
Bevezetés a felügyelt tanulásba
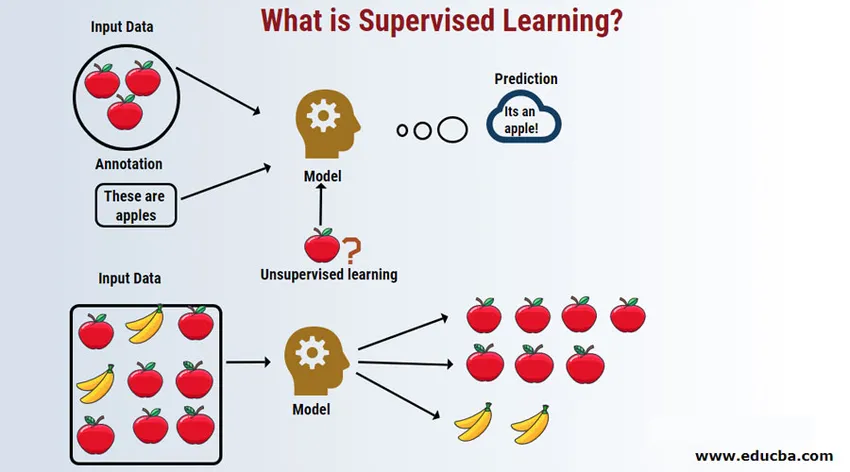
A felügyelt tanulás a gépi tanulás olyan területe, ahol az értékek előrejelzésével dolgozunk felcímkézett adatkészletek felhasználásával. A címkézett bemeneti adatkészleteket független változónak nevezzük, míg a becsült eredményeket függő változónak nevezzük, mivel az eredmények független változójától függenek. Például mindannyiunknak van spam mappája az e-mail (pl. Gmail) fiókunkban, amely automatikusan észleli az Ön számára a spam / csalás e-maileket 95% -nál nagyobb pontossággal. A felügyelt tanulási modell alapján működik, ahol van egy felcímkézett adatkészlet, amely ebben az esetben a felhasználók által megjelölt spam e-mail cím. Ezeket a képzési készleteket a tanuláshoz használják, amelyeket később felhasználnak az új e-mailek spamként való besorolására, ha az megfelel a kategóriának.
A felügyelt gépi tanuláson dolgozik
Példa segítségével megértsük a felügyelt gépi tanulást. Tegyük fel, hogy van gyümölcskosár, amely különféle gyümölcsfajtákkal van tele. Feladatunk az, hogy a gyümölcsöket kategóriájuk alapján osztályozzuk.
Esetünkben négyféle gyümölcsöt vettünk figyelembe, ezek az alma, a banán, a szőlő és a narancs.
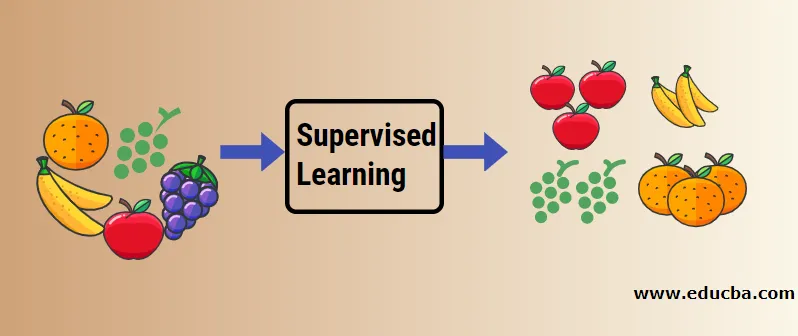
Most megpróbáljuk megemlíteni ezeknek a gyümölcsöknek a sajátos tulajdonságait, amelyek egyedivé teszik őket.
|
S Nem | Méret | Szín | Alak |
Keresztnév |
|
1 | Kicsi | Zöld | Kerek vagy ovális, csomó alakú, hengeres |
Szőlő |
|
2 | Nagy | Piros | Lekerekített alak, tetején mélyedés |
alma |
|
3 | Nagy | Sárga | Hosszú íves henger |
Banán |
| 4 | Nagy | narancssárga | Lekerekített alakú |
narancssárga |
Tegyük fel például, hogy egy gyümölcsöt felvette a gyümölcskosárból, megvizsgálta annak jellemzőit, például alakját, méretét és színét, majd azt a következtetést vonja le, hogy ennek a gyümölcsnek a színe piros, a méret, ha nagy, az alak lekerekített alakú, tetején depressziós, tehát alma.
- Hasonlóképpen, ugyanazt teheti meg az összes többi fennmaradó gyümölcs esetében is.
- A jobb szélső oszlopot („Gyümölcs neve”) válaszváltozónak nevezzük.
- Így fogalmazzuk meg a felügyelt tanulási modellt, most mindenkinek, aki új (mondjuk egy robot vagy egy idegen), megadott tulajdonságokkal, meglehetősen könnyű az azonos típusú gyümölcsök könnyű csoportosítása.
A felügyelt gépi tanulási algoritmus típusai
Lássuk különféle típusú gépi tanulási algoritmusokat:
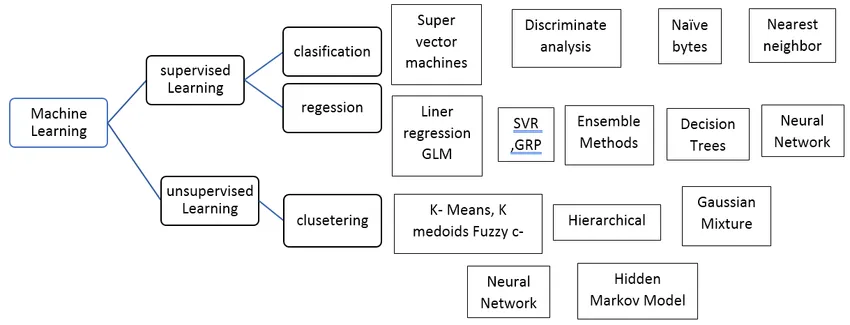
Regresszió:
A regresszió az egyértékű kimenet előrejelzésére szolgál az edzési adatkészlet felhasználásával. A kimeneti értéket mindig függõ változónak, míg a bemeneteket független változónak nevezzük. Különböző típusú regresszió van a felügyelt tanulásban, például:
- Lineáris regresszió - Itt csak egy független változó van, amelyet a kimenet előrejelzésére használunk, azaz függő változó.
- Többszörös regresszió - itt egynél több független változónk van, amelyeket a kimenet előrejelzésére használunk, azaz a függő változót.
- Polinomiális regresszió - Itt a függő és független változók közötti grafikon egy polinom függvényt követi. Például először a memória növekszik az életkorral, akkor egy bizonyos korban eléri a küszöböt, majd az öregedéskor kezd csökkenni.
Osztályozás:
A felügyelt tanulási algoritmusok osztályozását használják a hasonló objektumok egyedi osztályokba csoportosítására.
- Bináris osztályozás - Ha az algoritmus 2 különálló osztálycsoportot próbál csoportosítani, akkor azt bináris osztályozásnak nevezzük.
- Többosztályú osztályozás - Ha az algoritmus több mint 2 csoportra próbál csoportosítani az objektumokat, akkor azt többosztályú besorolásnak nevezzük.
- Erő - A besorolási algoritmusok általában nagyon jól teljesítenek.
- Hátrányok - hajlamosak a túlépítésre, és esetleg korlátozottak is lehetnek. Példa - e-mail spam osztályozó
- Logisztikus regresszió / osztályozás - Ha az Y változó bináris kategorikus (azaz 0 vagy 1), akkor a becsléshez logisztikus regressziót használunk. Példa - Annak előrejelzése, hogy egy adott hitelkártya-tranzakció csalás-e vagy sem.
- Naiv Bayes-osztályozók - A Naiv Bayes-osztályozó a Bayes-tétel alapján épül fel. Ez az algoritmus általában akkor a legmegfelelőbb, ha a bemenetek mérete nagy. Aciklikus grafikonokból áll, amelyeknek egyik szülője és sok gyermek csomópontja van. A gyermekcsomópontok függetlenek egymástól.
- Döntési fák - A döntési fa egy fa diagramszerű struktúra, amely egy belső csomópontból (tulajdonságteszt), ágból, amely a teszt eredményét jelöli, és a levélcsomókból, amely az osztályok eloszlását képviseli. A gyökér csomópont a legfelső csomópont. Ez egy nagyon széles körben alkalmazott módszer, amelyet a besoroláshoz használnak.
- Támogató vektorgép - A támogató vektorgép az SVM, vagy egy SVM végzi a besorolást azáltal, hogy megtalálja a hiper síkot, amelynek maximalizálnia kell a két osztály közötti mozgástért. Ezek az SVM gépek csatlakoztatva vannak a kernel funkciókhoz. Az SVM-eket széles körben alkalmazzák a biometria, a mintafelismerés stb.
Előnyök
Az alábbiakban bemutatjuk a felügyelt gépi tanulási modellek néhány előnyeit:
- A modellek teljesítményét a felhasználói élmények optimalizálhatják.
- A felügyelt tanulás eredményeket hoz létre a korábbi tapasztalatok felhasználásával, és lehetővé teszi az adatok gyűjtését is.
- A felügyelt gépi tanulási algoritmusok számos valós probléma megvalósításához felhasználhatók.
hátrányok
A felügyelt tanulás hátrányai a következők:
- A felügyelt gépi tanulási modellek kiképzése sok időt vehet igénybe, ha az adatkészlet nagyobb.
- A nagy adatok osztályozása néha nagyobb kihívást jelent.
- Lehet, hogy foglalkozni kell a túlfűtés problémáival.
- Sok jó példára van szükségünk, ha azt szeretnénk, hogy a modell jól működjön, amíg az osztályozót képzzük.
Jó gyakorlatok a tanulási modellek felépítése során
Ez egy jó gyakorlat egy felügyelt tanulási gépmodellek felépítésekor: -
- Bármely jó gépi tanulási modell felépítése előtt meg kell hajtani az adatok előfeldolgozásának folyamatát.
- El kell dönteni az algoritmust, amely az adott problémához legjobban megfelel.
- El kell döntenünk, hogy milyen típusú adatokat fogunk használni az edzéskészlethez.
- Döntenie kell az algoritmus és a funkció felépítéséről.
Következtetés
Cikkünkben megtanultuk, mi a felügyelt tanulás, és láttuk, hogy itt a modellt jelölt adatok felhasználásával képzzük. Aztán megvizsgáltuk a modellek és azok különféle típusainak működését. Végül megláttuk ezen felügyelt gépi tanulási algoritmusok előnyeit és hátrányait.
Ajánlott cikkek
Ez egy útmutató arra, hogy mi a felügyelt tanulás ?. Itt tárgyaljuk a felügyelt tanulás fogalmait, működését, típusait, előnyeit és hátrányait. A további javasolt cikkeken keresztül további információkat is megtudhat -
- Mi az a mély tanulás?
- Felügyelt tanulás vs mély tanulás
- Mi a szinkronizálás a Java-ban?
- Mi az a webtárhely?
- Előnyökkel járó döntési fa létrehozásának módjai
- Polinomiális regresszió | Felhasználások és szolgáltatások