

Különbség az Apache Nifi és azApache Spark között
Hosszú ideig, amikor nehéz munkát végeztek, amelyet be kellett fejezni, az emberek lovakkal támaszkodtak a nehéz teher húzására, a sebesség fenntartására vagy bármi másra. Nem minden ló volt alkalmas minden feladatra. Ugyanez vonatkozik a mai technológiára. A minden nap új technológiák megjelenésével rendkívül fontos megismerni valódi alkalmazásukat. Két ilyen technológia az Apache Nifi és az Apache Spark, és ezekről fogunk tanulmányozni ebben a bejegyzésben.
Az Apache Spark egy fürtszámítógépes nyílt forráskódú keret, amelynek célja egy interfész biztosítása a fürtök teljes készletének implicit hibatűréssel és az adatok párhuzamosságával történő programozására. Használja az RDD-ket (Resilient Distributed Datasets) és feldolgozza az adatokat diszkretizált áramok formájában, amelyeket tovább használnak elemzési célokra.
Az Apache Nifi (amely a NiagaraFiles rövid formája) egy másik szoftverprojekt, amelynek célja a szoftverrendszerek közötti adatáramlás automatizálása. A tervezés folyamaton alapuló programozási modelln alapszik, amely olyan szolgáltatásokat nyújt, amelyek között szerepel a klaszterek képessége. Könnyen kezelhető, megbízható és hatékony rendszer az adatok feldolgozására és terjesztésére. Támogatja a méretezhető, irányított grafikonokat az adatok továbbításához, a rendszer közvetítéséhez és az átalakítási logikához. Vitassuk meg mindkét téma összehasonlítását.
Összehasonlítás az Apache Nifi és az Apache Spark (Infographics) között
Az alábbiakban az Apache Nifi és az Apache Spark összehasonlítása a 9 legjobban
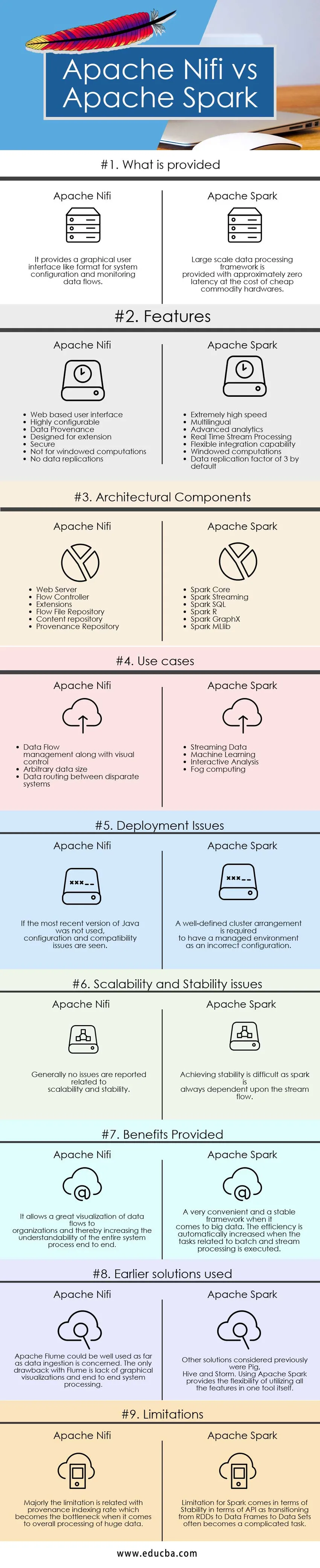
Az Apache Nifi és az Apache Spark közötti különbségek
Az Apache Nifi és az Apache Spark közötti különbségeket az alábbiakban ismertetjük:
- Az Apache Nifi egy olyan adatgyűjtő eszköz, amelyet könnyen használható, hatékony és megbízható rendszer biztosítására használnak, hogy az adatok feldolgozása és az erőforrások közötti terjesztése egyszerűvé váljon, míg az Apache Spark egy rendkívül gyors fürtszámítási technológia, amelyet a hatékonyan kihasználva az interaktív lekérdezéseket a memóriakezelésben és az adatfeldolgozási képességekben.
- Az Apache Nifi önálló és fürt módban működik, míg az Apache Spark jól működik helyi vagy önálló módban, Mesos, Fonal és más típusú nagy adatfürt módban.
- Az Apache Nifi szolgáltatásai között szerepel az garantált adattovábbítás, a hatékony adatpufferálás, a prioritási sorba állítás, az áramlás-specifikus QoS, az adat-előkészítés, a tekercs-puffer helyreállítása, a vizuális parancs és a vezérlés, a folyamatsablonok, a biztonság, a párhuzamos adatfolyam-képességek, míg az apache-szikra jellemzői a villámlást is tartalmazzák. sebesség-feldolgozási képesség, többnyelvű, memóriába épített számítástechnika, árucikk-hardver rendszerek hatékony felhasználása, Advanced Analytics, hatékony integrációs képesség.
- Az Apache Nifi lehetővé teszi a rendszer jobb olvashatóságát és átfogó megértését azáltal, hogy megjelenítési képességeket, valamint a drag and drop funkciókat biztosít. Az adatáramlás könnyen kezelhető és irányítható a hagyományos technikákkal és folyamatokkal, míg az Apache Spark esetében az ilyen megjelenítések megtekintéséhez olyan klaszterkezelő rendszerre van szükség, mint amilyen az Ambari. Az Apache Spark önmagában nem nyújt megjelenítési képességeket, és a programozás szempontjából csak jó. Ez messze egy nagyon kényelmes és stabil rendszer hatalmas mennyiségű adat feldolgozására.
- Az Apache Nifi korlátozása azzal kapcsolatos, hogy mi az előnye. Az egyetlen drag and drop szolgáltatás korlátozza azt, hogy nem tud méretezni és robusztus legyen, ha más komponensekkel és eszközökkel integráljuk, míg az Apache Spark esetében az elsődleges korlátozás a kiterjedt árucikk hardver használatával és kezelésével jár. időnként unalmas feladattá válik. A másik bejelentett korlátozás a diszkretizált adatfolyamhoz és az ablakosított vagy kötegelt adatfolyamhoz kapcsolódó streaming képességekkel együtt jön létre, ahol az RDD-k átalakítása az adatkeretre és az adatkészletekre időnként instabilitást okoz.
Apache Nifi vs Apache Spark összehasonlító táblázat
| Az összehasonlítás alapjai | Apache Nifi | Apache Spark |
| Mi biztosított | Grafikus felhasználói felületet biztosít, például formátumot a rendszerkonfigurációhoz és az adatfolyamok megfigyeléséhez. | A nagyszabású adatfeldolgozási keretet megközelítőleg nulla késéssel látják el, olcsó árucikk-hardver árán. |
| Jellemzők |
|
|
| Építészeti elemek |
|
|
| Használjon eseteket |
|
|
| Telepítési kérdések | Ha a Java legfrissebb verzióját nem használták, akkor a konfigurációs és kompatibilitási problémák merülnek fel | Megfelelően definiált fürt-elrendezésre van szükség ahhoz, hogy a kezelt környezet hibás konfiguráció legyen |
| Skálázhatósággal és stabilitással kapcsolatos kérdések | Általában nem számoltak be a skálázhatósággal és stabilitással kapcsolatos kérdésekről | A stabilitás elérése nehéz, mivel a szikra mindig függ az áramlástól. |
| Előnyök | Ez lehetővé teszi a szervezetek felé irányuló adatáramlások nagyszerű megjelenítését, ezáltal növelve a teljes rendszerfolyamat érthetőségét a végétől a végéig | Nagyon kényelmes és stabil keretrendszer a nagy adatok esetében. A hatékonyság automatikusan növekszik, amikor a kötegelt és adatfolyam-feldolgozással kapcsolatos feladatokat végrehajtják. |
| Korábbi megoldások | Az Apache Flume jól használható az adatfelvétel szempontjából. Az Flume egyetlen hátránya a grafikus megjelenítések hiánya és a végpontok közötti rendszer feldolgozása | Egyéb, korábban figyelembe vett megoldások a Pig, a kaptár és a vihar. Az Apache Spark használata rugalmasságot biztosít az összes szolgáltatás egyetlen eszközben történő felhasználása során. |
| korlátozások | A korlátozás elsősorban a származási hely indexálási rátájával kapcsolatos, amely a szűk keresztmetszet lesz a hatalmas adatok átfogó feldolgozásakor. | A Spark korlátozása az API szempontjából a stabilitás szempontjából rejlik, mivel az RDD-kről az adatkeretekre az adatkészletekre való áttérés gyakran bonyolult feladattá válik. |
Következtetés - Apache Nifi vs Apache Spark
A bejegyzés befejezéséhez elmondható, hogy az Apache Spark nehéz lófélék, míg az Apache Nifi fürge versenylovak. Mindkettőnek megvannak a saját előnyei és korlátozásai, amelyeket a saját területükön kell felhasználni. Döntenie kell a vállalkozásának megfelelő eszközről. Kísérje figyelemmel a blogunkat további cikkekkel, amelyek a big data újabb technológiáival kapcsolatosak.
Ajánlott cikk
Ez egy útmutató az Apache Nifi és az Apache Spark, azok jelentésének, a fej közötti összehasonlításnak, a legfontosabb különbségeknek, az összehasonlító táblázatnak és a következtetéseknek. A következő cikkeket is megnézheti további információkért -
- Apache Hadoop vs Apache Spark | A tíz legjobb összehasonlítás, amit tudnod kell!
- Apache Storm vs Apache Spark - Tanulj meg 15 hasznos különbséget
- 7 fontos dolog az Apache Spark-ról (útmutató)
- A legjobb 15 dolog, amelyet tudnia kell a MapReduce vs Spark termékről