

Különbség a Hadoop és a HBase között
A Hadoop egy nyílt forráskódú Java keretrendszer, amelyet hatalmas mennyiségű strukturált és nem strukturált adat kezelésére és feldolgozására használnak. A Hadoop nagymértékben méretezhető, ezért nagy adatterhelések feldolgozására használják. A nagy adatok tárolása, elérése és feldolgozása a megbízható és bővíthető fürtön történik. A HBase (Hadoop Database) nem relációs és nem csak SQL, azaz NoSQL adatbázis, amely a Hadoop tetején fut, mint elosztott és méretezhető nagy adattároló. Ez egy nyílt forrású adatbázis, amelyben az adatokat sorok és oszlopok formájában tárolják, abban a cellában az oszlopok és a sorok metszéspontja.
Az alábbiakban bemutatjuk a Hadoop építészet fő alkotóelemeit:
- Hadoop elosztott fájlrendszer (HDFS): A Hadoop elosztott tárolórendszert, a Hadoop elosztott fájlrendszert (HDFS) tartalmaz. A HDFS a master-slave architektúra, amely adatokat tárol a fürtön keresztül. Az űrlapblokkban a fő csomópont által több szolga csomóponton elosztott adatok. A mester csomópont Namenode, a szolga csomópontok pedig Datanode. A HDFS könnyen bővíthető, és hatalmas mennyiségű adatot tárol a Datanodes-on. A HDFS konfigurálható replikációs tényezőjével rendelkezik, amelynek alapértelmezett értéke 3, amely szerkeszthető.
- MapReduce: A MapReduce egy olyan programozási paradigma, amely párhuzamosan hatalmas számú adatkészlettel működik a hálózaton keresztül. A MapReduce két különféle feladatra vonatkozik: leképezi azokat a bemeneti adatokat, amelyekben az adatok részhalmazainak felosztva, tuplumoknak és csökkentő feladatoknak vannak kitéve a térképből, mint bemenetek, és összekapcsolva képezik az eredeti kimenetet.
- Fonal: A YARN egy újabb erőforrás-navigátort jelent, amely olyan erőforrásokat számít, mint például a CPU és a memória kezelése, az erőforrás-kérelmek ütemezése.
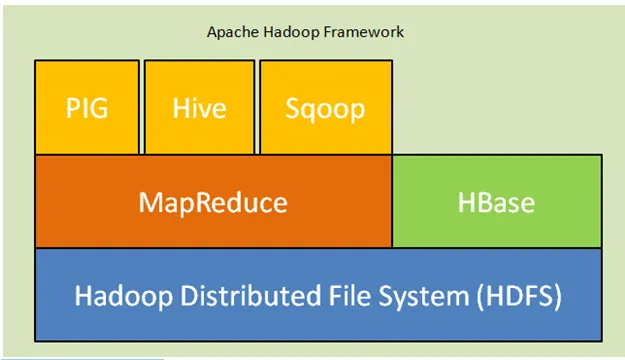
Ábra: Apache Hadoop keretrendszer
A regionális kiszolgáló adatokat szolgáltat az olvasási / írási műveletekhez. Az összes HBase adatot a HDFS fájl tárolja. A HDFS Datanode tárolja azokat az adatokat, amelyeket a Régiószerver kezeli. A HDFS Namenode a fájlokat tartalmazó összes fizikai adatblokk metaadatát tárolja.
A verziózás a cellák változásának nyomon követésére szolgál, amely a tartalom verziójának nyomon követését szolgálja. Ettől a tartalom bármely verziója lehívható. Minden cellaérték tartalmazza a 'version' attribútumot a cella lekérdezéséhez szükséges időbélyeghez viszonyítva. A térkép minden egyes értéke megszakítás nélküli byte-tömb. A térképet egy sor-, oszlop- és időbélyegző indexeli. A HBase architektúrája erősen skálázható, ritka, elosztott, perzisztens és többdimenziós módon rendezett térképek.
Összehasonlítás a Hadoop és a HBase között (Infographics)
Az alábbiakban bemutatjuk a 7 legfontosabb különbséget a Hadoop és a HBase között
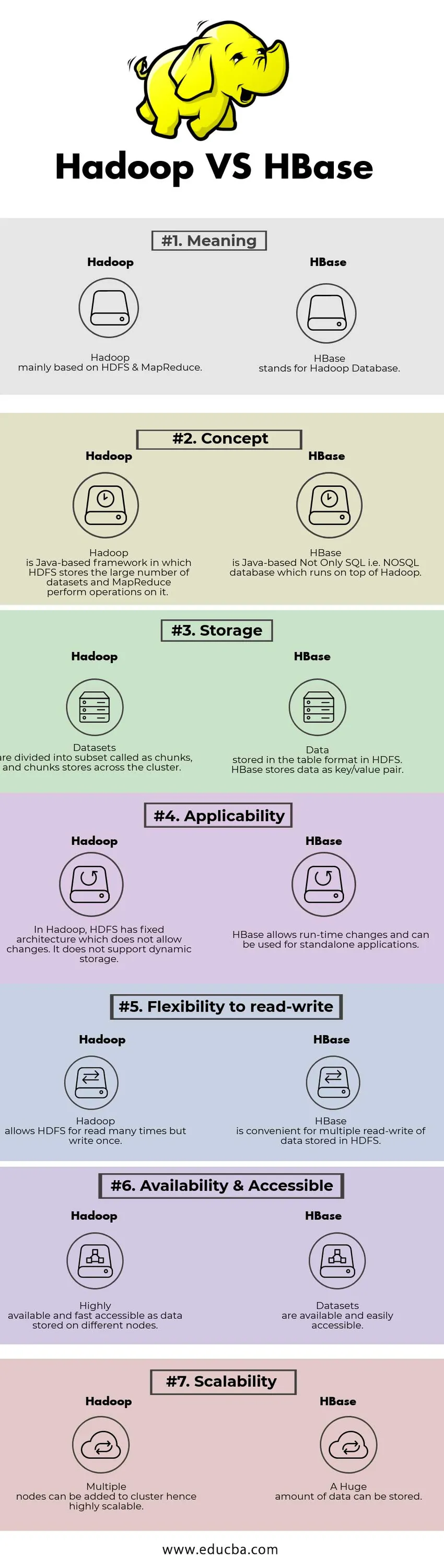
Főbb különbségek a Hadoop és a HBase között
A Hadoop és a HBase közötti különbséget az alábbiakban ismertetjük:
- A Hadoop nem alkalmas online analitikai feldolgozásra (OLAP), a HBase pedig a Hadoop ökoszisztéma része, amely véletlenszerű valós idejű hozzáférést (olvasást / írást) biztosít a Hadoop fájlrendszer adataihoz.
- A Hadoop keret kialakítása hibatűrő, és támogatja a csomópontok közötti gyors adatátvitelt még rendszerhibák esetén is. A HBase egy nem relációs és nyílt forrású, nem csak SQL adatbázis, amely a Hadoop tetején fut. A HBase a CAP típusú CAP (konzisztencia, rendelkezésre állás és partíciós tolerancia) tétel alá tartozik.
- A Hadoop a legalkalmasabb kötegelt elemzés elvégzésére. Az egyik legnagyobb hátránya azonban, hogy képtelen valós idejű elemzést végezni, az informatikai ipar trendjének követelménye. A HBase viszont nagy adatkészleteket képes kezelni, és nem megfelelő a kötegelt elemzésekhez. Ehelyett adatainak valós időben történő írására / olvasására használják.
- Mind a Hadoop, mind a HBase képesek strukturált, félig strukturált és strukturálatlan adatok feldolgozására. A Hadoopban a HDFS-nek nincs egy memóriában dolgozó feldolgozó motorja, amely lelassítja az adatelemzés folyamatát; mivel egy egyszerű régi MapReduce-t használ erre. A HBase éppen ellenkezőleg, büszkélkedhet egy memóriában lévő feldolgozó motorral, amely drasztikusan növeli az olvasás / írás sebességét.
- A Hadoop az adatelemzés végrehajtása során nagyon átlátható. A HBase viszont, mivel NoSQL adatbázis táblázatos formátumban, az értékeket különféle kulcsértékek szerinti osztályozással hozza le.
Hadoop vs HBase összehasonlító táblázat
| AZ ÖSSZEHASONLÍTÁSI ALAP | Hadoop | HBase |
| Jelentés | A Hadoop elsősorban a HDFS & MapReduce alapú. | A HBase a Hadoop Database kifejezést jelenti. |
| Koncepció | A Hadoop egy Java alapú keret, amelyben a HDFS tárolja a nagy számú adatkészletet, és a MapReduce műveleteket hajt végre rajta. | A HBase Java alapú nem csak SQL, azaz NoSQL adatbázis, amely a Hadoop tetején fut. |
| Tárolás | Az adatkészleteket részekre osztják, és darabokat tárolnak a fürtön keresztül. | A táblázat formátumában tárolt adatok HDFS-ben. A HBase az adatokat kulcs / érték párként tárolja. |
| Alkalmazhatóság | A Hadoopban a HDFS rögzített architektúrájú, amely nem engedélyezi a változtatásokat. Nem támogatja a dinamikus tárolást. | A HBase lehetővé teszi a futásidejű változtatásokat, és önálló alkalmazásokhoz használható. |
| Rugalmasság az írás-olvasás szempontjából | A Hadoop lehetővé teszi a HDFS számára, hogy többször olvassa el, de egyszer írjon. | A HBase kényelmes a HDFS-ben tárolt adatok többszörös olvasására és írására |
| Rendelkezésre állás és hozzáférhetőség | Nagyon elérhető és gyorsan elérhető, mint a különféle csomópontokon tárolt adatok. | Az adatkészletek rendelkezésre állnak és könnyen elérhetők |
| skálázhatóság | Több csomópont hozzáadható a klaszterhez, tehát nagyon skálázható. | Óriási mennyiségű adat tárolható. |
Következtetés - Hadoop vs HBase
A Hadoop architektúrája elsősorban HDFS és MapReduce alapú. A HBase a Hadoop rendszer támogató alkotóeleme. A HBase képes hatalmas táblákat tárolni és gyors véletlenszerű hozzáférést biztosít a rendelkezésre álló adatokhoz, míg a HDFS nagy fájlok tárolására alkalmas. Mind a Hadoop, mind a HBase gyors hozzáférést biztosít az adatokhoz, de a HBase olvasási / írási műveletekkel elvégezhető, a HDFS esetén pedig többször és egyszer is olvasható. Ez a cikk a Hadoop és a HBase megértését ismertette, röviden bemutatta a funkciókat és bölcsen hasonlította össze.
Ajánlott cikk
- Apache Hadoop vs Apache Spark | A tíz legjobb összehasonlítás, amit tudnod kell!
- Hadoop vs Hive - derítse ki a legjobb különbségeket
- HBase vs Cassandra - melyik a jobb (infographics)
- Az Apache Hive és az Apache HBase 12 legfontosabb összehasonlítása (Infographics)
- Hadoop vs Spark: Melyek a funkciók