

Bevezetés az adatbányászati módszerekbe
Az adatok óriási mértékben nőnek minden nap. De az összes összegyűjtött vagy összegyűjtött adat nem hasznos. Az értelmes adatokat el kell választani a zajos adatoktól (értelmetlen adatok). Ezt az elválasztási folyamatot adatbányászat valósítja meg.
Mi az adatbányászat?
Az adatbányászat egy hasznos információk vagy ismeretek kinyerésének folyamata hatalmas mennyiségű adatból (vagy nagy adatból). Az adatok és az információ közötti különbséget különféle adatbányászati eszközökkel csökkentik. Az adatbányászatot tudásmegállapítás adatból vagy KDD-ből is fel lehet hívni .
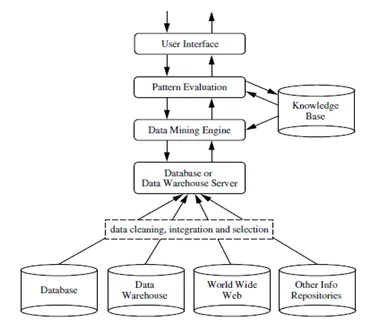
Források: - www.ques10.com
Az adatbányászat különféle típusú adatbázisokon és információtárakban végezhető, mint például relációs adatbázisok, adattárházak, tranzakciós adatbázisok, adatfolyamok és még sok más.
Különböző adatbányászati módszerek:
Az Adatbányászatban sok módszert használnak, de a döntő lépés az, hogy kiválasztjuk a megfelelő módszert az üzleti vagy a problémameghatározás szerint. Ezek az adatbányászati módszerek segítenek a jövő előrejelzésében, majd a megfelelő döntések meghozatalában. Ezek a piaci tendenciák elemzésében és a vállalati bevételek növelésében is segítenek.
Néhány adatbányászati módszer:
- Egyesület
- Osztályozás
- Klaszterelemzés
- jóslás
- Szekvenciális minták vagy mintakövetés
- Döntési fák
- Külső elemzés vagy anomáliaelemzés
- Neurális hálózat
Megértjük minden egyes adatbányászati módszert egyenként.
1. Egyesület:
Ez egy olyan módszer, amelynek segítségével két vagy több elem között összefüggést lehet találni az adathalmaz rejtett mintájának azonosításával, és ezért relációs elemzésnek is hívják . Ezt a módszert használják a piackosár elemzésben az ügyfél viselkedésének előrejelzésére.
Tegyük fel, hogy egy szupermarket marketingmenedzsere meg akarja határozni, mely termékeket vásárolják gyakran együtt.
Mint például,
Vásárlás (x, „sör”) -> vásárlás (x, „sör”) (támogatás = 1%, konfidencia = 50%)
- Itt x azt a vevőt képviseli, aki együtt vásárol sört és chipset.
- A bizalom azt bizonyítja, hogy ha egy ügyfél sört vásárol, akkor 50% esély van arra, hogy a chipet is vásárolja.
- A támogatás azt jelenti, hogy az összes elemzett tranzakció 1% -a azt mutatta, hogy a sört és a chipset együtt vásárolták.
Sok hasonló példát, például kenyeret és vajat, vagy számítógépet és szoftvert lehet figyelembe venni.
Kétféle társulási szabály létezik:
- Egydimenziós asszociációs szabály: Ezek a szabályok egyetlen attribútumot tartalmaznak, amelyet megismételnek.
- Többdimenziós asszociációs szabály: Ezek a szabályok több ismétlődő attribútumot tartalmaznak.
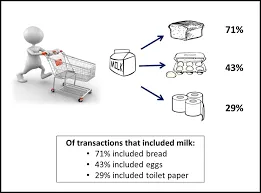
https://bit.ly/2N61gzR
2. Besorolás:
Ez az adatbányászati módszer az adatkészletek tételeinek osztályokra vagy csoportokra történő megkülönböztetésére szolgál. Segít pontosan megjósolni az elemek viselkedését a csoporton belül. Ez egy kétlépéses folyamat:
- Tanulási lépés (edzési szakasz): Ebben az esetben egy osztályozási algoritmus felépíti az osztályozót egy edzéskészlet elemzésével.
- Osztályozási lépés: A tesztelési adatok felhasználják a besorolási szabályok pontosságának vagy pontosságának becslésére.
Például egy bankvállalat alacsony, közepes vagy magas hitelkockázat mellett azonosítja a hitelkérelmezőket. Hasonlóképpen, egy orvos kutatja a rákkal kapcsolatos adatokat, hogy megjósolja, mely gyógyszert írjon fel a beteg számára.
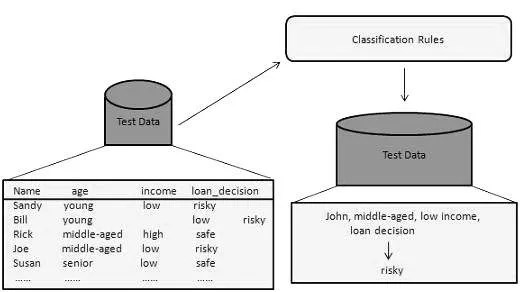
Források: - www.tutorialspoint.com
3. Klaszterelemzés:
A klaszterezés szinte hasonló a besoroláshoz, de ebben a klaszterben az adatelemek hasonlóságaitól függően készülnek. A különböző klaszterek eltérő vagy független tárgyakkal rendelkeznek. Adat szegmentálásnak is nevezik, mivel a hatalmas adatkészleteket a hasonlóságok alapján klaszterekre osztja.
Különböző fürtözési módszereket használnak:
- Hierarchikus agglomerációs módszerek
- Rács alapú módszerek
- Osztási módszerek
- Modell alapú módszerek
- Sűrűség alapú módszerek
A hitelkérelmezők hasonló példáját itt is figyelembe lehet venni. Van néhány különbség, amelyeket az alábbi ábra szemléltet.
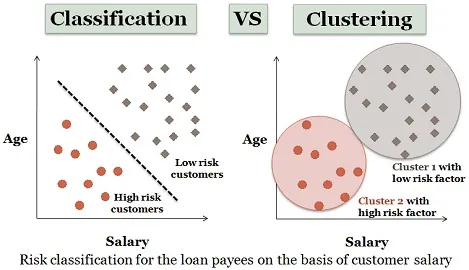
https://bit.ly/2N6aZpP
4. Jóslás:
Ez a módszer a jövő előrejelzésére szolgál a múlt és jelen tendenciák vagy adatkészlet alapján. Az előrejelzést leginkább más adatbányászati módszerek kombinációjával használják, mint például osztályozás, mintázat-illesztés, trend-elemzés és reláció.
Például, ha egy szupermarket értékesítési igazgatója szeretne előre jelezni a bevétel összegét, amelyet az egyes elemek generálnának a múltbeli értékesítési adatok alapján. Folyamatosan értékelt funkciót modellez, amely előre jelzi a hiányzó numerikus adatértékeket.

Források: - data-mining.philippe-fournier
A regressziós elemzés a legjobb választás az előrejelzés végrehajtására. Használható kapcsolat létrehozására a független és függő változók között.
5. Szekvenciális minták vagy mintázatkövetés:
Ezt az adatbányászati módszert használják azon minták azonosítására, amelyek egy adott időszakon belül gyakran előfordulnak.
Például a ruházati társaság értékesítési vezetője úgy látja, hogy a dzsekik eladása látszólag növekszik közvetlenül a téli szezon előtt, vagy karácsonykor vagy újévkor nő a pékség értékesítése.
Nézzünk egy példát egy grafikon segítségével
Források: - data-mining.philippe-fournier-viger
6.Döntési fák:
A döntési fa egy faszerkezet (amint a neve is sugallja), ahol
- Minden belső csomópont az attribútum tesztjét képviseli.
- Az ág a teszt eredményét jelöli.
- A terminálcsomópontok megkapták az osztálycímkét.
- A legfelső csomópont a gyökér csomópont, amelynek egyszerű kérdése van, amely két vagy több választ tartalmaz. Ennek megfelelően a fa növekszik, és folyamatábrához hasonló struktúra jön létre.
Források: - www.tutorialride.com
Ebben a döntésben a fa kormány a 18 év alatti vagy 18 év feletti polgárokat sorolja be. Ez segítené őket abban, hogy eldöntsék, engedélyt kell-e kiadni egy adott polgár számára.
7.Külső elemzés vagy anomáliaelemzés:
Ezt az adatbányászati módszert azoknak az adatelemeknek az azonosításához használják, amelyek nem felelnek meg a várt mintának vagy a várt viselkedésnek. Ezeket a váratlan adatelemeket kiugrónak vagy zajnak tekintik. Sok területen hasznosak, mint például a hitelkártya-csalások észlelése, behatolás-észlelés, hibadetektálás stb. Ezt nevezik Outlier Mining-nek is .
Tegyük fel például, hogy az alábbi grafikon ábrázolása az adatbázisunkban található egyes adatkészletek felhasználásával történik.
Tehát a legmegfelelőbb vonal húzódik. A vonal közelében fekvő pontok várható viselkedést mutatnak, míg a vonaltól távol eső pont egy külső.
Ez elősegítené a rendellenességek felismerését és a lehetséges intézkedések ennek megfelelő végrehajtását.
https://bit.ly/2GrgjDP
8. Neurális hálózat:
Ez az adatbányászati módszer vagy modell biológiai ideghálókon alapul. Ez egy olyan neuronok gyűjteménye, mint a feldolgozó egységek, súlyozott kapcsolatok között. Ezeket a bemenetek és a kimenetek kapcsolatának modellezésére használják. Besorolásra, regressziós elemzésre, adatfeldolgozásra stb. Használják. Ez a technika három pilléren működik -
- Modell
- Tanulási algoritmus (felügyelt vagy felügyelet nélkül)
- Aktiválási funkció
Források: - www.saedsayad.com
Ajánlott cikkek
Ez egy útmutató az Adatbányászási módszerekhez. Itt példával tárgyaltuk a Mi az Adatbányászat és az Adatbányászati módszerek különféle típusait. A következő cikkeket is megnézheti további információkért -
- Big Data Analytics szoftver
- Az adatszerkezet interjúval kapcsolatos kérdései
- Fontos adatbányászati technikák
- Adatbányászati architektúra