. A jelenlegi trendek szerint a Machine Learning Engineers 146 085 dollár óriási átlagbérrel és 344 százalékos növekedési ütemmel jár.
Forrás: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
A megerősítéshez szükséges készségek
Az alábbiakban bemutatjuk a megerősítéshez szükséges készségeket:
1. Alapvető készségek
- Valószínűség
- Statisztika
- Adatmodellezés
2. Programozási készségek
- A programozás és a informatika alapjai
- Szoftver tervezése
- Képes a Machine Learning könyvtárak és algoritmusok alkalmazására
3. Gépi tanulás programozási nyelvei
- Piton
- R
- Bár vannak olyan nyelvek is, ahol a Machine Learning modellek megtervezhetők, mint például a Java, a C / C ++, de a Python és az R a leginkább preferált nyelvek.
Következtetés
Ebben a cikkben egy rövid bevezetéssel kezdtük a megerősítésről szóló tanulásról, majd mélyebben belemerültünk az RL működésébe és az RL modellek működésében részt vevő különféle tényezőkbe. Aztán néhány valós példát tettünk, hogy még jobban megértsük a témát. A cikk végére jól meg kell értenie a megerősítő tanulás működését.
Ajánlott cikkek
Ez egy útmutató a Mi a megerősítéses tanulás oldalról. Itt bemutatjuk a megerősítéses tanulási modellek kidolgozásának funkcióját és különféle tényezőit, példákkal. Megnézheti más kapcsolódó cikkeket is, ha többet szeretne megtudni -
- Gépi tanulási algoritmusok típusai
- Bevezetés a mesterséges intelligenciába
- Mesterséges intelligencia eszközök
- IoT platform
- A 6 legnépszerűbb gépi tanulási programozási nyelv