

Különbség a Hadoop és a Hive között
Hadoop:
A Hadoop egy olyan keretrendszer vagy szoftver, amelyet hatalmas adatok vagy nagy adatok kezelésére fejlesztettek ki. A Hadoop tárolására és feldolgozására szolgál az árupszerverek csoportjai között elosztott nagy adatok tárolása és feldolgozása.
A Hadoop az adatokat a Hadoop elosztott fájlrendszerével tárolja, és feldolgozza / lekérdezi azokat a Map Reduce programozási modell segítségével.
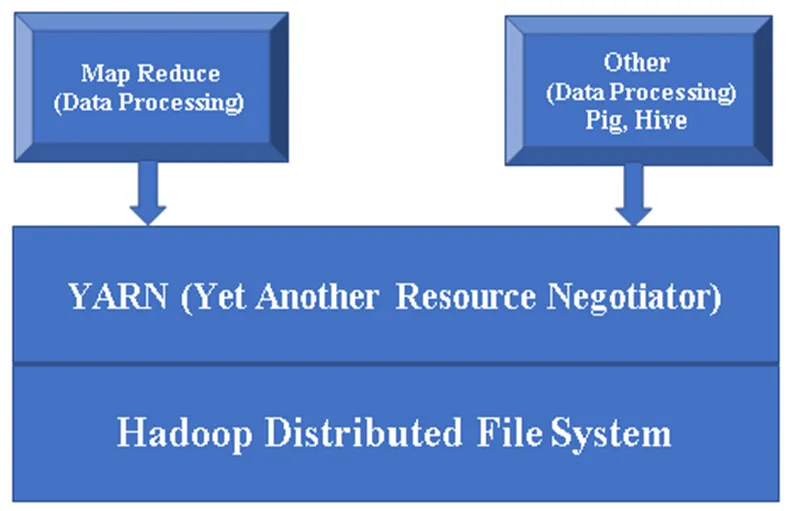
1. ábra: a Hadoop összetevő alapvető architektúrája.
Hadoop fő alkotóelemei:
Hadoop Base / Common: A Hadoop common egy platformot biztosít az összes összetevő telepítéséhez.
HDFS (Hadoop elosztott fájlrendszer): A HDFS a Hadoop keretrendszerének jelentős része, és a Hadoop Cluster összes adatáért felelős. A Master / Slave architektúrán működik, és replikációval tárolja az adatokat.
Mester / szolga architektúra és replikáció:
- Mester csomópont / név csomópont: A név csomópont a HDFS-ben tárolt minden egyes blokk / fájl metaadatait tárolja, a HDFS-nek csak egy fő csomópontja lehet (HA esetén egy másik fő csomópont másodlagos fő csomópontként fog működni).
- Szolga csomópont / Adat csomópont: Az adatcsomópontok blokkokban tartalmaznak tényleges adatfájlokat. A HDFS-nek több adatcsomópontja lehet.
- Replikáció: A HDFS az adatokat osztja blokkokra osztva. Az alapértelmezett blokkméret 64 MB. A replikáció miatt az adatok 3-ba kerülnek (alapértelmezett replikációs tényező, szükség szerint megnövelhető) különböző adatcsomópontokba, így bármilyen csomópont meghibásodása esetén az adatok elvesztésének lehetősége a legkevesebb.
Fonal (még egy erőforrás-tárgyaló): Alapvetően a Hadoop erőforrások kezelésére használják, és fontos szerepet játszik a felhasználói alkalmazások ütemezésében.
MR (Map Reduce): Ez a Hadoop alapvető programozási modellje. Az adatok feldolgozására / lekérdezésére szolgál a Hadoop keretén belül.
Kaptár:
A Hive egy olyan alkalmazás, amely a Hadoop keretén keresztül fut és SQL szerű felületet biztosít az adatok feldolgozásához / lekérdezéséhez. A Hive-t a Facebook tervezte és fejlesztette ki, mielőtt az Apache-Hadoop projekt részévé vált.
A Hive a lekérdezést a HQL (Hive query language) segítségével futtatja. A kaptár struktúrája megegyezik az RDBMS-szel, és szinte ugyanazok a parancsok használhatók a kaptárban.
A kaptár adatokat tárolhat külső táblázatokban, így nem kötelező a HDFS használata, valamint támogatja a fájlformátumokat, például ORC, Avro fájlok, szekvenciafájl és szöveges fájlok stb.
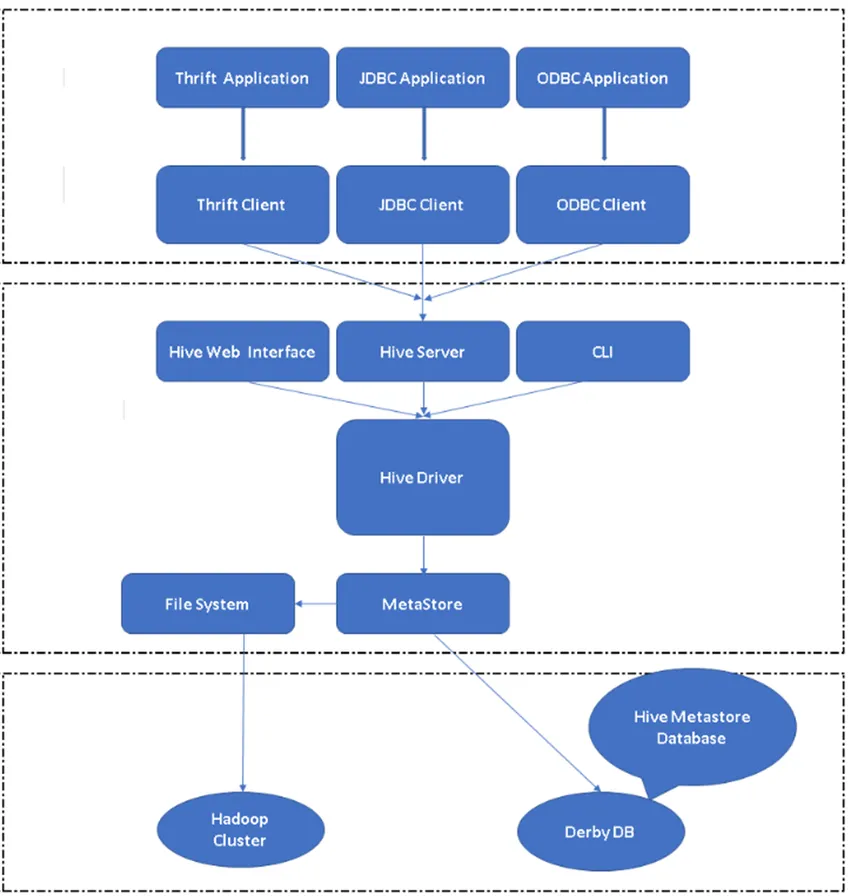
2. ábra: A kaptár felépítése és főbb elemei.
A kaptár fő alkotóeleme:
Hive Clients: A Hive nemcsak az SQL, hanem a Java, C, Python programozási nyelveket is támogatja, különféle illesztőprogramok, például ODBC, JDBC és Thrift használatával. Bármely kaptár kliens alkalmazás más nyelven is írható, és a kaptárban ezekkel az ügyfelekkel futtatható.
Kaptár szolgáltatások: A kaptár szolgáltatások alatt a parancsok és a lekérdezések végrehajtására kerül sor. A kaptár webes felületének öt alkomponense van.
- CLI: A Hive által biztosított alapértelmezett parancssori felület a Hive lekérdezéseinek / parancsainak végrehajtására.
- Hive webes felületek: Ez egy egyszerű grafikus felhasználói felület. Ez a Hive parancssor alternatívája, és a lekérdezések és parancsok futtatására szolgál a Hive alkalmazásban.
- Hive Server: Apache Thrift néven is hívják. Felelősségteljes, hogy különféle parancssori interfészektől kapja meg a parancsokat, és minden parancsot / lekérdezést a Hive elé terjesszen, és a végső eredményt is lekérdezi.
- Apache Hive Driver: Feladata a bemenetek átvétele a CLI, a webes felhasználói felület, az ODBC, JDBC vagy a Thrift interfészekből egy kliens által, és továbbítja az információkat a metastore-hoz, ahol az összes fájl információ tárolódik.
- Metastore: A Metastore egy adattár, amely az összes kaptár metaadatát tárolja. A Hive metaadatai tárolják az információkat, például a táblázatok szerkezetét, a partíciókat és az oszlop típusát stb.
Kaptár tárolása: Ez a hely, ahol a tényleges feladat végrehajtásra kerül. A kaptárból származó összes lekérdezés a kaptár tárolásán belül végrehajtotta a műveletet.
Összehasonlítás a Hadoop és a Hive között (Infographics)
Az alábbiakban a 8. legfontosabb különbség a Hadoop és a Hive között
Főbb különbségek a Hadoop és a Hive között:
Az alábbiakban felsoroljuk a pontok listáját, amelyek leírják a Hadoop és a Hive közötti főbb különbségeket:
1) A Hadoop a nagy adatok feldolgozásának / lekérdezésének kerete, míg a Hive egy SQL alapú eszköz, amely a Hadoop fölé épít az adatok feldolgozására.
2) A kaptár feldolgozása / lekérdezése az összes adatból a HQL (Hive Query Language) használatával, ez SQL-szerű nyelv, míg a Hadoop csak a Map Reduce-t érti meg.
3) A Map Reduce a Hadoop szerves része, a Hive lekérdezése először Map Reduce-ba konvertálódik, mint amelyet a Hadoop feldolgozott az adatok lekérdezéséhez.
4) A kaptár az SQL-ben működik, mint a lekérdezés, míg a Hadoop csak Java alapú Map Reduce használatával érti meg.
5) A Hive alkalmazásában a korábban használt hagyományos „Relációs adatbázis” parancsai szintén felhasználhatók a nagy adatok lekérdezésére, míg a Hadoop-ban összetett Map Reduce programokat kell írni Java-val, amely nem hasonlít a Java hagyományához.
6) A kaptár csak a strukturált adatokat képes feldolgozni / lekérdezni, míg a Hadoop az összes típusú adatnak szól, akár strukturált, akár nem strukturált, vagy félig strukturált.
7) A Hive használatával az adatok feldolgozása / lekérdezése komplex programozás nélkül történhet, miközben az Simple Hadoop ökoszisztémában ugyanazon adatokhoz összetett Java programot kell írni.
8) A Hadoop egyik oldalának 100 s-ra van szüksége a Java-alapú MR program elkészítéséhez, másik oldalán a Hadoop Hive-vel ugyanazokat az adatokat lekérdezheti 8-10 HQL sor segítségével.
9) A Hive alkalmazásban nagyon nehéz az egyik lekérdezés kimenetét beilleszteni egy másik bemenetére, míg ugyanaz a lekérdezés könnyen elvégezhető a Hadoop és az MR segítségével.
10) Nem kötelező a Metastore a Hadoop-fürtön belül, míg a Hadoop az összes metaadatát a HDFS-ben (Hadoop Distributed File System) tárolja.
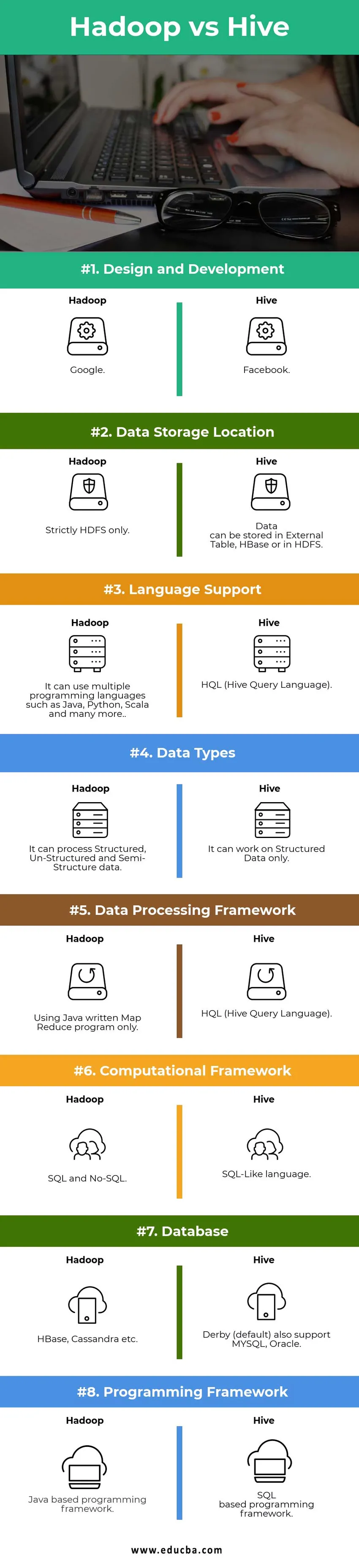
Hadoop vs kaptár összehasonlító táblázat
| Összehasonlítási pontok | Kaptár | Hadoop |
|
Tervezés és fejlesztés | ||
| Adattárolási hely |
Az adatokat a Külső tárolhatja Táblázat, HBase vagy HDFS. | Szigorúan csak HDFS. |
| Nyelvi támogatás | HQL (Hive Query Language) |
Használhat több programozási nyelvet, például Java, Python, Scala és még sok más. |
| Adattípusok | Csak strukturált adatokon működhet. |
Feldolgozza a strukturált, nem strukturált és a félszerkezeti adatokat. |
| Adatfeldolgozási keretrendszer |
HQL (Hive Query Language) | Csak a Java írásbeli Map Reduce program használatával. |
|
Számítási keret | SQL-szerű nyelv. | SQL és No-SQL. |
| adatbázis |
Derby (alapértelmezett) a MYSQL, az Oracle támogatását is támogatja … | HBase, Cassandra stb. |
| Programozási keret |
SQL alapú programozási keret. | Java alapú programozási keret. |
Következtetés - Hadoop vs Hive
A Hadoop és a Hive egyaránt felhasználják a nagy adatok feldolgozását. A Hadoop olyan keret, amely más alkalmazások számára platformot biztosít a Big Data lekérdezéséhez / feldolgozásához, míg a Hive csak egy SQL alapú alkalmazás, amely az adatokat HQL (Hive Query Language) segítségével dolgozza fel.
A Hadoop Hive nélkül használható a nagy adatok feldolgozására, míg a Hive Hadoop nélkül nem egyszerű.
Következésképpen nem hasonlíthatjuk össze a Hadoop-ot és a Hive-t semmilyen szempontból. Mind a Hadoop, mind a Hive teljesen különböznek egymástól. Mindkét technológia együttes futtatása sokkal könnyebbé és kényelmesebbé teszi a Big Data lekérdezési folyamatot a Big Data felhasználók számára.
Ajánlott cikkek:
Ez egy útmutató a Hadoop vs Hive, azok jelentésének, a fej-fej összehasonlításnak, a legfontosabb különbségeknek, az összehasonlító táblázatnak és a következtetésnek. A következő cikkeket is megnézheti további információkért -
- Hadoop vs Apache Spark - Érdekes dolgok, amelyeket tudnod kell
- HADOOP vs RDBMS | Ismerje meg a 12 hasznos különbséget
- Mennyire nagy az adatok megváltoztatása az egészségügyi ellátás arcán
- Az Apache Hive és az Apache HBase 12 legfontosabb összehasonlítása (Infographics)
- Csodálatos útmutató a Hadoop vs Spark oldalról