

Bevezetés a sertésparancsokba
Az Apache Pig egy eszköz / platform, amelyet nagy adatkészletek elemzésére és hosszú adatsorozatok végrehajtására használnak. A sertést a Hadoopmal együtt használják. Az összes sertés szkriptet belsőleg átalakítják térképcsökkentő feladatokká, majd végrehajtják őket. Kezelheti a strukturált, félig strukturált és nem strukturált adatokat. Sertésboltok, eredménye HDFS-be. Ebben a cikkben megismerjük a sertésparancsok több típusát.
Íme néhány sertésjellemző:
- Önoptimalizálás: A sertés optimalizálhatja a végrehajtási feladatokat, a felhasználó szabadon koncentrálhat a szemantikára.
- Könnyű programozni: A Pig magas szintű nyelvet / nyelvjárást biztosít, a Pig Latin néven, amely könnyen írható. A Pig Latin számos operátort kínál, amelyet a programozó felhasználhat az adatok feldolgozására. A programozó rugalmasan írja meg saját funkcióit is.
- Meghosszabbítható: A Pig megkönnyíti az egyéni funkció létrehozását, amelyet UDF-nek (Felhasználó által definiált függvény) hívnak, amely lehetővé teszi a programozók számára, hogy bármilyen feldolgozási igényt gyorsan és egyszerűen teljesítsenek. A disznó szkript egy héjon fut, amelyet grundnak hívnak.
Miért sertésparancsok?
Azok a programozók, akik nem jók a Java-val, általában küzdenek a programok írásával a Hadoopban, azaz térkép-csökkentési feladatokat írnak. Számukra áldás az, hogy a Pig Latin, amely nagyon hasonlít az SQL nyelvre. Több lekérdezéses megközelítése csökkenti a kód hosszát.
Tehát általánosságban a tömör és hatékony programozási módja. A Pig Commands számos nyelven hívhat fel kódot, például JRuby, Jython és Java.
A sertésparancsok építészete
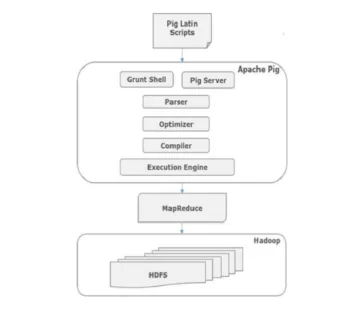
Minden, a disznó-latinul írt szkript grunt shell-en keresztül az elemzőhöz kerül a szintaxis ellenőrzésére, és más különféle ellenőrzések is történnek. Az elemző kimenete DAG. Ez a DAG ezután továbbadódik az Optimizernek, amely logikai optimalizálást hajt végre, például vetítést, és lenyomja. Ezután a fordító eleget tesz a MapReduce feladatok logikai tervének. Végül ezeket a MapReduce-feladatokat rendezett sorrendben küldik el a Hadoop-nak. Ezek a feladatok végrehajtásra kerülnek, és a kívánt eredményeket eredményezik.
A disznó-latin adatmodell teljesen beágyazott, és lehetővé teszi olyan összetett adattípusokat, mint a térkép és a tuple.
A sertés latin nyelv bármely értékét (az adattípustól függetlenül) atomnak nevezzük.
Alapvető sertésparancsok
Vessen egy pillantást néhány, az alábbi Pig parancsra:
1. Fs: Itt felsorolja az összes fájlt a HDFS-ben
morgás> fs –ls
2. Törlés: Ez törli az interaktív Grunt-héjat.
morgás> tiszta
3. Előzmények:
Ez a parancs az eddig végrehajtott parancsokat mutatja.
morgás> történelem
4. Adatok olvasása: Feltételezve, hogy az adatok HDFS-ben vannak, és el kell olvasnunk az adatokat a Pig-nak.
grunt> főiskolai hallgatók = betöltés 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
A PigStorage (', ') HASZNÁLATA
as (id: int, utónév: chararray, vezetéknév: chararray, telefon: chararray,
város: chararray);
A PigStorage () az a funkció, amely strukturált szövegfájlokként tölti be és tárolja az adatokat.
5. Adatok tárolása: A tároló operátorja használt a feldolgozott / betöltött adatok tárolására.
grunt> STORE college_students into 'hdfs: // localhost: 9000 / pig_Output /' PigStorage (', ') HASZNÁLATA;
Itt a “/ pig_Output /” a könyvtár, ahol a relációt tárolni kell.
6. Dump Operator: Ez a parancs az eredmények képernyőn történő megjelenítésére szolgál. Ez általában segít a hibakeresésben.
grunt> Dump college_students;
7. Leírja az operátort: Segít a programozónak a reláció sémájának megtekintésében.
grunt> írja le a főiskolai hallgatókat;
8. Magyarázza: Ez a parancs segít a logikai, a fizikai és a térképet csökkentő végrehajtási tervek áttekintésében.
morgás> magyarázza a főiskolai hallgatókat;
9. Operátor szemléltetése: Ez megadja a Pig parancsok utasításai lépésről lépésre történő végrehajtását.
grunt> illusztrálja a főiskolai hallgatókat;
Köztes sertésparancsok
1. Csoport: Ez a Pig parancs arra irányul, hogy az adatokat azonos gombbal csoportosítsa.
grunt> group_data = GROUP főiskolai hallgatók keresztnév szerint;
2. COGROUP: Hasonlóan működik, mint a csoport operátor. A fő különbség a Csoport és Cogroup operátor között az, hogy a csoport operátort általában egy relációval használják, míg a cogroupot egynél több relációval használják.
3. Csatlakozás: Két vagy több kapcsolat összekapcsolására szolgál.
Példa: Az öncsatlakozás elvégzéséhez tegyük fel, hogy az „ügyfél” relációt a HDFS tp sertésparancsokból töltjük be az ügyfelek1 és az ügyfelek2 két kapcsolatában.
grunt> ügyfelek3 = csatlakozzon ügyfelek1 azonosító alapján, ügyfelek2 azonosító szerint;
A csatlakozás lehet önálló csatlakozás, belső csatlakozás, külső csatlakozás.
4. Kereszt: Ez a disznóparancs kiszámítja két vagy több kapcsolat kereszttermékét.
grunt> cross_data = CROSS ügyfelek, megrendelések;
5. Unió: Két kapcsolatot egyesít. Az egyesítés feltétele, hogy mind a reláció oszlopainak, mind domainjeinek azonosaknak kell lenniük.
morgás> hallgató = UNIÓ hallgató1, hallgató2;
Fejlett sertésparancsok
Vessen egy pillantást az alábbiakban bemutatott fejlett Pig parancsokra:
1. Szűrés: Ez segít a relatív szűrők kiszűrésében, bizonyos feltételek alapján.
filter_data = FILTER főiskolai hallgatók város szerint == 'Chennai';
2. Megkülönböztetés: Ez segít a redundáns összetevők eltávolításában a kapcsolatból.
morgás> megkülönböztetett adatok = DISTINCT főiskolai hallgatók;
Ez a szűrés új relációnevet fog létrehozni: „különálló_adatok”
3. Foreach: Ez elősegíti az adatok átalakítását az oszlopadatok alapján.
grunt> foreach_data = FOREACH student_details GENERATE azonosító, életkor, város;
Ezzel megkapja az egyes hallgatók azonosítóját, életkorát és városi értékeit a student_details relációból, és így egy másik foreach_data nevű relációba tárolja.
4. Rendezés: Ez a parancs rendezett sorrendben jeleníti meg az eredményt egy vagy több mező alapján.
grunt> order_by_data = ORDER főiskolai hallgatók kor szerint DESC szerint;
Ez az „egyetemi hallgatók” viszonyt életkor szerinti csökkenő sorrendbe rendezi.
5. Limit: Ez a parancs korlátozott számú lesz. összefüggésekből álló tuplák száma.
grunt> limit_data = LIMIT hallgatói_adatok 4;
Tippek és trükkök
Az alábbiakban bemutatjuk a Pig parancsok különböző tippeit és trükköit: -
1. Engedélyezze a tömörítést a be- és kimeneten:
set input.compression.enabled true;
set output.compression.enabled true;
A fent említett kódsoroknak a szkript elején kell lennie, hogy a Pig parancsok lehetővé tegyék a tömörített fájlok olvasását vagy a tömörített fájlok outputként történő létrehozását.
2. Csatlakozzon több kapcsolathoz:
A bal oldali csatlakozás elvégzéséhez mondjuk három kapcsolaton (input1, input2, input3), az SQL-t kell választania. Ennek oka az, hogy a külső csatlakozást a Pig nem támogatja több, mint két táblán.
Inkább balra hajt, hogy csatlakozzon két lépésben, például:
data1 = JOIN input1 GYERMEKBEN GYŰRŰ, input22 GOMBBAL;
data2 = JOIN data1 BY1 bemenet :: kulcs BAL, input3 BY gomb;
Ez azt jelenti, hogy két térkép-csökkentő munka van.
A fenti feladat hatékonyabb végrehajtásához választhat a „Cogroup” opcióra. A Cogroup több kapcsolathoz is csatlakozhat. A Cogroup alapértelmezés szerint nem csatlakozik a külső csoporthoz.
Következtetés
A sertés egy eljárási nyelv, amelyet általában az adattudósok használnak ad-hoc feldolgozáshoz és a gyors prototípus készítéséhez. Ez egy nagyszerű ETL és nagy adatfeldolgozó eszköz. A sertések szkripteit más nyelvek is felhívhatják, és fordítva. Ezért a Pig parancsok nagyobb és összetett alkalmazások készítésére is felhasználhatók.
Ajánlott cikkek
Ez egy útmutató a Pig parancsokhoz. Itt megvitattuk az alapvető, valamint a fejlett Pig parancsokat és néhány azonnali Pig parancsot. A következő cikkben további információkat is megnézhet -
- Adobe Photoshop parancsok
- Tableau parancsok
- SQL cheat sheet (parancsok, ingyenes tippek és trükkök)
- VBA parancsok - befejező érintések
- Különböző műveletek a Tuples-szel kapcsolatban