

Különbség az Apache Hive és az Apache HBase között -
Az Apache Hive történet 2007-ben kezdődik, amikor a nem Java Programmernek küzdenie kell a Hadoop MapReduce használata közben. A kutatók és a fejlesztők azt jósolták, hogy a holnap a Big Data korszaka. Az adatok már különböző formátumai, például strukturált, félig strukturált és strukturálatlanok halmozódtak fel. Még a Facebook is küzdött a nagyobb mennyiségű adatfeldolgozás ellen. A Facebook kutatói bemutatták az Apache Hive-t az adatfeldolgozáshoz a Hadoop Cluster-en. A Facebook volt az első cég, amely felbukkant az Apache Hive-vel.
Az Apache HBase története 2006-ban kezdődik, amikor a san francisco-i startup Powerset egy természetes nyelvű keresőmotort próbált létrehozni az interneten. A HBase a Google Bigtable megvalósítása. Valaha rájöttünk, miért volt szükség egy újabb tárolási architektúrára? A relációs adatbázis-kezelő rendszer az 1970-es évek eleje óta működik. Számos olyan eset fordul elő, amelyben a relációs adatbázisoknak tökéletesen értelme van, de bizonyos speciális problémák esetén a relációs modell nem igazán illeszkedik.
Bemutatok részletesebben az Apache Hive-ről és az Apache HBase-ról.
Különbségek az Apache Hive és az Apache HBase között
Az Apache Hive egy Apache nyílt forráskódú projekt, amely a Hadoop tetejére épült nagy adatkészletek lekérdezésére, összegzésére és elemzésére SQL-szerű felület használatával. Az Apache Hive SQL-szerű HiveQL nyelvet kínál, amely átláthatóan átalakítja a lekérdezéseket MapReduce-re végrehajtás céljából a Hadoop Distributed File System (HDFS) tárolt nagy adatkészleteken. Az Apache Hive egy Hadoop fürtösszetevő, amelyet általában az elemző elemzők telepítenek. Az Apache kaptár a nagy ETL jobok kötegelt feldolgozására szolgál. Az Apache Hive támogatja a kötegelt SQL lekérdezéseket is nagyon nagy adatkészleteken. Az Apache Hive növeli a sématervezés rugalmasságát, valamint az adatsorozációt és az érdeklődést. Az Apache Hive nem támogatja az online tranzakció-feldolgozást (OLTP), mert a kaptár nem támogatja a lekérdezéseket valós idejű és sorszintű frissítésekkel.
Az Apache HBase egy nyílt forráskódú NoSQL adatbázis, amely valós idejű, olvasási és írási hozzáférést biztosít nagy adatkészletekhez. A NoSQL nem relációs adatbázis. Az Apache HBase oszlop-orientált adatbázis, amely a Hadoop Distributed File System (HDFS) tetején fut. Tehát a HBase a NoSQL előnyeit hozza a Hadoophoz. Az Apache HBase a HDFS-ben található adatok véletlenszerű hozzáférési képességeit biztosítja. Kihasználja a HDFS által biztosított hibatoleranciát. A felhasználó tárolja az adatokat a HDFS-ben akár közvetlenül, akár a HBase-en keresztül.
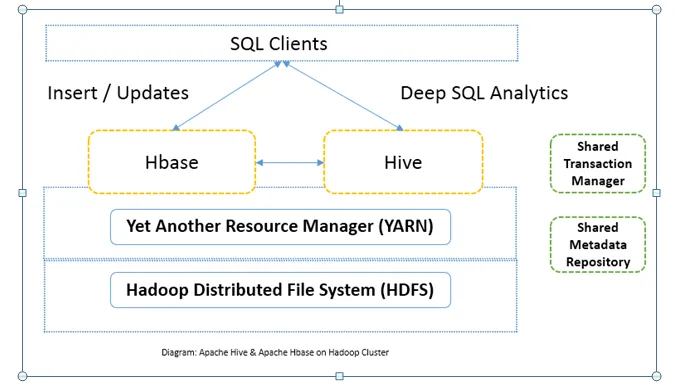
Összehasonlítás az Apache Hive és az Apache HBase között (Infographics)
Az alábbiakban látható az első 12 különbség az Apache Hive és az Apache HBase között

Főbb különbségek - Apache Hive vs Apache HBase
Az alábbiakban felsoroljuk a pontok listáját, írjuk le az Apache Hive és az Apache HBase közötti főbb különbségeket:
- Az Apache HBase egy adatbázis, míg az Apache Hive egy adatbázis motor.
- Az Apache Hive-t elsősorban kötegelt feldolgozásra (OLAP), míg az Apache HBase-t elsősorban tranzakciós feldolgozásra (OLTP) használják.
- Az Apache Hive az SQL lekérdezések nagy részét hajtja végre, míg az Apache HBase közvetlenül nem engedélyezi az SQL lekérdezéseket.
- Az Apache Hive nem támogatja olyan rekordszintű műveleteket, mint a frissítés, beillesztés és törlés, míg az Apache HBase olyan rekordszintű műveleteket támogat, mint a frissítés, beillesztés és törlés.
- Az Apache Hive a MapReduce tetején fut, míg az Apache HBase a Hadoop Distributed File System (HDFS) tetején.
Az Apache Hive lekérdezi a fájlokat egy virtuális tábla meghatározásával és a tetején futó HQL lekérdezésekkel. Ez egy folyamat, amikor a fájlok gyakorlatilag egy táblához hasonló struktúrához kapcsolódnak, és a felhasználó végrehajthatja a Hive Query Language (HQL) nyelvet, és ezeket a lekérdezéseket átalakítja a Hive MapReduce Job-ba. A felhasználónak nem kell írnia a MapReduce feladatot, a HQL lekérdezéseket belsőleg jar fájlokká alakítják át, és ezeket a jar fájlokat adatkészletekre valósítják meg.
Az Apache HBase alkalmazásban a táblák régiókra vannak felosztva, és a regionális kiszolgálók szolgálják ki őket. A további régiókat függőlegesen oszlopcsaládok szerint osztják el áruházakként, és az üzletek fájlokként kerülnek elmentésre a HDFS-ben.
Mikor kell használni az Apache Hive-t:
- Adattárolási követelmények
- Analitikai lekérdezések
- Adatelemzés, akik ismerik az SQL-t
Mikor kell használni az Apache HBase-t:
- Gyors és interaktív adatfeldolgozás
- Valós idejű lekérdezések
- Gyors keresések
- Szerveroldali feldolgozás
- Véletlenszerű olvasási / írási hozzáférés a Big Data szolgáltatáshoz
- Az alkalmazás méretezhetősége
Az Apache Hive kiszámítja az e-kereskedelem webhelyének trendeit és naplóit egy adott időtartamra, régióra vagy időzónára vonatkozóan. Használható a kötegelt lekérdezések feldolgozására történelmi adatok alapján, míg az Apache HBase a Facebook vagy a LinkedIn által használható üzenetküldéshez és valós idejű elemzéshez. Használható a kedvelések számlálására is.
Apache Hive vs Apache HBase összehasonlító táblázat
Fontos tárgyakat tárgyalok, és különbséget teszek az Apache Hive és az Apache HBase között.
| Apache kaptár | Apache HBase | |
| Adatfeldolgozás | Az Apache Hive-t használják
kötegelt feldolgozás, azaz Online Analytical Processing (OLAP) | Az Apache HBase-t tranzakciós feldolgozásra, azaz online tranzakciós feldolgozásra (OLTP) használják. |
| Feldolgozási sebesség | Az Apache Hive hosszabb késéssel rendelkezik, mivel a háttérben végrehajtja a MapReduce feladatot | Az Apache HBase valósidejű lekérdezésen és sokkal gyorsabban működik, mint az Apache Hive |
| Kompatibilitás a Hadoop-tal | Az Apache Hive a MapReduce tetején fut | Az Apache HBase az HDFS tetején fut |
| Meghatározás | Az Apache Hive nyílt forráskódú és hasonló az analitikus lekérdezésekhez használt SQL-hez | Az Apache HBase nyílt forráskódú NoSQL adatbázis, amelyet valós idejű lekérdezésre használnak |
| Megosztott metaadatok | Az Apache Hive-ben létrehozott adatok automatikusan láthatóak az Apache HBase számára | Az Apache HBase-ben létrehozott adatok automatikusan láthatóak az Apache Hive számára |
| Séma | Az Apache kaptár támogatja a sémát az adatok táblázatokba illesztéséhez | Az Apache HBase séma-mentes adatbázis. |
| A szolgáltatás frissítése | A frissítési szolgáltatás bonyolult az Apache Hive alkalmazásban | A felhasználó nagyon egyszerűen frissítheti az adatokat az Apache HBase-ban |
| Tevékenységek | Az Apache Hive műveletei nem valós időben futnak | Az Apache HBase műveletei valós időben futnak |
| Adattípusok | Az Apache Hive a strukturált és félig strukturált adatokra szolgál | Az Apache HBase nem strukturált adatokhoz készült. |
| Konzisztencia szint | Az Apache kaptár támogatja az esetleges konzisztenciát | Az Apache HBase támogatja az azonnali konzisztenciát |
| Osztási módszerek | Az Apache Hive támogatja a Sharding szolgáltatásokat | Az Apache HBase a Sharding funkciókat is támogatja |
| Adattárolás | A dátumot a Hive Metastore, partíciók és vödrök tárolja az Apache Hive alkalmazásban | Az adatokat az Apache HBase táblázatok oszlopokban és sorok szerint tárolják |
Következtetés - Apache Hive vs Apache HBase
Az Apache Hive és az Apache HBase általában ugyanazon a fürtön együtt használatos. Mindkettő együtt használható a feldolgozási teljesítmény fokozására. Mivel a kaptár javítja a HDFS analitikai oldalát, míg a HBase valós időben javítja a tranzakciókat. A felhasználó a Hive-t ETL-eszközként használhatja kötegelt beszúrásként az adatokkal a HBase-be, majd olyan lekérdezéseket hajthat végre, amelyek a HBase táblázatokban található adatokat tovább összekapcsolhatják a HDFS-en már meglévő adatokkal. Az adatok olvashatók és írhatók az Apache Hive-től a HBase-ig és vissza. Az Apache Hive és az Apache HBase közötti felület még érési szakaszban van. Még sok minden vár még. Mégis elmondhatom, hogy mind az Apache Hive, mind az Apache HBase a Hadoop-fürtöt robusztusabbá és erősebbé teszi.
Kapcsolódó cikkek:
Ez egy útmutató az Apache Hive vs Apache HBase-hez, azok jelentésére, a fej-fej összehasonlításra, a legfontosabb különbségekre, az összehasonlító táblázatra és a következtetésekre. A következő cikkeket is megnézheti további információkért -
- Az öt legfontosabb nagy adatindencia
- 5 A nagy adatelemzés kihívásai
- Hogyan lehet feltörni a Hadoop fejlesztői interjút?
- 5 A nagy adatelemzés kihívásai