

Bevezetés a Python Pandas DataFrame-be
A Pandas Python könyvtárának több bővítése megtalálható az interneten. Az egyik ilyen a panel (pán) adatok (das). Ez a * Panel * szó finoman utal a könyvtárban lévõ 2-dimenziós adatstruktúrára, és rendkívül erõsíti a felhasználókat. Ezt a struktúrát DataFrame-nek hívják.
Ez lényegében sorok és oszlopok mátrixa, amely tartalmazza a teljes adatkészletet, nagyon bonyolult lehetőségekkel indexelve ugyanazt. A DataFrame (DF) képpel elképzelhető, nagyon hasonló az Excel laphoz. Ami azonban erőteljesvé teszi, hogy az elemző és transzformációs műveleteket egyszerűen végre lehet hajtani a DataFrame-ben tárolt adatokra.
Pontosan mi a Python Panda DataFrame?
A Pydata oldal hivatalos meghatározáshoz hivatkozhat.
Ha helyesen érti, akkor a DataFrame-t oszlopszerkezetként említi, amely képes bármilyen python-objektumot (beleértve magát a DataFrame-t is) tárolni egyetlen cellaértékként. (A cellát indexeljük egy egyedi sor- és oszlopkombinációval)
A DataFrames három alapvető összetevőből áll: adatokból, sorokból és oszlopokból.
- Adatok: A DataFrame cellájában tárolt tényleges objektumokra / entitásokra és ezeknek az entitásoknak az értékeire vonatkozik. Az objektum bármilyen érvényes python adattípus, akár beépített, akár a felhasználó által definiált.
- Sorok: A DataFrame-ben tárolt teljes adatok egy adott megfigyelési sorozatának azonosításához (vagy indexeléséhez) hivatkozásokat soroknak nevezzük. Az egyértelműség kedvéért a használt indexeket képviseli, és nem csak az adott megfigyelés adatait.
- Oszlopok: A DataFrame összes megfigyelésének halmaz attribútumainak azonosításához (vagy indexeléséhez) használt hivatkozások. Mint a sorok esetében is, ezek csak az oszlop adatainak helyett az oszlopindexre (vagy oszlopfejlécekre) utalnak.
Tehát további átélés nélkül próbáljuk ki néhány lehetőséget ezeknek a fantasztikusan erős struktúráknak a létrehozására.
Lépések a Python Panda DataFrames létrehozásához
A Python Panda DataFrame az alábbi kód implementációval hozható létre,
1. Importáljon pandákat
A DataFrames létrehozásához a pandák könyvtárat importálni kell (itt nem meglepő). Importáljuk egy álnévvel pd, hogy a modul alatt található objektumokhoz kényelmesen referencia-objektumokat hozzunk.
Kód:
import pandas as pd
2. Az első DataFrame objektum létrehozása
A könyvtár importálása után az összes módszer, funkció és konstruktor elérhető a munkaterületen. Tehát próbáljuk meg létrehozni egy vanília DataFrame-t.
Kód:
import pandas as pd
df = pd.DataFrame()
print(df)
Kimenet:
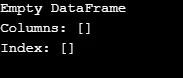
A kimeneten látható, hogy a konstruktor üres DataFrame-et ad vissza.
Most összpontosítsunk a DataFrames létrehozására az esetleges ábrázolásokban tárolt adatokból.
- DataFrame egy szótárból : Tegyük fel, hogy van egy szótár, amely tárolja a szoftveres tartományban található cégek listáját és azok aktív éveinek számát.
Kód:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Lássuk a visszaadott DataFrame objektum ábrázolását, a konzolra nyomtatva.
Kimenet:

Mint látható, a szótár minden kulcsát oszlopként kezelik a DataFrame-ben, és a sorindexeket automatikusan 0-tól kezdve generáljuk. Nagyon könnyű, mi!
Tegyük fel, hogy egyéni indexet akart adni a 0, 1, ahelyett, hogy 4. Csak át kell adnia a kívánt listát paraméterként a kivitelezőnek, és a pandák megteszik a szükséges dolgot.
Kód:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Kimenet:
Vállalati kor
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Most a sorindexeket bármilyen kívánt értékre beállíthatja.
- DataFrame egy CSV-fájlból: Hozzunk létre egy CSV-fájlt, amely ugyanazokat az adatokat tartalmazza, mint a szótárunk esetében. Hívjuk a CompanyAge.csv fájlt
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
A fájl betölthető egy adatkeretbe (feltételezve, hogy jelen van az aktuális munkakönyvtárban) az alábbiak szerint.
Kód:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Kimenet:
Vállalati kor
0 Google 21
1 Amazon 23
2 Infosys 38
3 22. irányelv
A paraméternevek beállításakor, az értékek listájának megkerülésével, oszlopfejlécként rendeli őket ugyanabban a sorrendben, ahogy a listában vannak. Hasonlóképpen a sorindexek úgy állíthatók be, hogy egy listát átadnak az index paraméternek, az előző szakaszban bemutatottak szerint. A fejléc = Nincs jelzi az adatfájl hiányzó oszlopfejléceit.
Tegyük fel, hogy az oszlopok nevei voltak az adatfájlnak. A fejléc = Hamis beállításával elvégzi a szükséges munkát.
3. CompanyAgeWithHeader.csv
Company, Age
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
A kód a következőre változik:
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Kimenet:
Vállalati kor
0 Google 21
1 Amazon 23
2 Infosys 38
3 22. irányelv
- DataFrame egy Excel fájlból: Gyakran megosztják az adatokat az Excel fájlokban, mivel továbbra is a legnépszerűbb eszköz, amelyet a közönség az Adhoc nyomon követésére használ. Tehát ezt a beszélgetésünk nem hagyhatja figyelmen kívül.
Tegyük fel, hogy az adatok megegyeznek a CompanyAgeWithHeader.csv fájljának a CompanyAgeWithHeader.xlsx fájlban, a Company Age névvel ellátott lapon. A fentiekkel azonos DataFrame-t a következő kód hoz létre.
Kód:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Kimenet:
Vállalati kor
0 Google 21
1 Amazon 23
2 Infosys 38
3 22. irányelv
Mint láthatja, ugyanaz a DataFrame létrehozható a fájlnév és a lapnév átadásával.
További olvasás és a következő lépések
A bemutatott módszerek nagyon kis részhalmazt alkotnak, összehasonlítva a DataFrames létrehozásának különféle módjaival. Ezeket azzal a szándékkal hozták létre, hogy elinduljon. Mindenképpen feltárnia kell a felsorolt hivatkozásokat, és meg kell próbálnia feltárnia más lehetőségeket is, ideértve az adatbázishoz való kapcsolódást is, hogy az adatokat közvetlenül a DataFrame-ből olvassa le.
Következtetés
A Pandas DataFrame játékváltónak bizonyult az adattudomány és az adatelemzés világában, valamint kényelmesen ad-hoc rövid távú projektekhez is. Számos olyan eszközhöz tartozik, amely rendkívül egyszerűen képes feldarabolni és kockára vágni az adatkészletet. Remélhetőleg ez lépcsőfokként szolgál majd az előző utazás során.
Ajánlott cikkek
Ez egy útmutató a Python-Pandas DataFrame-hez. Itt tárgyaljuk a python-pandák adatkeret létrehozásának lépéseit, valamint a kód megvalósítását. A következő cikkeket is megnézheti további információkért -
- A Python 15 legnépszerűbb szolgáltatása
- Különböző típusú Python készletek
- A 4 legfontosabb változótípus a Pythonban
- A Python 6 legjobb szerkesztője
- Tömbök az adatszerkezetben