

Bevezetés az adatbányászatba
Ez egy olyan adatbányászati módszer, amelyet az adatelemek hasonló csoportokba helyezéséhez használnak. A klaszter az adatobjektumok alosztályokra osztása. A klaszterezés minősége attól a módszertől függ, amelyet használunk. A klaszterezést adatszegmentációnak is nevezzük, mivel a nagy adatcsoportokat felosztjuk hasonlóságuk szerint.
Mi az klaszterezés az adatbányászatban?
A klaszterezés egy adott objektum csoportosítása jellemzõik és hasonlóságuk alapján. Ami az adatbányászatot illeti, ez a módszer egy speciális összekapcsolási algoritmussal osztja el azokat az adatokat, amelyek a legmegfelelőbbek a kívánt elemzéshez. Ez az elemzés lehetővé teszi, hogy egy objektum ne legyen része vagy szigorúan nem része a klaszternek, amelyet ezt a fajta kemény particionálást hívnak. A sima partíciók azonban azt sugallják, hogy minden objektum azonos mértékben tartozik klaszterbe. Specifikusabb megosztásokat hozhatunk létre, mint például több klaszter objektumai, egyetlen klaszter is kényszeríthető a részvételre, vagy akár hierarchikus fákat lehet létrehozni a csoportkapcsolatokban. Ezt a fájlrendszert különféle módokon lehet elhelyezni, különféle modellek alapján. Ezek a különálló algoritmusok mindegyik modellre vonatkoznak, megkülönböztetve tulajdonságaikat és eredményeiket. Egy jó klaszterezési algoritmus képes a klaszter azonosítására a klaszter alakjától függetlenül. A klaszterezési algoritmus három alapvető stádiuma van, amelyeket az alábbiakban mutatunk be
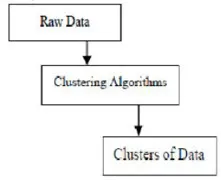
Klaszterezési algoritmusok az adatbányászatban
A nemrégiben ismertetett fürtmodellektől függően számos klaszter felhasználható az adatok adatsorba történő particionálására. Azt kell mondani, hogy minden módszernek megvannak a maga előnyei és hátrányai. Az algoritmus kiválasztása az adatkészlet tulajdonságaitól és jellegétől függ.
Az adatbányászat klaszterezési módszerei az alábbiak szerint mutathatók be
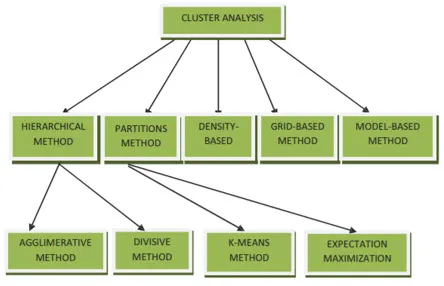
- Partícionálás alapú módszer
- Sűrűség-alapú módszer
- Centroid-alapú módszer
- Hierarchikus módszer
- Rács alapú módszer
- Modell alapú módszer
1. Partíciós módszer
A partíciós algoritmus az adatokat sok részhalmazra osztja.
Tegyük fel, hogy a particionáló algoritmus az adatok partícióját építi fel, mivel k és n objektumok vannak jelen az adatbázisban. Ezért minden partíciót k ≤ n-ként ábrázolunk.
Ez azt az elképzelést adja, hogy az adatok k csoportba sorolhatók, amint az alább látható
Az 1. ábra az eredeti pontokat mutatja a csoportosulásban

A 2. ábra a partíciós csoportosítást mutatja egy algoritmus alkalmazása után
Ez azt jelzi, hogy minden csoportnak legalább egy objektuma van, valamint minden objektumnak pontosan egy csoporthoz kell tartoznia.
2. Sűrűség alapú módszer
Ezek az algoritmusok az adatkészletben résztvevők nagy sűrűsége alapján meghatározott helyen létrehoznak klasztereket. Összevonja a csoporttagok némi tartomány-fogalmát a klaszterekben a sűrűség standard szintjére. Az ilyen folyamatok kevésbé teljesítenek a csoport felületének felismerésében.
3. Centroid-alapú módszer
Szinte minden klaszterre egy értékvektor hivatkozik az ilyen típusú os csoportosítási technikában. A többi klaszterhez képest minden objektum a klaszter része, minimális értékkülönbséggel. A klaszterek számát előre meg kell határozni, és ez az ilyen típusú legnagyobb algoritmusprobléma. Ez a módszer a legközelebb az azonosítás tárgyához, és széles körben használják az optimalizálási problémákra.
4. Hierarchikus módszer
A módszer hierarchikus bontást hoz létre egy adott adatobjektum-halmazra. A hierarchikus bontás kialakulásának alapján osztályozhatjuk a hierarchikus módszereket. Ezt a módszert a következőképpen adjuk meg
- Agglomerációs megközelítés
- Megosztó megközelítés
Az agglomerációs megközelítést Button-Up megközelítésnek is nevezik. Itt kezdjük minden objektummal, amely külön csoportot alkot. Folytatja az objektumok vagy csoportok egymáshoz közeli összeolvadását
A megosztó megközelítés top-down megközelítésként is ismert. Az összes objektumot ugyanabban a fürtben kezdjük. Ez a módszer merev, azaz soha nem vonható le a fúzió vagy az osztás befejezése után
5. Rács-alapú módszer
A rács alapú módszerek az objektumtérben működnek, ahelyett, hogy az adatokat rácsra osztanák. A rácsot az adatok jellemzői alapján osztják fel. E módszer alkalmazásával a nem numerikus adatokat könnyű kezelni. Az adatsorrend nem befolyásolja a rács particionálását. A rács alapú modell fontos előnye, hogy gyorsabb végrehajtási sebességet biztosít.
A hierarchikus csoportosítás előnyei a következők
- Bármely attribútumtípusra alkalmazható.
- Rugalmasságot biztosít a részletesség szintjéhez viszonyítva.
6. Modell alapú módszer
Ez a módszer egy feltételezett modellt alkalmaz a valószínűség-eloszláson alapul. A sűrűségfüggvény csoportosításával ez a módszer megkeresi a klasztereket. Ez tükrözi az adatpontok térbeli eloszlását.
A klaszterezés alkalmazása az adatbányászatban
A klaszterezés számos területen segíthet, például a biológiában, a növényekben és az állatok tulajdonságaik szerint besorolt állatokban, valamint a marketingben is. A klaszterezés segít azonosítani egy bizonyos ügyfél-nyilvántartásba tartozó ügyfelek azonos viselkedését. Számos alkalmazásban, például a piackutatásban, a mintafelismerésben, az adatokban és a képfeldolgozásban a klaszterelemzést nagyszámban használják. A klaszterezés elősegítheti az ügyfélkörben lévő hirdetőket, hogy megtalálják a különböző csoportokat. És ügyfélcsoportjaikat vásárlási mintákkal lehet meghatározni. A biológiában növényi és állati taxonómiák meghatározására, hasonló funkcionalitású gének kategorizálására és a populációval összefüggő struktúrák betekintésére használják. A földmegfigyelési adatbázisban a csoportosulás megkönnyíti a hasonló felhasználású területek megtalálását a földön. Segít meghatározni a házak és apartmanok csoportjait a ház típusa, értéke és rendeltetése szerint. A dokumentumok internetes csoportosítása szintén hasznos az információk felfedezéséhez. A klaszteranalízis eszköze betekintést nyer az adatok eloszlásába, hogy megfigyelhető legyen az egyes klaszterek, mint adatbányászati funkció.
Következtetés
A klaszterezés fontos az adatbányászatban és annak elemzésében. Ebben a cikkben láttuk, hogy a klaszterezés hogyan végezhető különféle klaszterezési algoritmusok alkalmazásával, valamint a valós életben történő alkalmazásával.
Ajánlott cikk
Ez egy útmutató a Mi a klaszterezés az adatbányászatban című részben található. Itt megbeszéljük a klaszterezés fogalmait, meghatározásait, jellemzőit, alkalmazását az adatbányászatban. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Mi az adatfeldolgozás?
- Hogyan válhatunk elemzőnek?
- Mi az SQL befecskendezés?
- Mi az SQL Server meghatározása?
- Az adatbányászati architektúra áttekintése
- Fürtözés a gépi tanulásban
- Hierarchikus klaszterezési algoritmus
- Hierarchikus csoportosítás | Agglomerációs és megosztó csoportosulás