

Bevezetés a döntési fához az adatbányászatban
A mai világban a „nagy adat” kifejezésen az „adatbányászat” kifejezés azt jelenti, hogy nagy adatkészleteket kell beolvasnunk és az adatok „bányászatát” végeznünk, és ki kell hoznunk annak fontos léjét vagy lényegét, amit az adatok mondani akarnak. Nagyon hasonló helyzet a szénbányászat helyzete, ahol különféle szerszámokra van szükség a mélyen a föld alá eltemetett szén bányászatához. Az adatbányászatban alkalmazott eszközök közül a „Döntési fa” az egyik. Tehát az adatbányászat önmagában egy hatalmas terület, ahol a következő néhány bekezdésben mélyebben belemerülünk az Adatbányászat döntésfa „eszközébe”.
Az adatbányászat döntési fajának algoritmusa
A döntési fa egy felügyelt tanulási megközelítés, amelyben a jelen lévő adatokat kiképezzük azzal, hogy már tudjuk, mi a célváltozó valójában. Ahogy a neve is sugallja, ennek az algoritmusnak fafajta felépítése van. Vizsgáljuk meg először a döntési fa elméleti aspektusát, majd ezt grafikus megközelítésben. A Döntési fa esetében az algoritmus az adatkészletet részhalmazokra osztja a legfontosabb vagy legfontosabb tulajdonság alapján. A legfontosabb attribútumot a gyökér csomópontban jelölik, és itt szétválasztják a gyökér csomópontban található teljes adatkészletet. Ezt a megosztást döntési csomópontoknak nevezzük. Ha nem lehetséges több split, akkor a csomópontot levélcsomópontnak nevezik.
Annak érdekében, hogy az algoritmus megálljon egy túlnyomó szakaszba, megállási kritériumot alkalmazunk. Az egyik leállási kritérium a megfigyelések minimális száma a csomópontban, mielőtt a felosztás megtörténik. Az adatkészlet felosztásakor a döntési fa alkalmazásakor ügyelnie kell arra, hogy sok csomópontnak csak zajos adatai legyenek. Annak érdekében, hogy elkerüljük az idegen vagy zajos adatproblémákat, az Data Pruning néven ismert technikákat alkalmazunk. Az adatmetszés nem más, mint egy algoritmus az alcsoportból származó adatok osztályozására, ami megnehezíti a tanulást egy adott modelltől.
J. Ross Quinlan gépi kutató kiadta a döntési fa algoritmust ID3 (Iterative Dichotomiser) néven. Később a C4.5 kiadták az ID3 utódjaként. Az ID3 és a C4.5 mohó megközelítés. Most vizsgáljuk meg a Döntési fa algoritmus folyamatábráját.
Pszeudokód-megértésünk érdekében „n” adatpontot veszünk, amelyek mindegyike „k” attribútummal rendelkezik. A folyamatábra alatt az „Információ-nyereség”, mint a felosztás feltétele feltétele, hogy kerüljön sor.
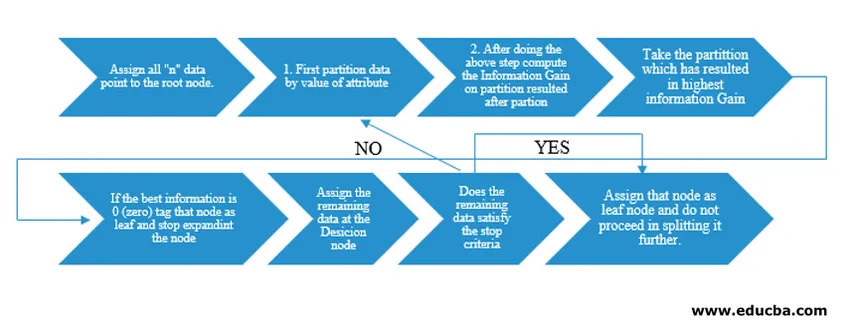
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Az információszerzés (IG) helyett a felosztás kritériumaként a Gini-indexet is alkalmazhatjuk. Ahhoz, hogy megértsük a két kritérium közötti különbséget laikus fogalmakban, gondolhatunk erre az információ-nyereségre mint az Entrópia különbségre a felosztás előtt és a felosztás után (minden rendelkezésre álló tulajdonság alapján felosztva).
Az entrópia olyan, mint a véletlenszerűség, és a felosztás után egy pontot érnénk el, hogy a legkevesebb véletlenszerűség legyen. Ezért az információszerzésnek a lehető legjobban annak a tulajdonságnak kell lennie, amelyet meg akarunk osztani. Máskülönben ha a Gini Index alapján osztani szeretnénk, akkor a különbözõ attribútumokhoz a Gini-indexet találjuk, és ugyanazzal a segítségével különbözõ megoszlásokra derítjük ki a súlyozott Gini-indexet, és az adatkészlet felosztásához a magasabb Gini-indexet használjuk.
A döntési fa fontos feltételei az adatbányászatban
Az alábbiakban bemutatjuk az adat bányászatban a döntési fa néhány fontos fogalmát:
- Gyökér csomópont: Ez az első csomópont, ahol a felosztás megtörténik.
- Levélcsomópont: Ez a csomópont, amely után nincs több elágazás.
- Döntési csomópont: Az a csomópont, amely az előző csomópont adatainak felosztása után jött létre, döntési csomópont.
- Ágazat: Egy fa azon szekciója, amely információkat tartalmaz a döntési csomópontban a megosztottság következményeiről.
- Metszés: Ha egy döntési csomópont al-csomópontjait eltávolítják, hogy kiszélesedjenek vagy zajosak legyenek, akkor metszésnek nevezzük. Azt is gondolják, hogy ellentétes az osztással.
A döntési fa alkalmazása az adatbányászatban
A Döntési fa folyamatábra típusú architektúrát tartalmaz, beépítve az algoritmus típusához. Alapvetően egy „Ha X, akkor Y egyébként Z” típusú mintázattal rendelkezik, amíg a felosztás megtörténik. Az ilyen típusú mintákat használják az emberi intuíció megértésére a programozási területen. Ezért széles körben felhasználható különféle kategorizálási problémákra.
- Ez az algoritmus széles körben alkalmazható azon a területen, ahol a célfüggvény kapcsolódik az elvégzett elemzéshez.
- Ha számos cselekvési út áll rendelkezésre.
- Külső elemzés.
- A teljes adatkészlet jelentős tulajdonságainak megértése és a néhány adat vonása „a bányászathoz” a nagy adatban szereplő, több száz jellemzők listájából.
- A legjobb repülési út kiválasztása az úticélhoz való utazáshoz.
- Különböző körülményi helyzeteken alapuló döntéshozatali folyamat.
- Churn elemzés.
- Érzelmi elemzés.
A döntési fa előnyei
Az alábbiakban bemutatjuk a döntési fa néhány előnyeit:
- Könnyű megértés: A döntési fa ábrázolása a grafikus formáiban megkönnyíti a megértést a nem elemző háttérrel rendelkező személyek számára. Különösen azokban a vezetői emberekben, akik meg akarják nézni, mely tulajdonságok fontosak, csak a döntési fára pillantva hozhatják fel hipotézisüket.
- Adatkutatás: Amint azt már említettük, a jelentős változók beszerzése a döntési fa alapvető funkciója, és ugyanazon felhasználásával az adatkutatás során kitalálható annak eldöntése, melyik változóra lenne szükség különös figyelmet az adatbányászás és a modellezés szakaszában.
- Az adatkészítés szakaszában nagyon kevés az emberi beavatkozás, és az adatok során felhasznált idő eredményeként a tisztítás csökken.
- A Döntési fa képes kezelni mind kategorikus, mind numerikus változókat, és képes kezelni a többosztályú osztályozási problémákat is.
- A feltevés részeként a döntési fák nem feltételezik a térbeli eloszlást és az osztályozó struktúrát.
Következtetés
Végezetül, a döntéshozatali fák a nemlinearitás egy teljesen más osztályát vezetik be, és a nemlinearitással kapcsolatos problémák megoldására szolgálnak. Ez az algoritmus a legjobb választás az emberek döntési szintű gondolkodásának utánozására és matematikai-grafikus ábrázolására. Felülről lefelé építkező megközelítést alkalmaz az új, láthatatlan adatok alapján történő eredmények meghatározásakor, és követi a felosztás és meghódítás elvét.
Ajánlott cikkek
Ez egy útmutató az Adatbányászat döntési fajához. Itt tárgyaljuk a döntési fa algoritmusát, fontosságát és alkalmazását az adatbányászatban, annak előnyeivel együtt. A következő cikkeket is megnézheti további információkért -
- Adattudományi gépi tanulás
- Az adatelemzési technikák típusai
- Döntési fa R
- Mi az adatbányászat?
- Útmutató az adatok elemzésének különféle módszereire