

Bevezetés az Apache Flume-ba
Az Apache Flume Data Ingestion Framework, amely eseményalapú adatokat ír a Hadoop Distributed File System rendszerbe. Ismert tény, hogy a Hadoop feldolgozza a nagy adatokat, felmerül a kérdés, hogyan továbbítják a különböző webszerverekből előállított adatokat a Hadoop fájlrendszerbe? A válasz: Apache Flume. A Flume-t úgy tervezték, hogy az eseményalapú adatok nagy mennyiségű adatot nyerjenek a Hadoop-ba.
Vegyünk egy olyan helyzetet, amelyben a webkiszolgálók száma naplófájlokat generál, és ezeket a naplófájlokat továbbítani kell a Hadoop fájlrendszerbe. A Flume eseményekként gyűjti ezeket a fájlokat és behúzza azokat a Hadoopba. Noha a Flume-t továbbítják a Hadoop-ra, nincs szigorú szabály, hogy a rendeltetési helynek Hadoop-nak kell lennie. A Flume képes más keretekre, például Hbase vagy Solr.
Flume építészet
Az Apache Flume architektúrája általában a következő komponensekből áll:
- Flume Source
- Flume Channel
- Flume mosogató
- Flume Agent
- Flume esemény
Vessen egy rövid pillantást az egyes Flume komponensekre
1. Füstforrás
Az Flume Source jelen van az adatgenerátorokban, például a Face book vagy a Twitter. A Source adatokat gyűjt a generátorról, és ezeket továbbítja a Flume Channel számára Flume Events formájában. A Flume támogatja a különféle típusú forrásokat, például az Avro Flume Source - csatlakozik az Avro porton és fogad eseményeket az Avro külső ügyféltől, a Thrift Flume Source - csatlakozik a Thrift porton, és eseményeket fogad a külső Thrift kliens adatfolyamokból, a Spooling Directory Source és a Kafka Flume Sourceból.
2. Flume Channel
Az a közbenső áruház, amely a Flume Source által küldött eseményeket puffereli, amíg azokat a Sink el nem fogyasztja, Flume Channel néven hívják. A csatorna közbenső hídként működik a Source és a Sink között. A Flume csatornák tranzakciós jellegűek.
A Flume támogatja a File és a Memória csatornákat. A fájlcsatorna tartós jellegű, azaz azt követően, hogy az adatokat a csatornára írják, nem fog elveszni, bár ha az ügynök újraindul. A memóriában a csatornaesemények a memóriában vannak tárolva, tehát nem tartós, de nagyon gyors természetű.
3. Flume mosogató
Flume mosogató van jelen az adattárakban, mint például a HDFS, a HBase. A Flume mosogató eseményeket fogyaszt a Csatorna helyéről, és azokat a Destination áruházakba tárolja, mint például a HDFS. Nincs olyan szabály, hogy a mosogatónak eseményeket kell szállítania a Store-hoz, ehelyett úgy konfigurálhatjuk, hogy a mosogató eseményeket továbbítson egy másik ügynöknek. A Flume különféle mosogatókat támogat, mint például a HDFS mosogató, a kaptár mosogatója, a takarékos mosogató, az Avro mosogató.
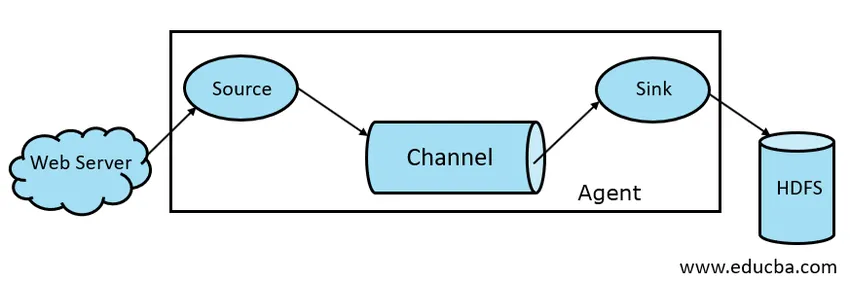
1.1 ábra: Alapvető füstölő architektúra
4. Flume Agent
A Flume ügynök egy hosszú ideje futó Java folyamat, amely a Forrás - Csatorna - Mosogató kombinációján fut. A flumnak lehet egynél több ágense. A Flume-t összekapcsolt Flume-ágensek gyűjteményének tekinthetjük, amelyek a természetben eloszlanak.
5. Flume esemény
Az esemény a Flume-ban továbbított adat egység . Az Flume-ban lévő Data Object általános megjelenítését eseménynek nevezzük. Az esemény egy byte-tömb hasznos teheréből áll, opcionális fejlécekkel.
A Flume működése
A Flume ágens egy java folyamat, amely Source - Channel - Sink-ből áll a legegyszerűbb formájában. A Source adatgyűjtőből események formájában gyűjti az adatokat és továbbítja azokat a csatornához. A forrás követelmény szerint több csatornára is szállíthat. A ventilátor az a folyamat, amelyben egyetlen forrás több csatornára ír, így több mosdóra továbbíthatja azokat.
Az esemény az Flume-ban továbbított adatok alapegysége. A csatorna addig puffereli az adatokat, amíg a Sink el nem fogyasztja azokat. A Sink összegyűjti az adatokat a csatornáról, és továbbítja azokat a központosított adattárolásra, például a HDFS vagy a Sink igénye szerint továbbíthatja ezeket az eseményeket egy másik Flume ügynöknek.
A Flume támogatja a tranzakciókat. A megbízhatóság elérése érdekében a Flume külön tranzakciókat alkalmaz a forrástól a csatornáig és a csatornától a mosogatóig. Ha az eseményeket nem kézbesítik, akkor a tranzakció visszakerül és később továbbadásra kerül.
A Flume működésének megértése érdekében vegyünk egy példát a Flume konfigurációjára, ahol a forrás spool könyvtár, a sink pedig Hdfs. Ebben a példában a Flume ügynök a legegyszerűbb formában van, azaz egyetlen forrás - csatorna - sink topológiában, amelyet egy java tulajdonságfájl segítségével konfigurálnak.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
A fenti konfigurációs példában az agent az az alap, amellyel meghatározhatunk más tulajdonságokat. Az Source1, valamint a Sink1 és a channel1 a forrás, a mosogató és a csatorna neve, és típusukat és helyüket szintén meg kell említeni.
Az Apache Flume előnyei
- A füst méretezhető, megbízható és hibatűrő jellegű. Ezeket a tulajdonságokat az alábbiakban tárgyaljuk részletesen
- Skálázható - A Flume vízszintesen méretezhető, azaz új csomópontokat felvehetünk igényeink szerint
- Megbízható - az Apache Flume támogatja a tranzakciókat, és biztosítja, hogy az adatátvitel során ne veszítsen el adat. Különböző tranzakciók vannak forrásról csatornara és csatornáról forrásra.
- A Flume testreszabható, és támogatást nyújt különféle forrásokhoz és mosogatókhoz, például Kafka, Avro, orsózó könyvtár, Thrift stb.
- A Flume esetében az egyetlen forrás adatot továbbíthat több csatornára, és ezek a csatornák viszont továbbítják az adatokat több csatornába, tehát az egyetlen forrás több adatot továbbíthat több csatornára. Ezt a mechanizmust Fan out-nek hívják. A Flume a Fan Out támogatását is támogatja.
- A Flume biztosítja az adatátvitel folyamatos folyamatát, azaz ha az adatolvasási sebesség növekszik, és az adatírás sebessége szintén növekszik.
- Noha a Flume általában adatokat tárol centralizált tárolóhelyre, például HDFS vagy Hbase, a Flume-ot úgy állíthatjuk be, hogy követelményünk szerint oly módon készítsen adatokat, hogy a Sink más ügynökökre írjon adatokat. Ez megmutatja a Flume rugalmasságát
- Az Apache Flume nyílt forrású természetű.
Következtetés
Ebben a Flume cikkben részletesen tárgyaljuk a Flume összetevőit és a Flume működését. A Flume rugalmas, megbízható és méretezhető platform az adatok továbbítására egy olyan központi tárolóba, mint a HDFS. Az a képesség, hogy integrálódjon különféle alkalmazásokba, például a Kafka, a Hdfs, a Thrift, lehetővé teszi az adatgyűjtés életképes lehetőségét.
Ajánlott cikkek
Ez egy útmutató az Apache Flume-hoz. Itt az Apache Flume építészetét, működését és előnyeit tárgyaljuk. Lehet, hogy megnézi a következő cikkeket is, ha többet szeretne megtudni -
- Mi az Apache Flink?
- Különbség az Apache Kafka és a Flume között
- Big Data architektúra
- Hadoop eszközök
- Ismerje meg a különböző JavaScript eseményeket