

Mi a Big Data és a Hadoop?
Az adatok exponenciálisan nőnek minden nap, és az ilyen növekvő adatokkal felmerül az igény az adatok felhasználására. Mint a régi időkben, hajlékonylemez-meghajtókkal is rendelkeztünk az adatok tárolására, az adatátvitel szintén lassú volt, de manapság ezek nem elégségesek, és felhőalapú tárolást használunk, mivel terabyte-os adatunk van. A mai világban a közösségi média járul hozzá a legnagyobb növekedéshez az adatok növekedésében. Ez az emberek viselkedéséből, gondolkodásmódjából és számos más aspektusból áll. Azt mondják, hogy percenként 300 órányi videót töltöttek fel a YouTube-ra, több mint 20 millió fényképet töltöttek fel a Facebookra és még sokan másokra. Ezenkívül nincs feltöltött adatok megfelelő struktúrája, amely az adatok feldolgozása során a legnagyobb kihívás.
Mivel hatalmas adatok állnak elő nagy sebességgel, a hagyományos RDBMS rendszerek nem voltak képesek kezelni ilyen gyors ütemű növekedést. Sőt, nem képesek a nem strukturált adatok kezelésére is. Nagyon nehéz lett ilyen hatalmas mennyiségű, gyorsan növekvő heterogén adat kezelése, és ezen adatok nagy feldolgozási sebességgel történő feldolgozása. Így szükség volt egy olyan rendszerre, amely képes a nagy adatkészlet hatékony kezelésére. Ezért a Hadoop forgatókönyv megoldására jött létre. A HDFS a Hadoop azon összetevője, amely elosztott tároló használatával foglalkozott a nagy adatkészlet tárolási kérdésével, míg a YARN az a komponens, amely a feldolgozási problémát kezelte, drasztikusan lecsökkentve a feldolgozási időt.
A Hadoop egy nyílt forráskódú szoftverkeret nagy adatsorok tárolására és feldolgozására, ha elosztott nagy fürtökben van az árucikk. A Doug Cutting és Michael J. Cafarella fejlesztették ki, és az Apache engedélyezte. A Java használatával készült, és a Google által a MapReduce rendszeren írt cikk alapján fejlesztették ki, és a funkcionális programozás fogalmait alkalmazza. Megbízható, gazdaságosan rugalmas és méretezhető.
A Hadoop alapvető alkotóelemei
A Hadoop fő alkotóelemei a következők
-
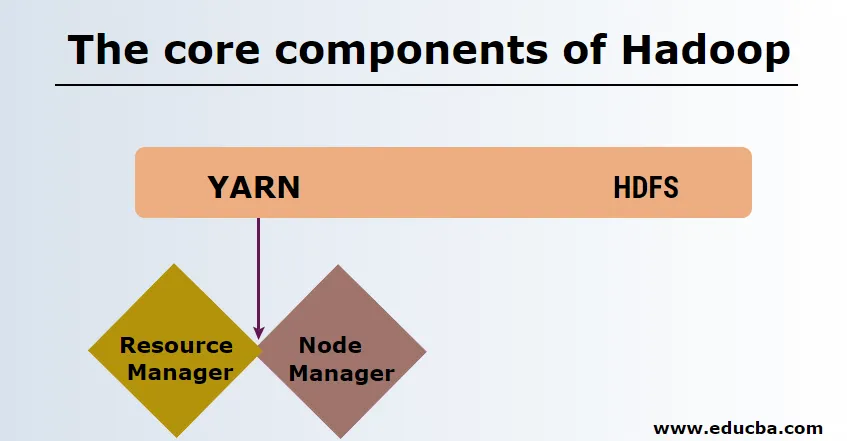
HDFS
A HDFS vagy a Hadoop Distributed File System rendelkezik Namenode és adatcsomópontokkal. A Namenode a mester démont futtató fő csomópont, amely kezeli az adatcsomópontokat és nyomon követi az összes műveletet. Datanódok azok a rabszolgák, ahol az adatokat ténylegesen tárolják.
-
YARN
A fonal két fő összetevőből áll:
1. ResourceManager: A fő csomóponton fut, és kezeli az összes erőforrást, és ütemez minden alkalmazást. Van ütemező és alkalmazásmenedzser.
2. NodeManager: Minden szolga csomóponton fut, és felelős a tárolók kezeléséért és az erőforrás-felhasználás figyeléséért.
A Hadoop számos alkotóeleme
A Hadoop-nak számos összetevője van, mint a disznó, kaptár, sqoop, flume, mahout, oozie, állatkert, HBase stb.
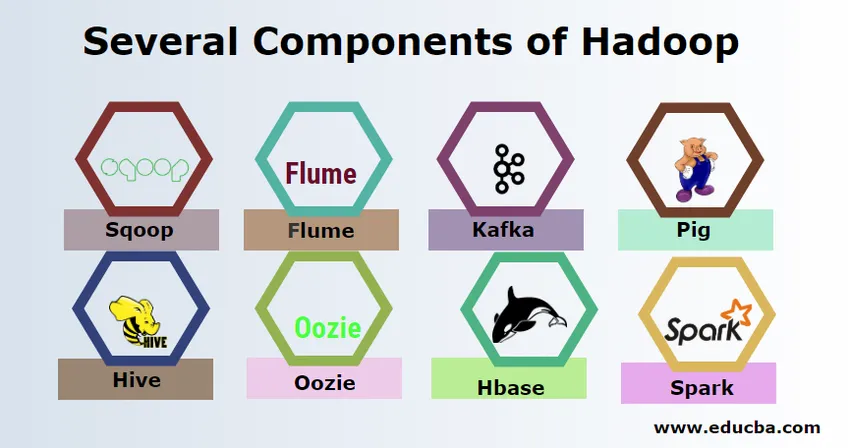
- Sqoop - Az adatok importálására és exportálására szolgál az RDBMS-ből a Hadoop-ba és fordítva.
- Flume - valós idejű adatok begyűjtésére szolgál a Hadoopba.
- Kafka - Ez egy üzenetküldő rendszer, amely valósidejű adatok továbbítására szolgál a Hadoopba.
- Pig - szkriptnyelvként használják az adatfeldolgozáshoz.
- Hive - Ez egy HDFS-re épülő adattárolási keret, amely lehetővé teszi, hogy az SQL-t ismerő felhasználók lekérdezéseket hajtsanak végre az adatok beszerzése érdekében. Ezeket a lekérdezéseket HiveQL-nek hívják.
- Oozie - A munkafolyamatok ütemezésére szolgál, hogy meghatározott eseményekre vagy időre futhassanak.
- Hbase - Ez nem az SQL adatbázis, amelyet az Apache Hadoop részeként biztosítanak.
- Spark - A memóriában történő feldolgozáshoz sokkal gyorsabb, mint a Hadoop térkép csökkentése.
Hadoop szolgáltatók
Sok cég kínál Hadoop disztribúciókat. Az alábbiakban bemutatjuk a Hadoop néhány legjobb szolgáltatóját:
- Cloudera
- Hortonworks
- MapR
Kevés előfeltétel van a Hadoop megtanulásához. Előzetes tapasztalat szükséges a Java és a szkriptnyelvek terén. Noha a Hadoop-nak már vannak saját magas szintű programozási nyelvei, például a sertés és a kaptár, amely előkészíti a háttér-kódot a további feldolgozáshoz, továbbra is létrehozhat saját térképcsökkentő programot bármilyen programozási nyelvhez, például a Ruby, Python, Perl és még a C programozáshoz.
A Bigdata és a Hadoop nagy kereslettel rendelkezik a mai piacon. Ez az elkövetkező napokban tovább növekszik. Sok szervezet már beköltözött a Hadoopba, és azok, akik még nem hamarosan költöznek. Jelenleg egy jelentés állítja, hogy a nagyvállalatok elkezdenek befektetni a nagy adatok elemzésébe. A nagy adatmarketing előrejelzés mindig növekvő tendenciát mutat, és egyáltalán nem rövid távú állapot. Mindezeken kívül a Hadoop és a big data munkák mindig magas fizetést kínálnak, mint a többi technológia.
A legnépszerűbb Big Data és Hadoop cégek
Az alábbiakban bemutatunk néhány legnépszerűbb céget, amelyek a legtöbb Hadoop erőforrást használják.
- Jehu
- amazon
- Scotland Királyi Bankja
- brit légitársaság
- Expedia
- Walmart
Nagyon sok vállalat használ nagy adatainak alkalmazását. Ezek:
-
Nokia
Cloudera és Hadoop összetevőket használ, mint például a HDFS, HBase, Sqoop, Scribe az alkalmazáshoz. A felhasználói adatokat hatékonyan felhasználta a felhasználói élmény megértésére és javítására. Adatfeldolgozást és komplex elemzéseket használ a térkép elkészítéséhez prediktív forgalom és rétegelt magassági modellek segítségével.
-
SAS
Együttműködik a Hadoop-tal, hogy segítse az adattudósokat abban, hogy jobb betekintést nyerjenek egy olyan környezet biztosítása révén, amely vizuális és interaktív élményt nyújt, ezáltal segítve az új trendek felfedezésében. Az analitikai programok értelmes betekintést nyernek az adatokból, és a memóriában lévő technológia elősegíti az adatok gyorsabb elérését.
Számos más vállalat is használ nagy adatplatformokat különféle elemzésekhez. Ezek a repülési adatok elemzése a repülőgép fekete dobozában, a részvénypiac különböző elemzése stb.
A Haddop előnyei
Az alábbiakban bemutatjuk a Hadoop néhány előnyeit
- Skálázható - ellentétben a hagyományos RDBMS-kel, ez egy nagyon skálázható platform, mivel nagy adatkészleteket képes elosztott fürtökben tárolni párhuzamosan működő árucikkek hardverén keresztül.
- Költséghatékony - Az RDBMS költsége túl magas volt az adatok tárolására, amely a Hadoopban enyhült.
- Gyors és rugalmas - az adatok gyors elérhetőségét kínálja az elosztott fájlrendszeren keresztül. Ezenkívül felajánlja, hogy üzleti betekintést nyerjen a félig strukturált és strukturálatlan adatokból.
- Hibatoleráns - Ha bármilyen adatot eljuttatunk egy csomóponthoz, ugyanazokat az adatokat másozzuk más csomópontokba is, amelyekhez az első csomópont bármilyen meghibásodása esetén lehet hozzáférni.
Következtetés - mi a Big Data és a Hadoop
Az adatok folyamatosan növekszenek, ezért mindig szükség lesz nagy adatokra és Hadoop-ra, hogy értelmezzék ezeket az adatokat. Ezért a Hadoop készségekkel rendelkező szakemberek mindig bőséges lehetőségeket találnak az elkövetkező napokban, és létfontosságú eszközt jelentenek egy szervezet számára, amely fellendíti az üzletet és karrierjét.
Ajánlott cikkek
Ez egy útmutató arról, hogy mi a Big Data és a Hadoop. Itt megvitattuk a Big Data és a Hadoop alapelveit és alkotóelemeit. A következő cikkben további információkat is megnézhet -
- Big Data Analytics példák
- A Hadoop felhasználásai
- Útmutató az adatok megjelenítéséhez
- Mi a nagy adatanalitika?