

Bevezetés a Spark parancsokba
Az Apache Spark a Hadoop tetejére épített keretrendszer a gyors számításokhoz. Bővíti a MapReduce fogalmát a fürt alapú forgatókönyvben egy feladat eredményes futtatásához. A Spark Command Scala nyelven íródott.
A Hadoop a Spark számára a következő módon használható fel (lásd alább):
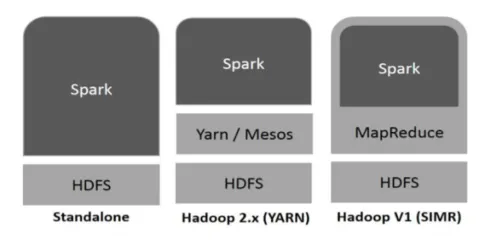
1. ábra
https://www.tutorialspoint.com/
- Önálló: A Spark közvetlenül a Hadoop tetején helyezkedik el. A szikrafeladatok párhuzamosan futnak a Hadoop-on és a Spark-on.
- Hadoop fonal : A Spark a fonalon előzetes telepítés nélkül fut.
- Szikra a MapReduce-ban (SIMR): A Spark a MapReduce-ben a szikra-feladat elindítására szolgál az önálló telepítés mellett. A SIMR segítségével elindíthatja a Sparkot, és adminisztrátori hozzáférés nélkül használhatja a héját.
A szikra alkotóelemei:
- Apache Spark Core
- Spark SQL
- Spark streaming
- MLib
- GraphX
A rugalmas elosztott adatkészleteket (RDD) tekintik a Spark parancsok alapvető adatszerkezetének. Az RDD változatlan és csak olvasható jellegű. A szikra-parancsok mindenféle kiszámítása transzformációk és RDD-k által végrehajtott műveletek révén történik.
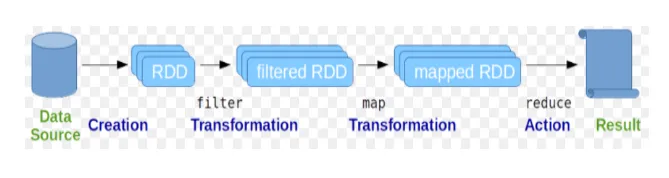
2. ábra
Google kép
A szikrahéj médiumot biztosít a felhasználók számára, hogy kölcsönhatásba lépjen funkcióival. A Spark parancsoknak nagyon sok különféle parancsuk van, amelyek felhasználhatók az interaktív héjon lévő adatok feldolgozására.
Alapvető szikra-parancsok
Vessen egy pillantást az alábbi alapvető Spark-parancsokra: -
-
A Spark héj elindítása:

3. ábra
-
Olvassa be a fájlt a helyi rendszerből:

Itt az „sc” a szikra összefüggése. Tekintettel arra, hogy az „data.txt” a home könyvtárban található, így olvasható, külön meg kell adni a teljes elérési utat.
-
Hozzon létre RDD-t a párhuzamosítással

A NewData az RDD.
-
Számoljon tételeket az RDD-ben

-
Gyűjt
Ez a funkció visszaadja az RDD összes tartalmát az illesztőprogramhoz. Ez hasznos a hibakeresés során az írási program különböző lépésein.
-
Olvassa el az első 3 tételt az RDD-ből

-
Mentse el a kimeneti / feldolgozott adatokat a szöveges fájlba

Itt a „output” mappa az aktuális útvonal.
Köztes szikra-parancsok
1. Szűrjük az RDD-n
Hozzunk létre új RDD-t olyan elemekhez, amelyek „igen” -t tartalmaznak.

Az átalakító szűrőt ki kell hívni a meglévő RDD-re, hogy kiszűrje az „igen” szót, amely új RDD-t hoz létre az új elemlista segítségével.
2. Lánc működése

Itt a szűrőátalakítás és a számláló művelet együtt működtek. Ezt láncműveletnek hívják.
3. Olvassa el az RDD első tételét

4. Számolja az RDD partíciókat
Mint tudjuk, az RDD több partícióból áll, szükség van a nem számlálására. a válaszfalak. Mivel segít a hangolásban és a hibaelhárításban, miközben a Spark parancsokkal dolgozik.

Alapértelmezés szerint a minimális szám. pf partíció 2.
5. csatlakozzon
Ez a funkció két táblát egyesít (a tábla elem páros formában van) a közös kulcs alapján. A páros RDD-ben az első elem a kulcs, a második elem az érték.
6. Gyorsítótár-fájl
A gyorsítótárazás optimalizálási technika. Az RDD gyorsítótárazása azt jelenti, hogy az RDD a memóriában marad, és a jövőben minden számítást a memóriában lévő RDD-re kell elvégezni. Ez megtakarítja a lemez olvasási idejét és javítja az előadásokat. Röviden: lerövidíti az adatok elérésének idejét.

Azonban az adatok nem kerülnek gyorsítótárba, ha a fenti funkció felett fut. Ezt a következő weboldal látogatásával lehet igazolni:
http: // localhost: 4040 / tároló
Az RDD gyorsítótárban lesz, miután a művelet megtörtént. Például:

A gyorsítótárhoz () hasonlóan működő további funkció továbbra is fennáll (). A fennmaradás rugalmasságot biztosít a felhasználók számára az érvelés megfogalmazásakor, amely segíthet az adatok gyorsítótárazásában a memóriában, a lemezen vagy a halom memóriában. A fennmaradás érv nélkül ugyanolyan, mint a gyorsítótár ().
Speciális szikra-parancsok
Vessen egy pillantást az alábbiakban bemutatott speciális Spark-parancsokra: -
-
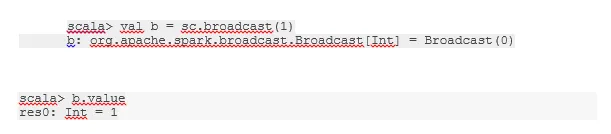
Broadcast egy változót
A Broadcast változó segít a programozónak, hogy a fürt minden gépen tárolt egyetlen változót olvassa, ahelyett, hogy a változót feladatokkal továbbítja. Ez elősegíti a kommunikációs költségek csökkentését.
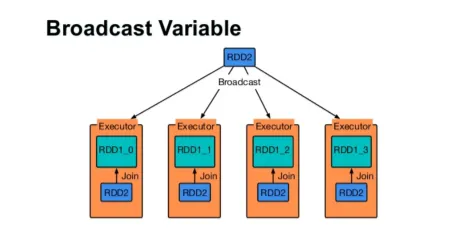
4. ábra
Google Kép
Röviden: a sugárzott változónak három fő jellemzője van:
- Változhatatlan
- Fit a memóriába
- A fürtön oszlik meg
-
akkumulátorok
Az akkumulátorok azok a változók, amelyeket hozzáadnak a kapcsolódó műveletekhez. Az akkumulátoroknak sok felhasználása van, például számlálók, összegek stb.

A kódban lévő akkumulátor neve a Spark UI-ban is látható.
-
Térkép
A Térkép funkció segít az RDD minden sorának iterálásában. A térképen használt funkciót az RDD minden elemére alkalmazzák.
Például a RDD (1, 2, 3, 4, 6) esetén, ha az „rdd.map (x => x + 2)” -t alkalmazzuk, akkor az eredményt (3, 4, 5, 6, 8) kapjuk.
-
Flatmap
A sík térkép hasonlóan működik, mint a térkép, de a térkép csak egy elemet ad vissza, míg a sík térkép visszatér az elemek listáját. Ezért a mondatok szavakkal történő felosztásához lapos térképre van szükség.
-
Egyesül
Ez a funkció segít elkerülni az adatok megoszlását. Ezt a meglévő partícióban alkalmazzák, így kevesebb adat van keverve. Ily módon korlátozhatjuk a fürt csomópontjainak használatát.
Tippek és trükkök a szikraparancsok használatához
Az alábbiakban bemutatjuk a Spark parancsok különböző tippeit és trükköit: -
- A Spark kezdőjei használhatnak Spark-shell-t. Mivel a Spark parancsok a Scala-ra épülnek, ezért a scala szikrakészlet használata mindenképpen remek. A python szikrahéj ugyanakkor rendelkezésre áll, így akár valami használható is, aki jól ismeri a pythonot.
- A Spark shellnek számos lehetősége van a fürt erőforrásainak kezelésére. A Parancs alatt segíthet abban:

- A Spark esetében a hosszú adatkészletekkel való munka a szokásos. De a dolgok rosszul fordulnak el, ha rossz információt vesznek. Mindig jó ötlet a rossz sorok eldobására a Spark szűrő funkciójával. A jó bemeneti készlet nagyszerű lesz.
- A Spark saját maga választja meg a jó partíciót az Ön adataihoz. De mindig jó gyakorlat, ha a munka megkezdése előtt figyelemmel kíséri a partíciókat. A különféle partíciók kipróbálása segít a munka párhuzamosságában.
Következtetés - Spark parancsok:
A Spark parancs egy forradalmian új és sokoldalú nagy adatmotor, amely kötegelt feldolgozásra, valós idejű feldolgozásra, adatok gyorsítótárazására stb. Képes. A Spark gazdag gépi tanulási könyvtárakkal rendelkezik, amelyek lehetővé teszik az adattudósok és az elemző szervezetek számára, hogy erős, interaktív és gyors alkalmazások.
Ajánlott cikkek
Ez egy útmutató a Spark parancsokhoz. Itt megvitattuk az alapvető, valamint a fejlett Spark parancsokat és néhány azonnali Spark parancsot. A következő cikkben további információkat is megnézhet -
- Adobe Photoshop parancsok
- Fontos VBA parancsok
- Tableau parancsok
- SQL cheat sheet (parancsok, ingyenes tippek és trükkök)
- Csatlakozás típusai a Spark SQL-ben (példák)
- Szikra alkatrészek Áttekintés és a 6 legfontosabb alkotóelem