

Mély tanulási interjúkérdések és válaszok
Manapság a mély tanulást az egyik leggyorsabban növekvő technológiának tekintik, amelynek hatalmas képessége van egy olyan alkalmazás fejlesztésére, amelyet egy ideje nehéznek tartottak. A beszédfelismerés, a képfelismerés, a minták megkeresése az adatkészletben, a tárgyak osztályozása a fényképeken, a karakterszöveg generálása, az önjáró autók és még sok más csak néhány példa, ahol a Mélytanulás megmutatta jelentőségét.
Tehát végül megtalálta álmai munkáját a Deep Learning programban, de azon gondolkodik, hogyan lehet kitörni a Deep Learning Interjút, és mi lehet a valószínűleg a Deep Learning Interjú kérdése. Minden interjú különbözik, és a munkaköre is eltérő. Ezt szem előtt tartva megterveztük a leggyakoribb mélyreható tanulási interjúkérdéseket és válaszokat, amelyek segítenek az interjú sikerében.
Az alábbiakban bemutatunk néhány mélyreható tanulási interjúval kapcsolatos kérdést, amelyeket az interjú során gyakran feltesznek, és amelyek szintén segíthetnének a szint tesztelésében:
1. rész - Mély tanulási interjúkérdések (alapvető)
Ez az első rész a mély tanulással kapcsolatos interjúkérdéseket és válaszokat tartalmazza
1. Mi a mély tanulás?
Válasz:
A gépi tanulás területe, amely a mély mesterséges ideghálózatokra összpontosít, amelyeket lazán inspirál az agy. Alexey Grigorevich Ivakhnenko közzétette az első általános mélyreható tanulási hálózatot. Manapság számos területen alkalmazza, például számítógépes látás, beszédfelismerés, természetes nyelvfeldolgozás.
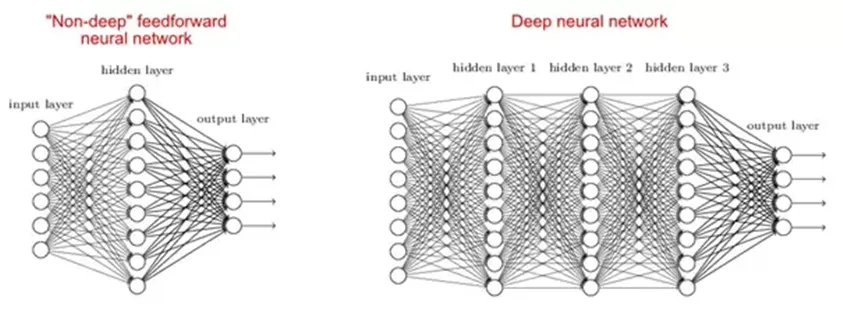
2. Miért jobb a mély hálózatok, mint a sekélyek?
Válasz:
Vannak olyan tanulmányok, amelyek szerint mind a sekély, mind a mély hálózatok bármilyen funkcióhoz illeszkedhetnek, de mivel a mély hálózatok több rejtett réteggel rendelkeznek, gyakran különféle típusúak, így képesek jobb tulajdonságok felépítésére vagy kibontására, mint a kevesebb paraméterrel rendelkező sekély modellek.
3. Mi a költségfüggvény?
Válasz:
A költségfüggvény a neurális hálózat pontosságának mérése az adott edzési mintához és a várható outputhoz viszonyítva. Ez egyetlen érték, nemvektor, mivel az egész idegi hálózat teljesítményét adja meg. Az alábbiak szerint számolható: az átlagos négyzet hibafüggvénye: -
MSE = 1nΣi = 0n (Y i-Yi) 2
Ahol Y és a kívánt Y értéket akarjuk minimalizálni.
Térjünk át a következő mélyreható tanulási interjúkérdésekhez.
4. Mi a gradiens leszállás?
Válasz:
A színátmenet leereszkedése alapvetően egy optimalizálási algoritmus, amelyet a költségfüggvényt minimalizáló paraméterek értékének megtanulására használnak. Ez egy iteratív algoritmus, amely a legszorosabb lejtés irányába halad, a gradiens negatívja által meghatározva. Kiszámoljuk egy adott paraméter költségfüggvényének gradiens csökkenését és frissítjük a paramétert az alábbi képlet alapján: -
Θ: = Θ-αd∂ΘJ (Θ)
Ahol Θ - a paramétervektor, α - a tanulási arány, J (Θ) - egy költségfüggvény.
5. Mi a hátsó szaporodás?
Válasz:
A backpropagation egy többrétegű ideghálózathoz használt képzési algoritmus. Ebben a módszerben a hibát a hálózat végétől a hálózaton belüli minden súlyba átvisszük, és ezáltal lehetővé válik a gradiens hatékony kiszámítása. Több részre osztható a következők szerint: -
A képzési adatok továbbterjesztése a kimeneti adatok előállítása érdekében.
TargetA célérték és a kimeneti érték hibaderivatívájának kiszámítása a kimenet aktiválásának függvényében lehetséges.
Ezután visszatérünk a hiba deriváltjának kiszámításához az előző kimeneti aktiválás szempontjából, és folytatjuk ezt az összes rejtett rétegre.
PreviouslyA kimenetekre és az összes rejtett rétegre korábban kiszámított derivatívákat használva kiszámítjuk a hibaderivatívákat a súlyok alapján.
És akkor frissítjük a súlyokat.
6. Magyarázza el a gradiens leszállás következő három változatát: szakaszos, sztochasztikus és mini-szakasz?
Válasz:
Sztochasztikus színátmenet-leszállás : Itt csak egy edzési példát használunk a gradiens és a frissítési paraméterek kiszámítására.
Batch Gradient Descent : Itt kiszámoljuk a gradienst a teljes adatkészlethez, és minden iterációnál végrehajtjuk a frissítést.
Mini-batch gradiens-leszállás : Ez az egyik legnépszerűbb optimalizálási algoritmus. Ez a sztochasztikus színátmenetes leszármazás egyik változata, és itt egyetlen képzési példa helyett a minták mintavételét használják.
2. rész - Mély tanulási interjúkérdések (haladó)
Vessen egy pillantást a mélyreható tanulási interjú kérdéseire.
7. Milyen előnyei vannak a mini-batch gradiens leszállásának?
Válasz:
Az alábbiakban bemutatjuk a mini-szakaszos gradiens leszállás előnyeit
• Ez sokkal hatékonyabb, mint a sztochasztikus gradiens leszállás.
• Az általánosítás a sima minimumok megkeresésével.
• A mini tételek lehetővé teszik a teljes edzéskészlet gradiensének közelítését, ami segít elkerülni a helyi minimumokat.
8. Mi az adatok normalizálása és miért van rá szükség?
Válasz:
Az adatok normalizálása a visszatérés során történik. Az adatok normalizálásának fő motivációja az adat redundancia csökkentése vagy kiküszöbölése. Itt az értékeket átméretezzük, hogy egy adott tartományba illeszkedjenek a jobb konvergencia elérése érdekében.
Térjünk át a következő mélyreható tanulási interjúkérdésekhez.
9. Mi a súlyos inicializálás az idegi hálózatokban?
Válasz:
A súly-inicializálás az egyik nagyon fontos lépés. A rossz súlyos inicializálás megakadályozhatja a hálózat tanulását, de a jó súlyos inicializálás elősegíti a gyorsabb konvergenciát és a jobb általános hibát. Az eltéréseket általában nullára lehet inicializálni. A súlyok beállításának szabálya, hogy nullához közeli legyen, anélkül, hogy túl kicsi lenne.
10. Mi az automatikus kódoló?
Válasz:
Az autoencoder egy önálló gépi tanulási algoritmus, amely a backpropagation elvét használja, ahol a célértékeket a megadott bemenetekkel egyenlőnek állítják. Belsőleg rejtett réteggel rendelkezik, amely leírja a bemenet ábrázolásához használt kódot.
Néhány kulcsfontosságú tény az autoencoderről a következő:
• Ez egy nem felügyelt ML algoritmus, amely hasonló a főkomponens elemzéshez
• Minimalizálja az objektív funkciót, mint a főkomponens-elemzés
• Neurális hálózat
• A neurális hálózat célkimenete a bemenete
11. Jó-e a 4. réteg kimenetről a 2. réteg bemenetére csatlakoztatni?
Válasz:
Igen, ez megtehető, figyelembe véve, hogy a 4. réteg kimenete az előző idő lépéséből származik, mint az RNN esetében. Azt is feltételeznünk kell, hogy az előző bemeneti köteg időnként korrelál a jelenlegi köteggel.
Térjünk át a következő mélyreható tanulási interjúkérdésekhez.
12. Mi a Boltzmann gép?
Válasz:
A Boltzmann gépet egy probléma megoldásának optimalizálására használják. A Boltzmann gép alapvetõen a súlyok és a mennyiség optimalizálása az adott problémára.
Néhány fontos szempont a Boltzmann Machine-ről -
• Ismétlődő struktúrát használ.
• Sztochasztikus neuronokból áll, amelyek a két lehetséges állapot egyikéből állnak, akár 1, akár 0.
• Az idegsejtek adaptív (szabad állapotban) vagy szorítva (fagyott állapotban vannak).
• Ha szimulált hevítést alkalmazunk diszkrét Hopfield hálózaton, akkor ez Boltzmann Machine lesz.
13. Mi az aktiváló funkció szerepe?
Válasz:
Az aktiváló függvény a nemlinearitás bevezetésére szolgál az ideghálózatban, segítve ezáltal a bonyolultabb funkciók megtanulását. E nélkül a neurális hálózat csak a lineáris függvényt képes megtanulni, amely a bemeneti adatainak lineáris kombinációja.
Ajánlott cikkek
Ez egy útmutató a mély tanulással kapcsolatos interjúkérdések és válaszok listájához, így a jelölt könnyen meg tudja oldani ezeket a mély tanulási interjú kérdéseit. A következő cikkeket is megnézheti további információkért
- Ismerje meg a 10 leghasznosabb HBase interjúkérdést
- Hasznos gépi tanulási interjúkérdések és válaszok
- Az öt legértékesebb adattudományi interjú kérdése
- Fontos Ruby interjúkérdések és válaszok