
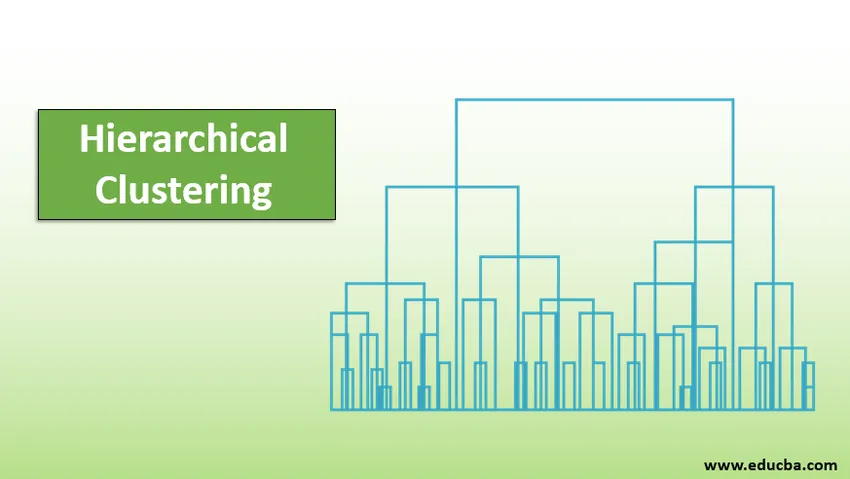
Bevezetés a hierarchikus klaszterezésbe
- Nemrégiben egyik ügyfelünk arra kérte csapatunkat, hogy hozzon létre egy olyan szegmens listáját, amely az ügyfelekön belül fontossági sorrendben áll, hogy megcélozza őket az újonnan bevezetett termékek egyikének franchise biztosítására. Az a tény, hogy csak az ügyfelek szegmentálása részleges csoportosítással (k-átlag, c-fuzzy) nem hozza ki a fontossági sorrendet, ahol a hierarchikus csoportosulás jelenik meg a képen.
- A hierarchikus klaszterezés az adatokat különféle csoportokra bontja néhány, a klaszterek néven ismert hasonlósági intézkedés alapján, amelynek lényegében a klaszterek közötti hierarchia kiépítésére irányul. Alapvetően felügyelet nélküli tanulás, és az attribútumok kiválasztása a hasonlóság mérésére alkalmazás-specifikus.
Az adatcsoport hierarchiája
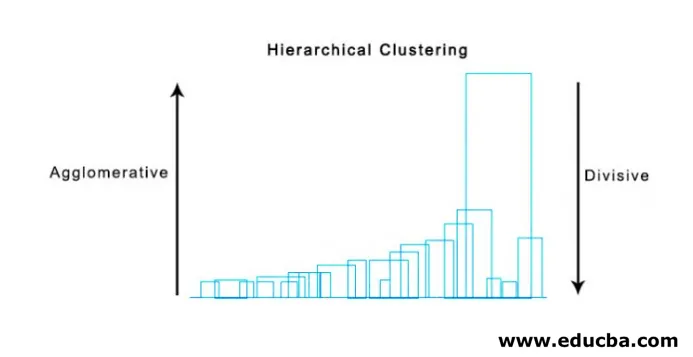
- Agglomerációs klaszterezés
- Osztó klaszter
Vegyünk egy példát azokra az adatokra, pontokra, amelyeket 5 diák szerzett, hogy csoportosítsuk őket egy közelgő versenyre.
| Diák | Marks |
| A | 10 |
| B | 7 |
| C | 28 |
| D | 20 |
| E | 35s |
1. Agglomerációs klaszterezés
- Először az egyes pontokat / elemeket itt súlyként klasztereknek tekintjük, és a hasonló pontok / elemek egyesítésével folytatjuk az új klaszter létrehozását az új szintre, amíg az egyetlen klaszter alulról felfelé építkező megközelítés marad.
- Az egyszeres és a teljes kötés az agglomerációs csoportosulás két népszerű példája. Kivéve az Átlagos és Centroid összeköttetést. Egyszeres összeköttetésben minden egyes lépésben egyesítjük a két klasztert, amelyeknek két legközelebbi tagja a legkisebb távolsággal rendelkezik. A teljes összeköttetésben beolvadunk a legkisebb távolság tagjaiba, amelyek a legkisebb maximális páros távolságot biztosítják.
- Proximity mátrix. Ez a hierarchikus csoportosítás végrehajtásának alapja, amely megadja az egyes pontok közötti távolságot.
- Készítsünk közelségi mátrixot a táblázatban megadott adatainkhoz, mivel kiszámoljuk az egyes pontok közötti távolságot más pontokkal, ez egy n × n alakú aszimmetrikus mátrix lesz, a mi esetünkben 5 × 5 mátrix.
A távolságszámítás népszerű módszere a következő:
- Euklidészi távolság (négyzet)
dist((x, y), (a, b)) = √(x - a)² + (y - b)²
- Manhattan távolság
dist((x, y), (a, b)) =|x−c|+|y−d|
A leggyakrabban az euklidiai távolságot használjuk, ugyanezt fogjuk használni itt, és komplex kapcsolódással járunk.
| Diák (klaszterek) | A | B | C | D | E |
| A | 0 | 3 | 18 | 10 | 25 |
| B | 3 | 0 | 21 | 13 | 28 |
| C | 18 | 21 | 0 | 8 | 7 |
| D | 10 | 13 | 8 | 0 | 15 |
| E | 25 | 28 | 7 | 15 | 0 |
A közelségi mátrix átlós elemei mindig 0, mivel az azonos ponttal rendelkező pont közötti távolság mindig 0, tehát az átlós elemeket nem szabad figyelembe venni a csoportosítás során.
Itt az 1. iterációban a legkisebb távolság 3, tehát összekapcsoljuk az A és a B klasztert, és új proximity mátrixot képezünk az A, B klaszterrel úgy, hogy az (A, B) klaszterpontot 10-nek vesszük, azaz legfeljebb ( 7, 10), így az újonnan kialakult közelségi mátrix lenne
| A klaszterek | (A, B) | C | D | E |
| (A, B) | 0 | 18 | 10 | 25 |
| C | 18 | 0 | 8 | 7 |
| D | 10 | 8 | 0 | 15 |
| E | 25 | 7 | 15 | 0 |
A 2., 7. iterációban a minimális távolságot követjük, így egyesítve C és E egy új klasztert (C, E), addig ismételjük az 1. iterációban követett eljárást, amíg az egyetlen klaszter végére kerülünk, itt a 4. iterációval állunk meg.
Az egész folyamatot az alábbi ábra szemlélteti:
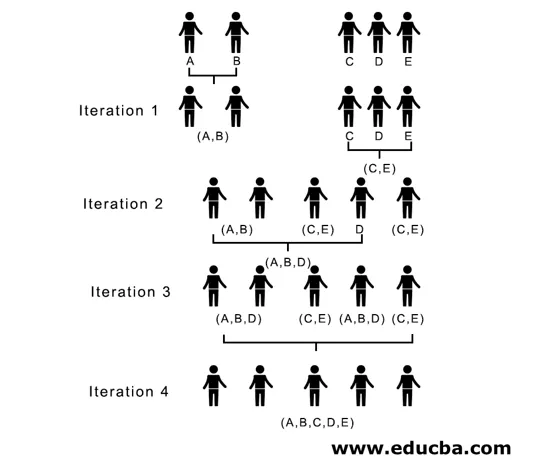
(A, B, D) és (D, E) a 2. klaszter a 3. iterációnál képződött, az utolsó iterációnál láthatjuk, hogy egyetlen klaszter maradt.
2. Osztó klaszter
Először az összes pontot egyetlen klaszternek tekintjük, és a legtávolabbi távolságra kell őket szétválasztani, amíg az egyes pontokkal együtt különálló klaszterekkel nem fejezzük be (nem feltétlenül tudunk megállni a közepén, attól függ, hogy az egyes klaszterekben mekkora elemet akarunk megtenni) minden lépésben. Ez éppen az ellenkezője az agglomerációs csoportosulásoknak és felülről lefelé irányuló megközelítés. Az osztó csoportosulás az ismétlődő módszer, a k jelentése a csoportosulás.
Az agglomerációs és az osztó klaszterezés közötti választás ismét alkalmazástól függ, mégis néhány szempontot figyelembe kell venni:
- Az osztódás összetettebb, mint az agglomerációs csoportosulás.
- Az osztó klaszterezés hatékonyabb, ha nem generálunk teljes hierarchiát az egyes adatpontokra.
- Az agglomerációs csoportosítás a helyi szabadalmak figyelembevételével hoz döntést, anélkül hogy figyelembe venné a globális mintákat, amelyek kezdetben nem fordíthatók vissza.
A hierarchikus klaszter képződése
A Dendogram rendkívül hasznos módszer a hierarchikus klaszterezés megjelenítésére, amely segít az üzleti életben. A dendrogramok fához hasonló struktúrák, amelyek rögzítik az egyesülések és hasadások sorozatát, ahol a függőleges vonal a klaszterek közötti távolságot, a függőleges vonalak közötti távolságot és a klaszterek közötti távolságot közvetlenül arányos, vagyis annál nagyobb a távolság, a klaszterek valószínűleg nem különböznek egymástól.
A dendogram segítségével meghatározhatjuk a klaszterek számát, csak húzzunk egy vonalat, amely a leghosszabb függőleges vonallal keresztezi a dendogramot, és több függőleges vonal keresztezi a figyelembe veendő klaszterek számát.
Az alábbiakban a Dendogram példa látható.
Vannak elég egyszerű és közvetlen python csomagok, amelyek funkciói hierarchikus klaszterezéshez és dendogramok ábrázolásához.
- A hierarchia a skipyustól.
- Cluster.hierarchy.dendogram a megjelenítéshez.
Közös forgatókönyvek, amelyekben a hierarchikus csoportosítást használják
- Ügyfélszegmentálás termék- vagy szolgáltatásmarketingbe.
- Városrendezés a szerkezetek / szolgáltatások / épület építési helyeinek meghatározására.
- A közösségi hálózatok elemzése, például, azonosítsa az összes MS Dhoni rajongót, hogy reklámozza bioévét.
A hierarchikus csoportosítás előnyei
Az előnyöket az alábbiakban adjuk meg:
- A klaszterhez hasonló részleges klaszterolás esetén a klaszterek számát a klaszterezés előtt meg kell ismerni, ami a gyakorlati alkalmazásoknál nem lehetséges, míg a hierarchikus klaszteroláshoz nincs szükség előzetes ismeretekre a klaszterek számáról.
- A hierarchikus klaszterezés hierarchiát ad ki, azaz olyan struktúrát, amely informatívabb, mint a részleges klaszterezés által visszaadott lapos klaszterek nem strukturált halmaza.
- A hierarchikus csoportosítást könnyű végrehajtani.
- A legtöbb forgatókönyv eredményeit hozza ki.
Következtetés
A klaszterezés típusa nagy különbséget okoz az adatok bemutatásakor. A hierarchikus klaszterezés inkább informatív és könnyebben elemezhető, inkább, mint a részleges klaszterezés. És gyakran társul a hőtérképekkel. Ne felejtsük el, hogy a hasonlóság vagy a különbség kiszámításához kiválasztott attribútumok elsősorban a klasztereket és a hierarchiát befolyásolják.
Ajánlott cikkek
Ez egy útmutató a hierarchikus klaszterezéshez. Itt tárgyaljuk a hierarchikus klaszterezés bevezetését, előnyeit és a közös forgatókönyveket, amelyekben a hierarchikus csoportosítást használják. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Klaszterezési algoritmus
- Fürtözés a gépi tanulásban
- Hierarchikus csoportosítás R-ben
- Klaszterezési módszerek
- Hogyan lehet eltávolítani a hierarchiát a Tableau-ban?