
Különbség a BFS VS DFS között
A szélesség első keresés (BFS) és a mélység első keresés (DFS) két fontos algoritmus, amelyet a kereséshez használnak. A szélesség-első keresés a keresést az első csomóponttól indítja, majd az áthalad a szinteknél, amelyek közelebb vannak a gyökér csomóponthoz, míg a Mélység első keresése algoritmus az első csomóponttal kezdődik, majd befejezi az útját a megfelelő út végső csomópontjáig. Mindkét algoritmus minden csomóponton áthalad a keresés során. A két algoritmus számára különféle kódok vannak írva a bejárási folyamat végrehajtásához. Fontos keresési algoritmusoknak tekintik őket a mesterséges intelligencia területén is.
Ebben a témában megismerjük a BFS VS DFS-t.
Hogyan működik a BFS és a DFS?
Mindkét algoritmus működési mechanizmusát az alábbiakban példákkal magyarázzuk. Kérjük, forduljon hozzájuk az alkalmazott megközelítés jobb megértéséhez.
Szélesség-első keresési példa
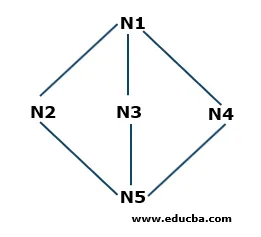
- 1. lépés: Az N1 a gyökér csomópont, tehát innen indul. Az N1 csatlakozik három N2, N3 és N4 csomóponttal. Mind a három csomópont még nincs meglátogatva. Tehát az N2-től kezdjük, és a sorban tároljuk. Tehát a Q nevű sor csak N2-t tartalmaz.
Q: N2
- 2. lépés: Ezután az N1-hez kapcsolódó csomópont N3. Mivel átmentünk vagy meglátogattuk a csomópontot, a sorban tároljuk. Tehát a frissített sor az
Q: N3, N2
- 3. lépés: Ezután a gyökércsomóponttal összekötött csomópont N4. Tároljuk a sorban.
Q: N4, N3, N2
- 4. lépés: Az N1-hez kapcsolódó összes csomópontot a sorban tárolja. Most eltávolítottuk az N2-et a sorból a First in First Out (FIFO) elv szerint, és megtaláljuk az N2-hez kapcsolódó csomópontokat, azaz N5. Az N5-öt egyszer nem látogatják meg, ezért a sorban tároljuk.
Q: N5, N4, N3
- 5. lépés: Az összes csúcs meglátogatásra kerül, tehát folyamatosan távolítjuk el a csomópontokat a sorból, amíg az üres.
Példa a mélységre
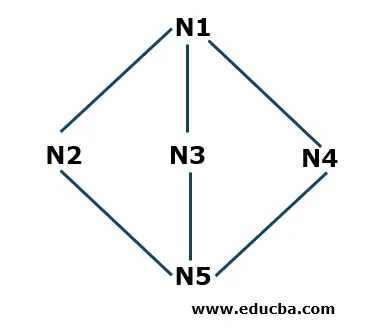
- 1. lépés: Az N1-vel kezdjük, mint a kezdő csomópontot, és tároljuk az S halomban. Az N1 három szomszédos N2, N3 és N4 csomóponttal van összekötve. Az N2-vel kezdve (betűrendben vagy numerikusan is elindíthatjuk) ezt betesszük a verembe.
S: N2 (felül), N1
- 2. lépés: Most az N2 szomszédos csomópontjai N1 és N5. Mivel az N1 már jelen van a veremben, az azt jelenti, hogy meglátogatják, ezért az N5-et elvisszük és az S halomba helyezzük.
S: N5 (felül), N2, N1
- 3. lépés: Most az N5 szomszédos csomópontjai N3 és N4. Kezdjük az N3-at és betesszük a stackbe.
S: N3 (felül), N5, N2, N1
Most az N3 csatlakozik az N5-hez és az N1-hez, amelyek már jelen vannak a veremben, vagyis meglátogatják őket, tehát az N3-ot eltávolítottuk a veremből, mint az Utolsó előbb elvben (LIFO) elv szerint.
S: N5 (felül), N2, N1
- 4. lépés: Most feltesszük az utolsó csomópontot, amellyel még nem találkoztunk az N4-ben végighaladó teljes szakaszban, és betesszük a stackbe.
S: N4 (felül), N5, N2, N1
- 5. lépés: Most nem hagyunk ki semmilyen más csomópontot, tehát ellenőrizni fogjuk a veremben, hogy vannak-e olyan csomópontok, amelyek kapcsolódnak a megfelelő csomópontokhoz, amelyek nincsenek meglátogatva. Ha az összes csatlakoztatott csomópont meglátogatásra kerül, akkor eltávolítjuk a veremben lévő csomópontokat. Például az N4-nek nincs összekötő csomópontja, amelyet nem ellenőriztünk, így eltávolítjuk a veremből. Hasonlóképpen ellenőrizhetjük más csomópontokat is. Az algoritmus leáll, ha a verem üres.
BFS VS DFS (Infographics) közötti összehasonlítás
Az alábbiakban bemutatjuk a 6 legfontosabb különbséget a BFS VS DFS között
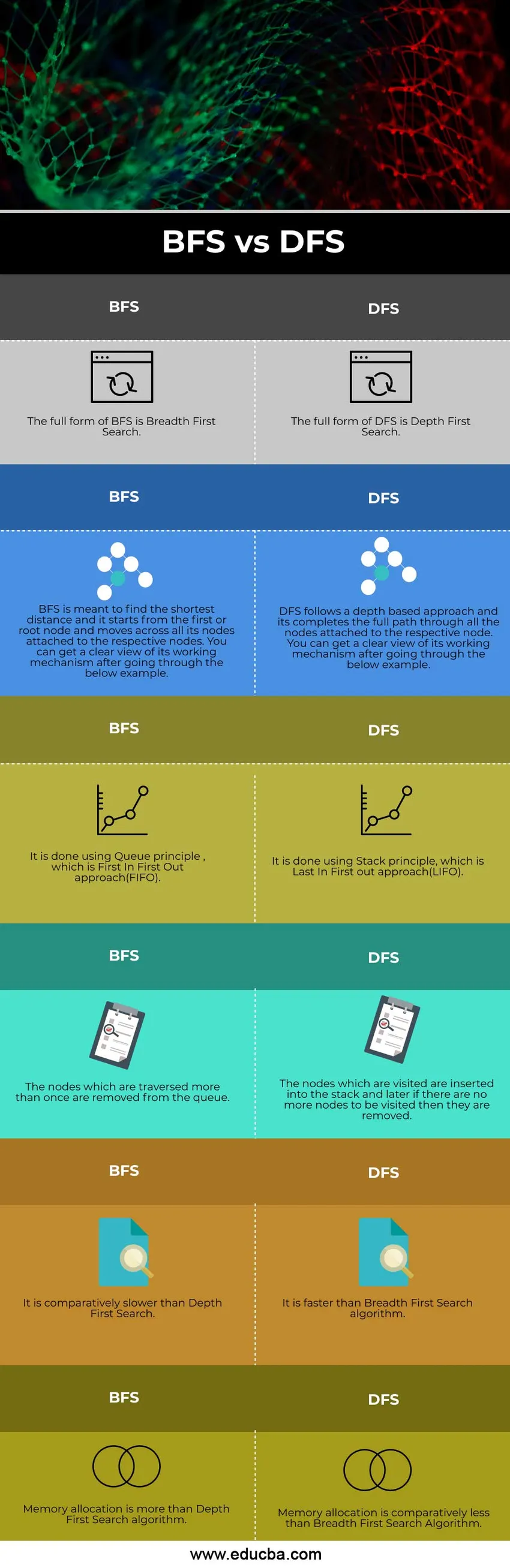
Főbb különbségek a BFS és a DFS között
Beszéljünk néhány fontosabb különbségről a BFS és a DFS között
- A szélesség-első keresés (BFS) a gyökér csomóponttól indul, és meglátogatja a hozzá kapcsolódó összes csomópontot, míg a DFS a gyökér csomóponttól indul, és befejezi a csomóponthoz csatolt teljes utat.
- A BFS a Queue megközelítését követi, míg a DFS a Stack megközelítését követi.
- A BFS-ben alkalmazott megközelítés optimális, míg a DFS-ben alkalmazott eljárás nem optimális.
- Ha célunk a legrövidebb út megtalálása, akkor a BFS-t részesítjük előnyben a DFS-nél.
BFS és DFS összehasonlító táblázat
Beszéljük meg a BFS és a DFS közötti összehasonlítást
| BFS | DFS |
| A BFS teljes formája a Breadth-First Search. | A DFS teljes formája a Depth First Search |
| A BFS célja a legrövidebb távolság keresése, és az első vagy gyökér csomóponttól indul, és az összes csomóponton áthalad, amely a megfelelő csomópontokhoz kapcsolódik. Az alábbiakban ismertetett módon világosan megismerheti annak működési mechanizmusát. | A DFS mélység-alapú megközelítést követ és teljes útvonalat készít az adott csomóponthoz csatolt összes csomóponton keresztül. Az alábbiakban ismertetett módon világosan megismerheti annak működési mechanizmusát. |
| Ezt a Queue elv alapján hajtják végre, amely az első az elsőből kiindulási megközelítés (FIFO). | Ez a Stack elv alapján történik, amely az Utolsó be az első megközelítés (LIFO). |
| A többször áthaladó csomópontokat eltávolítják a sorból. | A meglátogatott csomópontokat beillesztjük a kötegbe, majd később, ha nincs több meglátogatandó csomópont, akkor eltávolítjuk őket. |
| Ez viszonylag lassabb, mint a Mélység első keresése. | Ez gyorsabb, mint a szélesség első keresési algoritmus. |
| A memóriakiosztás több, mint a Mély első keresés algoritmus. | A memória allokációja viszonylag kevesebb, mint a szélesség első keresési algoritmusa |
Következtetés
Számos olyan alkalmazás létezik, ahol a fenti algoritmusokat gépi tanulásként vagy mesterséges intelligenciával kapcsolatos megoldások keresésére használják. Ezeket elsősorban grafikonokban használják annak megállapítására, hogy kétoldalú-e vagy sem, a kapcsolódó ciklusok vagy összetevők felismerésére. Fontos algoritmusoknak tekintik azokat is, amelyek megtalálják az utat vagy a legrövidebb távolságot. Az üzleti igényektől függően két algoritmust használhatunk. Ugyanakkor a szélesség első keresést optimális módszernek tekintik, nem pedig a Mély első keresés algoritmust.
Ajánlott cikkek
Ez egy útmutató a BFS VS DFS-hez. Itt tárgyaljuk a BFS VS DFS kulcsfontosságú különbségeit az infographics és az összehasonlító táblázat segítségével. Lehet, hogy megnézi a következő cikkeket is, ha többet szeretne megtudni -
- BFS algoritmus
- TeraData vs Oracle
- Big Data vs Data Warehouse
- Big Data vs Apache Hadoop: A 4. legjobb összehasonlítás, amelyet meg kell tanulnia