
Bevezetés az adattárház architektúrájába
- Az Adatraktár olyan tárolóhely, amely többféle típusú adatgyűjtést tartalmaz, többféle forrásból beszerezve.
- Az a teljes folyamat, amelyben a külső adatforrásokat megszerzik, feldolgozzák, tárolják és felhasználható információkké elemezik, egy olyan rendszerkészletben zajlik, amelyet egyesít egyetlen, a Data Warehouse Architecture néven ismert séma.
Data Warehouse Architecture

Az adattárház architektúrája általában három rétegből áll.
- Élvonalban
- Középszint
- Alsó szint
Élvonalban
- A legfelső szint az ügyféloldali felépítésből áll.
- Az Adatraktárban tárolt, átalakított és logikai alkalmazású információkat üzleti célra használják fel és szerezzék meg ebben a szintben.
- A jelentés elkészítéséhez és elemzéséhez számos eszköz létezik a kívánt információ előállításához.
- Az adatbányászat, amely manapság nagy trend lett, itt történik.
- Az összes követelményelemzési dokumentumot, a költségeket és az összes olyan szolgáltatást, amely meghatározza a profit alapú üzleti üzletet, ezen Adattárház információt használó eszközök alapján készítik el.
Középszint
- A középső réteg az OLAP szerverekből áll
- Az OLAP Online Analytical Processing Server
- Az OLAP célja az információ elemzése az üzleti elemzők és vezetők számára
- Mivel a középső rétegben található, jogszerűen kölcsönhatásba lép az alsó rétegben található információkkal, és továbbadja a betekintést a felső szintű eszközökhöz, amelyek feldolgozzák a rendelkezésre álló információkat.
- Az Adatraktár architektúrában leginkább a Relációs vagy Többdimenziós OLAP-t használják.
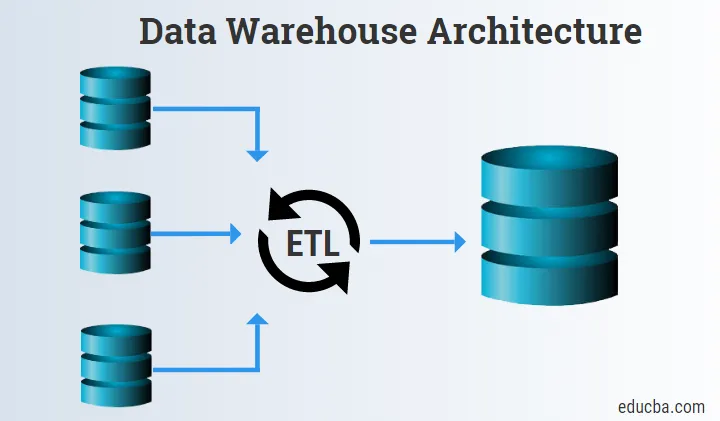
Alsó szint
Az alsó szint elsősorban az adatforrásokból, az ETL eszközből és az adattárházból áll.
1. Adatforrások
Az adatforrások a forrás adatokból állnak, amelyeket megszerznek és továbbadnak a Staging és az ETL eszközökhöz a további feldolgozáshoz.
2. ETL eszközök
- Az ETL eszközök nagyon fontosak, mivel elősegítik a logika, a nyers adatok és a sémák egyesítését, és az információkat betöltik az adattárházba vagy az adatkezelő mappákba.
- Időnként az ETL betölti az adatokat az Adatlapokba, majd az adatokat a Data Warehouse tárolja. Ezt a megközelítést Alulról felfelé irányuló megközelítésnek nevezik.
- Az a megközelítés, amikor az ETL közvetlenül tölti be az adatokat az Adattárba, felülről lefelé mutató módszerként ismert.
Különbség a fentről lefelé és az alulról felfelé történő megközelítés között
| Felülről lefelé irányuló megközelítés | Alulról felfelé építkező megközelítés |
| Meghatározott és következetes képet nyújt az információról, mivel az adattárházból származó információkat felhasználják az Adatlapok létrehozására | A jelentések könnyen elkészíthetők, mivel először létrehozzák az adatkártyákat, és viszonylag könnyű együttműködni az adatokkal. |
| Erős modell, ezért a nagy cégek kedvelik | Nem olyan erős, de az adattárház kibővíthető, és létrehozható az adatkártyák száma |
| Idő, költség és karbantartás magas | Az idő, a költség és a karbantartás alacsony. |
Data Marts
- A Data Mart egy olyan tároló elem is, amelyet az egyes hatóságok egy adott funkcióval vagy egy vállalattal kapcsolatos adatainak tárolására használnak.
- Az Data mart összegyűjti az adatokat a Data Warehouse-ból, és így mondhatjuk, hogy az data mart az információ részhalmazát tárolja a Data Warehouse-ban.
- Az adattáblák rugalmasak és kicsik.
3. Adattárház
- A Data Warehouse a teljes Data Warehouse Architecture központi alkotóeleme.
- Adattárként szolgál az információk tárolására.
- Nagy mennyiségű adat tárolódik az Adattárházban.
- Ezt az információt számos technológia használja, például a Big Data, amelyek megkövetelik az információ nagy részhalmazainak elemzését.
- A Data Mart a Data Warehouse modellje.
Az adattárház-architektúra különböző rétegei
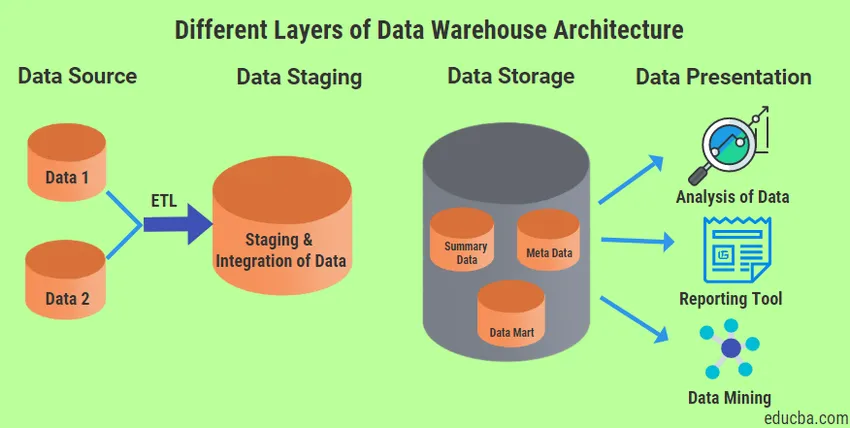
Négy különböző típusú réteg létezik, amelyek mindig jelen vannak az Data Warehouse Architecture-ben.
1. Adatforrás réteg
- Az adatforrás réteg az a réteg, ahol a forrásból származó adatok találkoznak, majd a kívánt műveletekhez továbbítják a többi rétegre.
- Az adatok bármilyen lehetnek.
- A forrásadatok lehetnek adatbázisok, táblázatok vagy bármilyen más típusú szöveges fájl.
- A forrás adatok bármilyen formátumban lehetnek. Nem várhatjuk el, hogy azonos formátumú adatokat kapjunk, mivel a források nagyon különböznek egymástól.
- A valós életben a forrásadatok néhány példája lehet
- Naplófájlok az egyes alkalmazásokról vagy munkahelyekről, vagy a munkaadók belépéséről a vállalatban.
- Felmérési adatok, tőzsdei adatok stb.
- A webböngésző adatai és még sok más.
2. Adatfázis-réteg
A következő lépések az adatfázis-rétegben zajlanak.
1. Adatkivonás
A forrásréteg által kapott adatok továbbadódnak a szakaszos rétegbe, ahol a beszerzett adatokkal az első folyamat az extrakció.
2. Leszállási adatbázis
- A kinyert adatokat ideiglenesen tárolja a leszállási adatbázisban.
- Az adatok kinyerése után beolvassa az adatokat.
3. Megállóhely
- Az adatokat a leszállási adatbázisban veszik, és több minőségi ellenőrzést és szakaszos műveletet hajtanak végre a megállási területen.
- A struktúrát és a sémát szintén azonosítják, és kiigazításokat végeznek a rendezetlen adatokban, ily módon megkísérelve megteremteni a megszerzett adatok közötti egységességet.
- A hely vagy az adatok felállítása közvetlenül az átalakítás és a változtatások előtt egy további előnye, amely nagyon fontosvá teszi az átmeneti folyamatot.
- Megkönnyíti az adatfeldolgozást.
4. ETL
- Ez egy kinyerés, átalakítás és terhelés.
- Az ETL eszközöket az adatok integrálására és feldolgozására használják, ahol a logikát meglehetősen nyers, de kissé rendezett adatokra alkalmazzák.
- Ezeket az adatokat az előírt analitikus jelleg szerint nyerik ki, és olyan adatokká alakítják át, amelyeket megfelelőnek tartanak az adattárházban történő tároláshoz.
- Az átalakítás után az adatokat vagy inkább egy információt végül betöltjük az adattárházba.
- Néhány példa az ETL eszközökre: Informatica, SSIS stb.
3. Adattárolási réteg
- A feldolgozott adatokat az Adattárház tárolja.
- Ezeket az adatokat megtisztítják, átalakítják és meghatározott struktúrával készítik el, és ezáltal lehetőséget adnak a munkaadók számára, hogy az üzleti igények szerint felhasználják az adatokat.
- Az architektúra megközelítésétől függően az adatokat a Data Warehouse, valamint az Data Marts tárolja. Az adatleírásokat a későbbi szakaszokban tárgyaljuk.
- Néhányukban működési adattároló is található.
4. Adatbemutató réteg
- Ebben a rétegben a felhasználók kapcsolatba léphetnek az adattárházban tárolt adatokkal.
- Lekérdezéseket és számos eszközt alkalmazunk az adatok alapján különböző típusú információk megszerzésére.
- Az információ az adatok grafikus ábrázolásán keresztül jut el a felhasználóhoz.
- A jelentési eszközöket használják az üzleti adatok megszerzésére, és az üzleti logikát különféle információk gyűjtésére is alkalmazzák.
- A metaadatok és a rendszer műveletei, valamint a teljesítmény szintén ezen a rétegen vannak fenntartva és megnézve.
Következtetés
Az Data Warehouse szempontjából fontos szempont a hatékonysága. A hatékony adattárház létrehozásához az üzleti elemzési keretrendszer néven ismert keretet építünk fel. Négyféle nézet létezik az adattárház tervezésével kapcsolatban.
1. Felülről lefelé nézet: Ez a nézet csak az adattárház kiválasztásához szükséges speciális információkat teszi lehetővé.
2. Adatforrás nézet: Ez a nézet az összes információt mutatja az adatforrástól az átalakítás és tárolás módjáig.
3. Adatraktár nézet: Ez a nézet az adattárházban található információkat mutatja a ténytáblákon és a mérettáblázatokon keresztül.
4. Üzleti lekérdezés nézet: Ez egy olyan nézet, amely az adatokat a felhasználó szempontjából mutatja.
Ajánlott cikkek
Ez egy útmutató az Adattárház architektúrájához. Itt megvitattuk az adattárház-architektúra nézetek, rétegek és rétegek különféle típusait. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Karrier az adattárolásban
- Hogyan működik a JavaScript?
- Adatraktári interjúkérdések
- Mi az a Panda?